AMD Clarifies "Best Cores" vs "Preferred Cores" Discrepancies For Ryzen CPUs
by Andrei Frumusanu on November 21, 2019 9:00 AM EST
Over the last several weeks there’s been increasing discussions in the AMD enthusiast community about how the company’s new Ryzen 3000 processors interact with Windows, and in particular on how the new CPUs’ boost behaviour behaves in relation to a discrepancy between what tools such as Ryzen Master showcase as the best CPU cores, and what operating systems such as Windows interpret as being the best CPU cores. Today AMD is officially commenting on the situation and why it arises, whilst also describing what they’re doing to remedy the discrepancies in the data.
AMD’s Ryzen 3000 processor line-up based on the new Zen2 microarchitecture differs greatly in terms of frequency behaviour compared to past products. The new chips are AMD’s first products to make use of an ACPI feature called CPPC2 (Collaborative Power and Performance Control 2) which is an API interface between the chip’s firmware (Essentially the UEFI BIOS and AGESA) and an operating system such as Windows. The interface allows for the hardware to better communicate its frequency and power management characteristics and configurations to the OS, such that the OS’s software DVFS and scheduler are able to more optimally operate within the capabilities of the hardware.
AMD particularly uses the CPPC2 interface to communicate to the operating system the notion of “preferred cores”, which in essence are the CPU cores that under normal operation will be achieving the highest boost frequencies.
The issue at hand is that AMD also communicates another set of data via its own “Ryzen Master” tools and proprietary APIs, and it’s the relationship between these “best cores” and CPPC2’s “preferred cores” that caused for a bit of confusion ever since the original July launch.
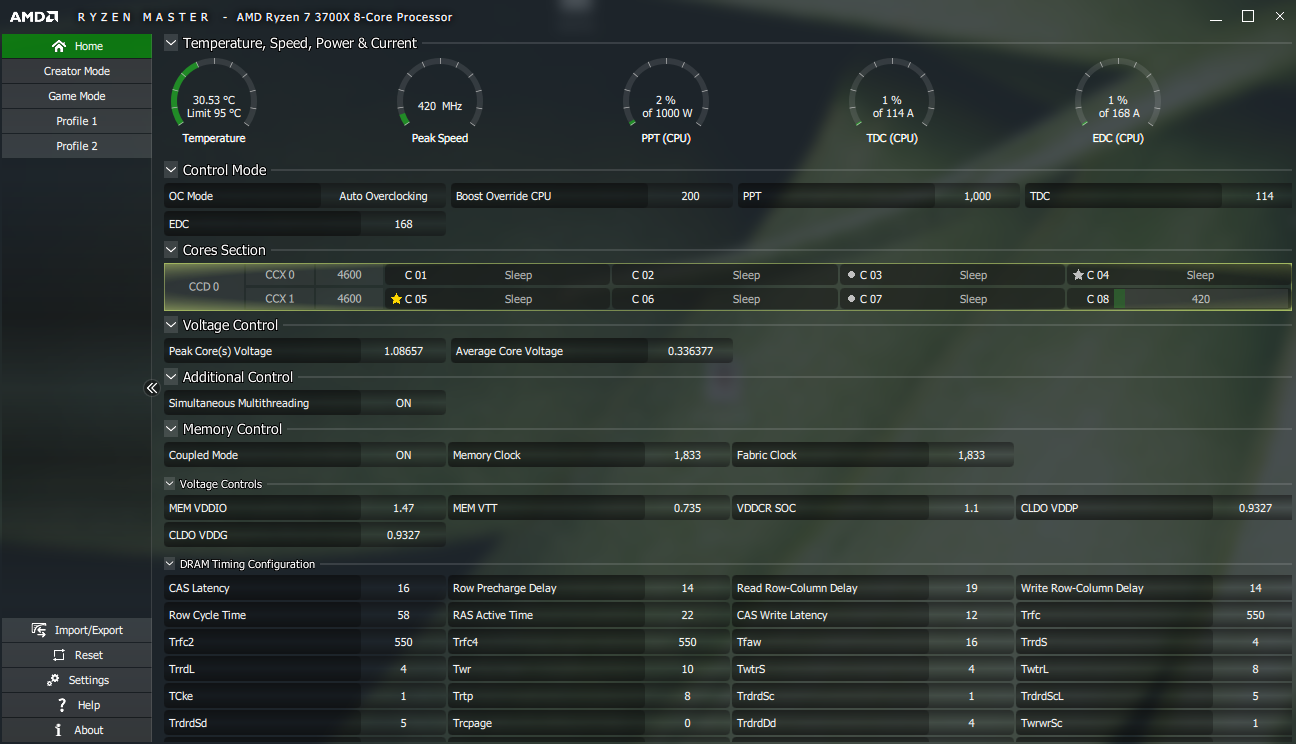
AMD’s Ryzen Master overclocking application has had the unique characteristic that it was able to showcase to the user the “best cores” in a given processor. This was done by the means of a “star” and “dot” marking in the core status UI in the app – in the above example in my system, Ryzen master marks the best CPU core within a CCX with a star, and the second-best core with a dot. Furthermore, the best CPU cores in the whole processor is marked with a gold star.
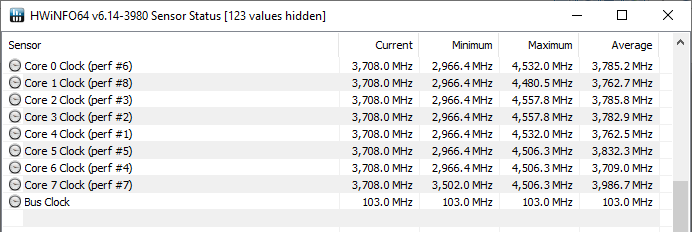
Since the original launch, and AMD’s release of their SDK to allow third-party developers to poll data from AMD’s proprietary AGESA API for more detailed core information, we’ve also seen also other third-party tools such as HWInfo being able to showcase the ranking of the “best cores” in a processor. The information here essentially matches what Ryzen Master currently displays.
The Discrepancy Between Ryzen Master / SMU Data And CPPC2
The discrepancy that’s been discussed by the community in recent weeks, and that’s been prevalent since the launch of the Ryzen 3000 series in July, is that in the majority of situations and setups, the actual CPU cores that are being loaded in the operating system under single-threaded or lightly threaded workloads mostly never matched the best CPU cores as reported by Ryzen Master. This can be seen with any generic monitoring utility such as the task manager.
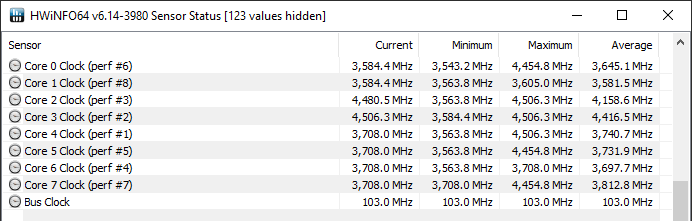
Single-Threaded Load - Note Average Frequency Load on Core 2 & 3 Instead of "Best Core" 4
The discrepancy here lies in the actual mapping between the “best cores” information in Ryzen Master and the SMU APIs, and the “preferred cores” mapping that AMD’s firmware communicates via CPPC2 to the operating system.

The easiest way to actually view the configuration settings that CPPC2 communicates to Windows is to view the corresponding “Kernel-Processor-Power” System Windows Logs entries in the Windows Event Viewer, as depicted above in the screenshot.
If we were to take my own system as an example, showcasing my 3700X’s data reported across both CPPC2 and the Ryzen Master / SMU API, we see the following layout:
| Andrei's 3700X Example | |||
| Core # |
CPPC2 Data / Ranking |
Ryzen Master |
SMU Data / API Ranking |
| 0 | 148 / #3 | #6 | |
| 1 | 144 / #4 | #8 | |
| 2 | 151 / #1/2 | Dot | #3 |
| 3 | 151 / #1/2 | Star | #2 |
| 4 | 140 / #5 | Gold Star | #1 |
| 5 | 136 / #6 | #5 | |
| 6 | 132 / #7 | Dot | #4 |
| 7 | 128 / #8 | #7 | |
What AMD does here is to kind of abuse the CPPC2 per-core maximum frequency entries in order to achieve a hierarchy in the CPUs, ordering them from the preferred capable cores to the least preferred ones by altering their reported maximum frequency capability. The actual metric here is an arbitrary scale of frequency percentages above the base clock of the CPU. AMD explains that the scale and ratio here are also arbitrary (in fixed 3% steps) and does not correspond to the actual frequency differences between the CPU cores, it is just used as a representation of the ordering of the CPUs.
The oddity here is that there’s a discrepancy between CPPC2 and Ryzen Master data. For example, even though RM showcases that core 4 on my system is the best one, it’s only ranked as #5 in the CPPC2 data. The ranking order of the CPPC2 data in fact better corresponds to what we’re actually seeing in actual workloads on the operating system, which shouldn’t be too big a surprise as this is the basis on which the OS makes scheduling decisions.
The Clarification Between Ryzen Master "Best Cores" and CPPC2 "Preferred Cores"
To start off, the whole situation can be summed up with the following quote from AMD’s blog post today:
“This [Ryzen Master] star does NOT necessarily mean it is the fastest booster”
AMD goes on to clarify that there’s only a very loose relationship between what Ryzen Master showcases as the “best cores”, and what the AGESA firmware decides is the “preferred cores” that are communicated to the operating system.
The “best cores” as defined by Ryzen Master corresponds to the electrical characteristics of the cores which are determined during the binning and testing phase of the chips at the factory. The physical and electrical characteristic data is fused on each chip, and is interpreted by the SMU firmware to create the ranking between the cores independent of other factors, and this ranking is what’s currently being reported by Ryzen Master as well as third-party application readouts out through the custom API.
The ranking of the “preferred cores” as characterized by CPPC2 does not directly correspond to the electrical characteristics of the cores, and further takes into account many other factors of the chip layout. The biggest factor at hand here that affects the choice of the highest performing preferred cores in the system, is that AMD is aiming to accommodate Windows’ scheduler core rotation policy.
Currently when there’s a single large CPU thread workload running, the Windows scheduler tries to rotate this thread between a pair of physical CPU cores. The rationale for this is thermal management, as switching between two cores would distribute the latent heat dissipation between the cores and reduce the average temperature of each core, possibly also improving power draw and maximum achievable frequencies.
For AMD’s CCX topology, this rotation policy however poses an issue as it wouldn’t be very optimal for a thread to switch between CPU cores which are located on different clusters, as there would be a large performance penalty when migrating across the two cores on different L3 caches. Taking this hardware limitation into account, AMD’s firmware “lies” about the CPPC2 data to the OS in order to better optimize the schedulers behavior and attempting to achieve better overall performance.
In my example above, the AGESA reports to the OS that core 2 and 3 are the fastest in the system, even though core number 4 is electrically/physically the fastest core. The choice here by the firmware is done by selecting the highest average frequency achieved by two cores within a CCX. In my case, this would correspond to cores 2 and 3, which are electrically ranked as #2 and #3.
While AMD’s explanation currently does map out for the two fastest cores in the system, the actual ranking in the CPPC2 data is furthermore impacted by other aspects. Again, in my system example above, we can see that even though electrically cores 0 and 1 are quite bad, with core 1 actually being the worst in the system, they’re still ranked in CPPC2 as being faster than all the cores in the second CCX. The reasoning for this is that again AMD is sort of abusing the CPPC2 frequency characterization data in order to force the Windows scheduler to first fill out CPU cores on the first CCX before having activity scheduled on the second CCX.
To complicate things even further, there’s other invisible factors at hand that impact the CPPC2 ordering. Taking my system as an example again, it doesn’t quite make sense for CPU core 5 to be ranked higher than core 6, as the electrical characteristics of the cores are in fact being described as being the opposite way around.
I had a theory that the firmware would possibly prevent the ranking of cores to be sequential to each other if the corresponding physical cores would be adjacent to each other. Indeed, AMD confirms that local thermal management is also part of the decision making of the CPPC2 ranking:
"[The firmware] mixes in additional requirements to optimize user performance: individual core characteristics, overall CCX performance, cache awareness, overall CPU topology, core rotation, localized thermal management, lightly-threaded performance counters and more."
The Direcrepancy "Remedy" And Conclusion - A Compromise
AMD’s official stance on the Ryzen Master discrepancy is the following:
“Ryzen Master, using [the same] firmware readings, selects the single best voltage/frequency curve in the entire processor from the perspective of overclocking. When you see the gold star, it means that is the one core with the best overclocking potential. As we explained during the launch of 2nd Gen Ryzen, we thought that this could be useful for people trying for frequency records on Ryzen.”
“Overall, it’s clear that the OS-Hardware relationship is getting more complex every day. In 2018, we imagined that the starred cores would be useful for extreme overclockers. In 2019, we see that this is simply being conflated with a much more sophisticated set of OS decisions, and there’s not enough room for nuance and context to make that clear. That’s why we’re going to bring Ryzen Master inline with what the OS is doing so everything is visibly in agreement, and the system continues along as-designed with peak performance.”
In essence, AMD will be changing the display in Ryzen Master from showing the “best cores” – as in the best electrically performing ones, to the actual “preferred cores” as declared in CPPC2 and decided by the firmware after taking the more complex factors into consideration.
The current system sort of makes sense given the current Windows scheduler behavior. The issue I see is that currently the Windows scheduler is still relatively stupid – for example instead of spreading around processes across CCXs, it will still try to first group them onto a CCX before starting up the second CCX. Grouping makes sense in terms of threads of a single process, but different processes could be and should be spread across more CCXs in order to maximize per-CCX performance.
There remain some other issues – for example the current configuration even though there would be CPU cores in a secondary CCX that would be capable of higher frequencies, they never see these being achieved as the scheduler will use the "preferred" CCX first, and when processes and threads start to spill over to the next CCX, the requested DVFS frequency will always be lower. On my system I noted a 50MHz margin just left on the table just because of this.
There’s also the question of how this affects Linux users. Linux doesn’t have a core rotation policy in its default scheduler behavior, and it does very well in terms of scheduling across more complex CPU topologies, so in essence AMD's firmware “lying” about the core performance ranking here will possibly slightly impact peak achievable performance by a few MHz.
Generally I recommend ignoring Ryzen Master as a monitoring tool as its display abstractions of frequency and voltage just do not correspond to the actual physical characteristics of the hardware. I also hope that in the future Microsoft will be able to further improve the Windows scheduler to better deal with more complex CPU topologies such as AMD’s Ryzen processors, as there’s still a lot of optimizations that could be achieved.
Overall, the whole topic at hand was more of a storm in a tea-cup and misinterpretation of data, rather than a major technical issue on how the boost mechanism works.
Related Articles:
- The AMD Ryzen 9 3950X Review: 16 Cores on 7nm with PCIe 4.0
- AMD Q4: 16-core Ryzen 9 3950X, Threadripper Up To 32-Core 3970X, Coming November 25th
- The AMD 3rd Gen Ryzen Deep Dive Review: 3700X and 3900X Raising The Bar
- AMD Releases New Chipset Drivers For Ryzen 3000: More Relaxed CPPC2 Upscaling
- AMD Ryzen 3000 Post-Review BIOS Update Recap: Larger ST Gains, Some Gains, Some Losses








59 Comments
View All Comments
Gigaplex - Friday, November 22, 2019 - link
Sigh. Yet another case of hardware/firmware hard-coding behaviour and abusing specifications to cater for the current version of Windows. This totally won't cause any problems on non-Windows operating systems, or future/past versions of Windows...mat9v - Friday, November 22, 2019 - link
Problems? No. Minimally lower performance on systems other then Windows? Probably, but not necessarily - while default info supplied by UEFI will change, there is no reason for CPU driver not tu use additional information (which will probably still be available). AMD is planning to change default source of info not remove core quality info completely. I suppose Linux will still be able to use and account for core quality (because it does not use core rotation).What Windows is lacking is an ability to disable core rotation on desktop and server systems - the user should have an ability to choose. My cooling solution can keep 3900X in ST applications below 60C even overclocked to 4.6Ghz, only when 6 or more threads are running full speed heat becomes a problem and crosses 60C threshold. Of course that does not count AVX2 loads - they are a different kind of beast ;)
jospoortvliet - Friday, November 22, 2019 - link
Windows should just move to the linux kernel... better performance, less mess.gamerk2 - Friday, November 22, 2019 - link
"Windows should just move to the linux kernel... better performance, less mess."The linux kernel is a mess of a design; from everything I've seen, Windows is architected better.
The problem is the scheduler on Windows still treats all cores as equal; it's dump to things like CCX hopping for L2/L3 cache effects. What Windows needs is some way to get core loading characteristics back to the scheduler, so it can better handle these types of cases.
gamerk2 - Friday, November 22, 2019 - link
You *can* override core affinity, and turn off cores for an application if you so desire.Of course, nothing is stopping some other application from doing the same, leading to more performance oddities...
eva02langley - Friday, November 22, 2019 - link
It's great to see real article and not a plain attempt for clickbait or propaganda.techglitch - Friday, November 22, 2019 - link
So I understand that for the generic API/protocol they're surfacing information about the cores in order to be ideal for MS Windows, to compensate for the way its thread CPU Scheduler works; makes sense by market share. My understanding is that Linux should actually use the information from the AMD Proprietary API instead, because Linux's CPU Scheduler is different. If Linux's kernel trusted the generic information it would actually hurt performance a little.Maybe for AMD's EPYC line of CPU's though they should use the generic protocol to surface the RIGHT information. Because EPYC CPU's are mostly for servers, and the majority market share for servers is Linux.
So if they're catering to market share, then their EPYC CPU's shouldn't use the same logic designed to "optimize" for Window's CPU Scheduler, but should instead optimize for Linux's CPU Scheduler.
vamsi.vadrevu2000 - Sunday, November 24, 2019 - link
Now that is an excellent article. I couldn't find this info anywhere else and I always wondered why Ryzen Master was showing me best performing core.umano - Monday, November 25, 2019 - link
In my opinion, there is a lot of fuss about ryzen's 3000 peak frequency. I am not saying that is not an important topic and I loved the article, but there are more relevant areas of improvements for ryzen 3000, we are too accustomed to intel architectures, it will take time for the market to "culturally" adjust. One thing for sure, windows scheduler needs to be betterurbanman2004 - Monday, December 16, 2019 - link
3700X FTW 😅