Raja Koduri at Intel HPC Devcon Keynote Live Blog (4pm MT, 11pm UTC)
by Dr. Ian Cutress on November 17, 2019 5:06 PM EST
05:52PM EST - Prior to the annual Supercomputing conference, Intel hosts its HPC Developer Conference a couple of days before. This year's HPC Devcon keynote talk is from Intel SVP, Chief Architect and General Manager of Architecture, Raja Koduri, with promises to cover Intel's efforts as it relates to Graphics and Software in HPC. We're here with the live blog of Raja's presentation.

05:56PM EST - Looks like a few hundred attendees getting seated. Should start here in a few minutes
05:58PM EST - Already spotted a few familiar faces from our peers at other media outlets, as well as Intel's partners
06:04PM EST - People still coming in. Looks like they don't want to start until the doors close
06:09PM EST - Here we go
06:10PM EST - Some intro quotes from the emcee

06:11PM EST - HPC is critical to driving computing forward
06:11PM EST - Using AI to take this community (HPC) to the next level
06:11PM EST - This is an important space for Intel, no longer a niche
06:11PM EST - the foundation of the future
06:11PM EST - critical to the data-centric vision
06:12PM EST - Raja Koduri to the stage
06:12PM EST - short video first
06:13PM EST - A video on the six pillars



06:14PM EST - 'Exascale for Everyone'

06:15PM EST - These are interesting times with computing, with AI
06:15PM EST - It's an interesting time for math
06:16PM EST - We frequency debate these days on what is true and what is not true - we can all agree on math, particularly integer math!
06:16PM EST - Starting with some history
06:16PM EST - Intel has been doing HPC, working in this market, for decades
06:17PM EST - Early HPC was vertically integrated - everything was proprietary
06:17PM EST - 2nd era of HPC was mostly based on general purpose CPUs

06:18PM EST - Here we are in the next era - exascale

06:18PM EST - Driven by the need for AI compute
06:18PM EST - Over the last 40 years, when Intel made tons of compute available to lots of people, major technology disruptions happen
06:18PM EST - Compute democratization
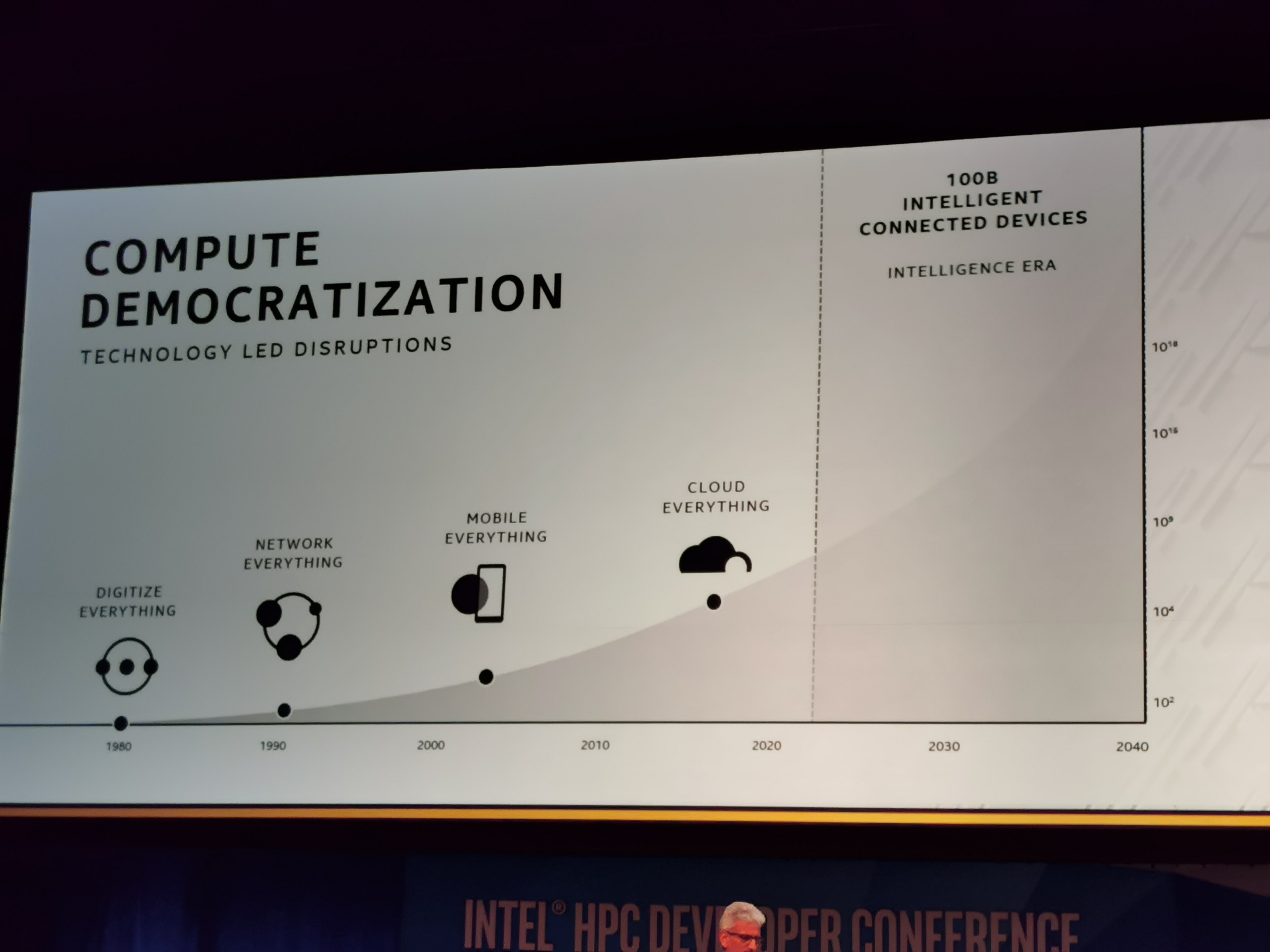
06:20PM EST - The intelligence era - 100 billion connected devices that need access to a ton of compute power
06:20PM EST - the next phase is exascale for everyone
06:21PM EST - This is one of Intel's key mission statements
06:21PM EST - Spent a lot of time building on what this is meant to mean
06:21PM EST - First new GPU architecture is codenamed Xe

06:22PM EST - Xe = eXascale for Everyone (not x^2.718)
06:22PM EST - Was going to disclose details at the last architecture day

06:23PM EST - The summary for Intel's roadmap in a single (long) sentence
06:23PM EST - products and architectures of the future are all guided by this principle
06:24PM EST - Some people are annoyed at projects cancelled and dates changed
06:24PM EST - Intel had fundamental confusion and conflict around heterogeneous architectures
06:24PM EST - 'Intel is a CPU company, they don't understand anything else' was a typical comment

06:26PM EST - There's no point building a longer car when you really need a train
06:26PM EST - Intel looked at workload patterns
06:26PM EST - Scalar computation, vector computation
06:26PM EST - matrix is having a renaissance due to AI
06:27PM EST - Other workloads with interesting patterns are currently called 'spatial', and currently use FPGAs
06:27PM EST - What is the impact of an architecture?
06:28PM EST - The impact is performance multiplied by generality
06:28PM EST - if you can get a high performance architecture that can be used everywhere, it's a winner. In reality there's a trade off

06:29PM EST - Every part of the software stack has 100,000s of developers, 100Bs of companies at every level

06:30PM EST - Heterogenity math in Intel CPUs, 150x in 6 years
06:30PM EST - AVX -> AVX2 -> AVX512
06:31PM EST - and new software, like DL Boost
06:31PM EST - This isn't going to stop
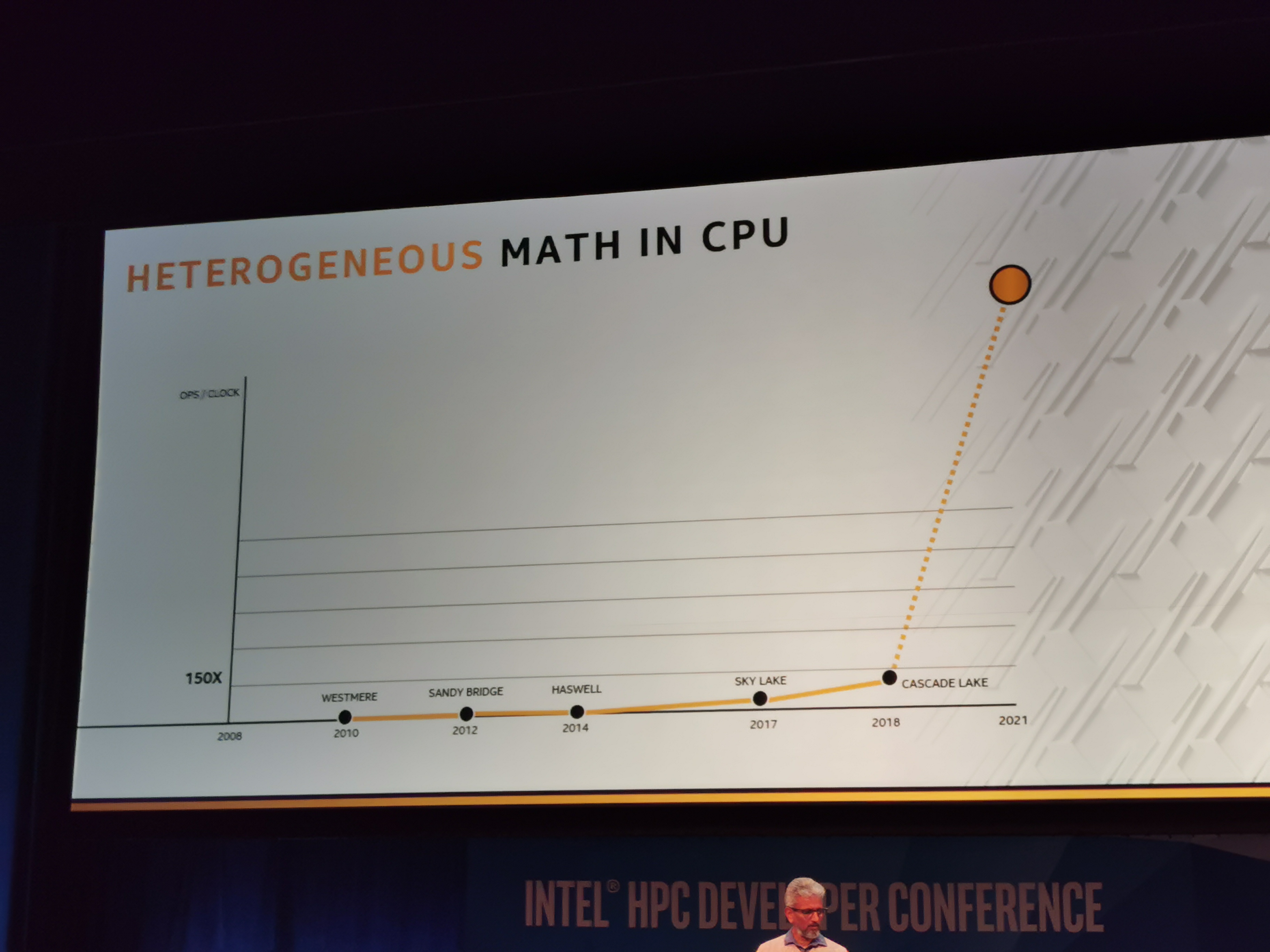
06:31PM EST - Another order of magnitude by 2021
06:32PM EST - (you can guess what instructions Intel is talking about here...)
06:32PM EST - ISA extensions

06:32PM EST - Every generation of increased math ops takes longer and longer for adoption
06:32PM EST - Now discrete GPUs
06:33PM EST - There's always more perfomrance available, but it becomes less general

06:33PM EST - So far only one major successful HPC software stack for GPUs in the market: CUDA
06:34PM EST - Every year, the portion of TOP500 systems that GPUs is growing. Currently 30%

06:34PM EST - Typically requires multiple software stacks, which is an unscalable solution
06:34PM EST - That led to oneAPI

06:35PM EST - cue the metal music
06:35PM EST - oneAPI will be open
06:36PM EST - oneAPI as a 100B device opportunity
06:36PM EST - The only way to scale is with open standards
06:36PM EST - Will cover xPU = Scalar+Vector+Matrix+Spatial
06:36PM EST - no programming for a single node any more

06:37PM EST - CPU+GPU+AI+FPGA
06:37PM EST - Needs to cover every developer, needs interfaces for every level of control

06:38PM EST - The stack covers five key areas, for all Intel hardware


06:40PM EST - Intel is betting on standards
06:40PM EST - Intel DPC++ compiler
06:40PM EST - This is the support for the first version of oneAPI

06:40PM EST - Driving all the common Intel libraries to oneAPI

06:41PM EST - CUDA to oneAPI conversion tools
06:42PM EST - (note, Raja was part of the HIPify effort at AMD. That hasn't spread far)

06:42PM EST - All Intel debug tools will be available through oneAPI

06:43PM EST - oneAPI beta now available for download
06:44PM EST - Intel oneAPI is available on Intel DevCloud today


06:44PM EST - Now GPU hardware - architecture roadmap
06:45PM EST - Even when Raja was a competitor, the Xeon Phi looked weird. Use a GPU!
06:45PM EST - GPU roadmap was founded on this prinicple that Intel is going to give FLOPS and BW in an easy programmable way

06:46PM EST - Look, Gen10 graphics is now in this diagram!
06:46PM EST - Leveraging Intel's capabilities

06:47PM EST - Xe will be one architecture, split into two microarchitectures to cover the range of requirements
06:47PM EST - Xe(LP) and Xe(HP)
06:47PM EST - are those the official names?
06:48PM EST - Now there's a third microarchitecture for HPC
06:48PM EST - Xe(HPC)

06:48PM EST - Today is only about Xe(HPC)
06:48PM EST - Fundamental difference between them are the features that target is market segment
06:48PM EST - LP is 5W-20W
06:49PM EST - It could scale up to 50W, but it scales off.. Doesn't have much operating range, but this is what's required in this market
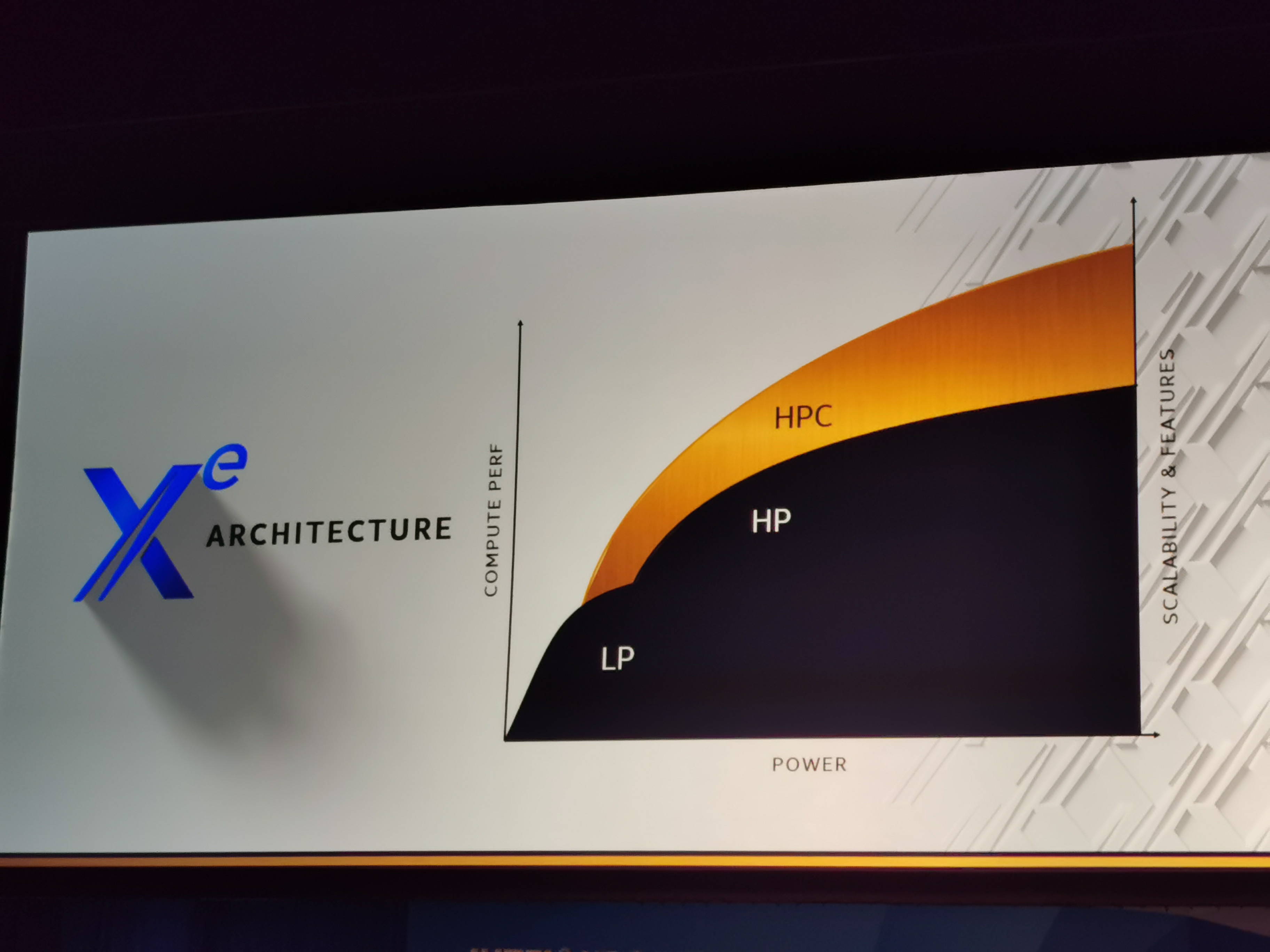
06:50PM EST - HPC is more compute optimized more than graphics optimized
06:50PM EST - XeHPC seems to cover over XeHP but in a more compute focused aspect


06:51PM EST - SIMD and SIMT styles
06:51PM EST - CPU, GPU, and Max perf styles
06:51PM EST - All part of Xe
06:51PM EST - SIMT looks like AVX
06:52PM EST - Vector width matching needs to happen
06:52PM EST - The engine needed to be flexible for existing workloads
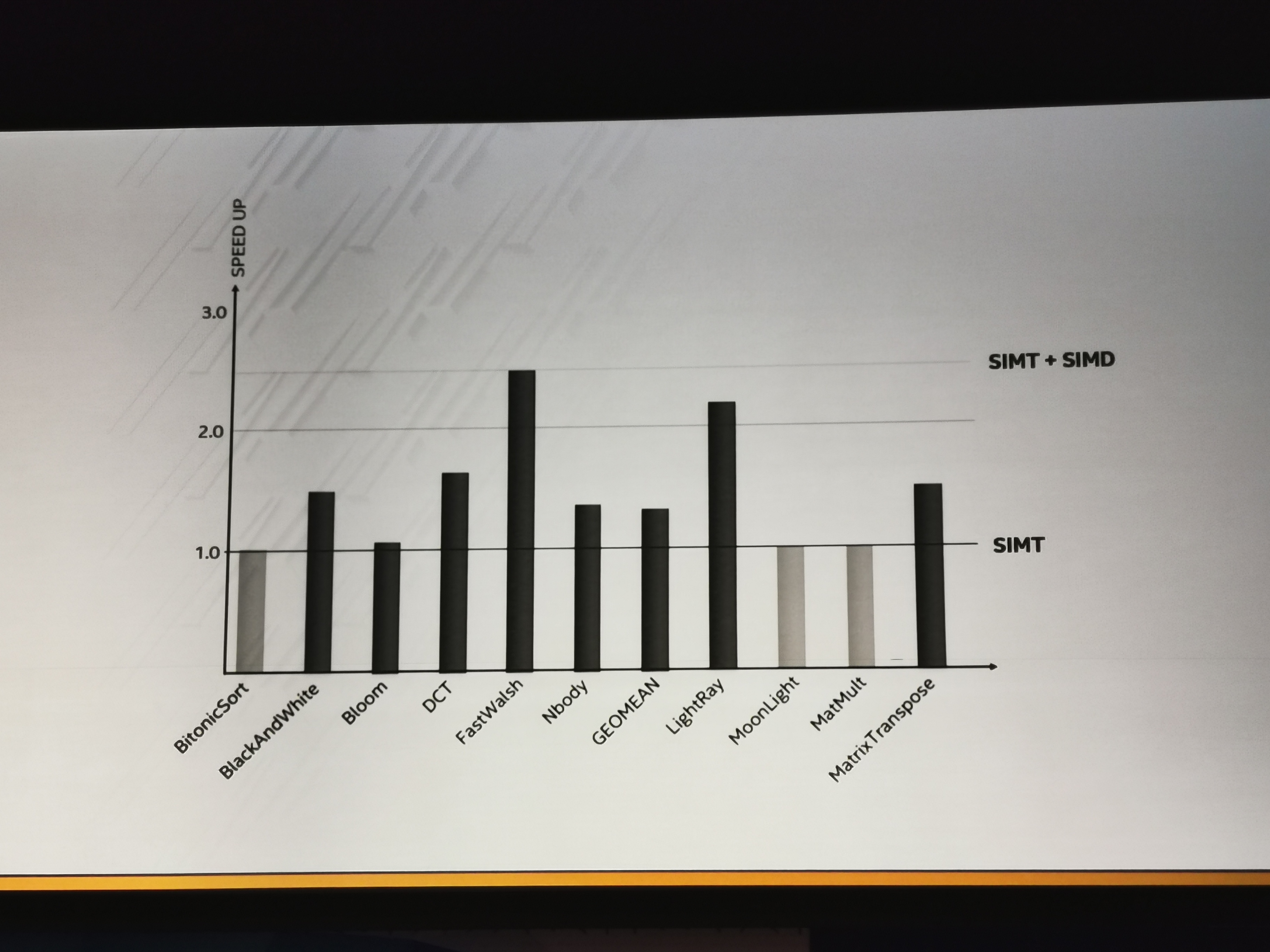
06:52PM EST - Performance upload expected
06:52PM EST - Xe is scalable to 1000s of EUs

06:53PM EST - *SIMD looks like AVX, sorry
06:53PM EST - New matrix vector engine, supports INT8, BF16, FP16
06:54PM EST - Looks like an 8x8x8 matrix unit ?

06:54PM EST - 40x increase in DPFP per EU
06:54PM EST - (so Intel will keep the 'EU' name)

06:55PM EST - XEMF = Xe Memory Fabric, scalable to 1000s of Xe EUs

06:56PM EST - Rambo cache, high footprint, very large
06:56PM EST - unified cache, accessible to CPUs and GPUs
06:56PM EST - and other GPUs connected to this GPU

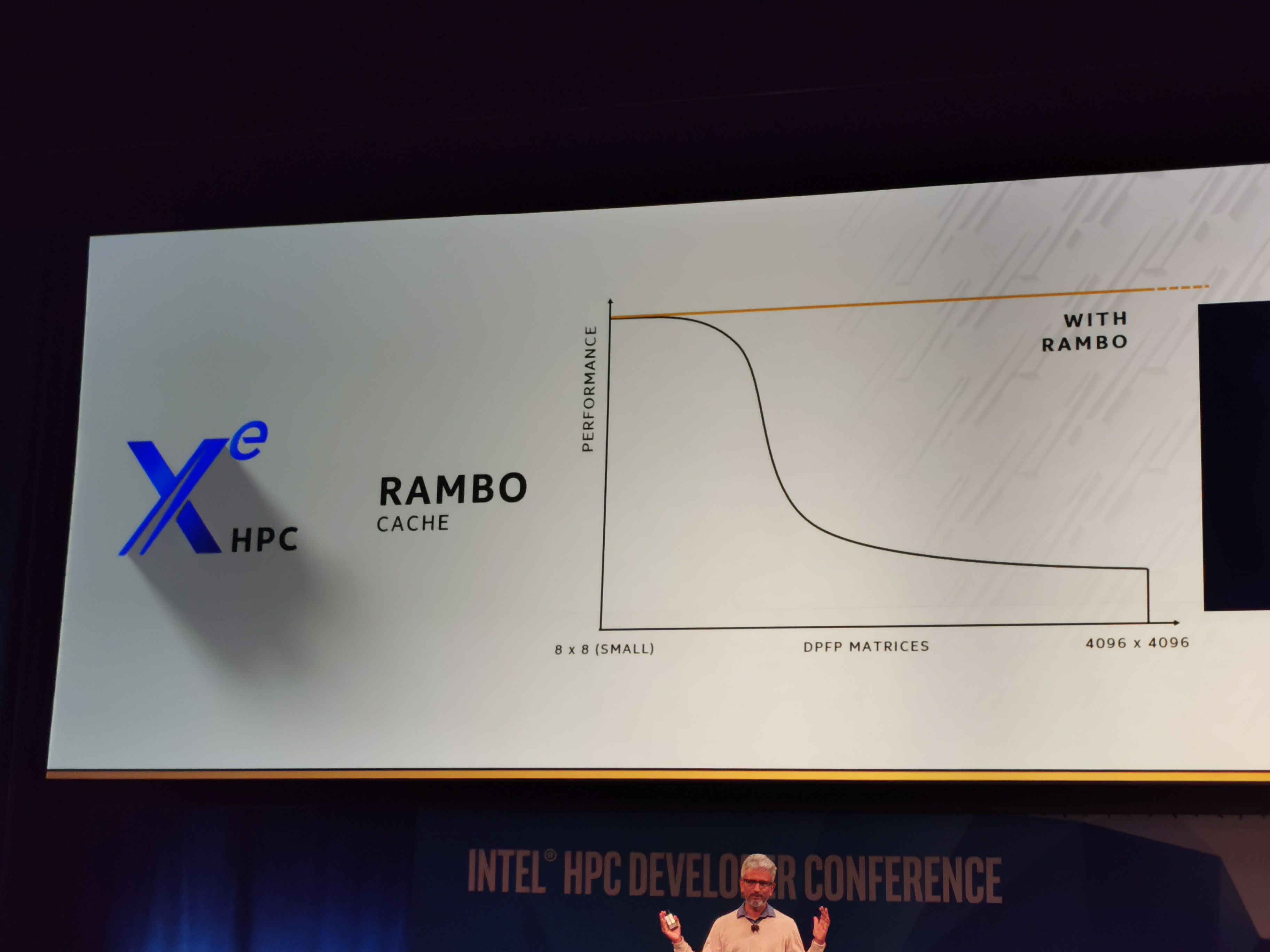
06:57PM EST - Keeps double precision matrix performance at peak
06:57PM EST - making dealing with memory really easy
06:58PM EST - XEMF supports fully coherent memory connected to other CPUs and GPUs
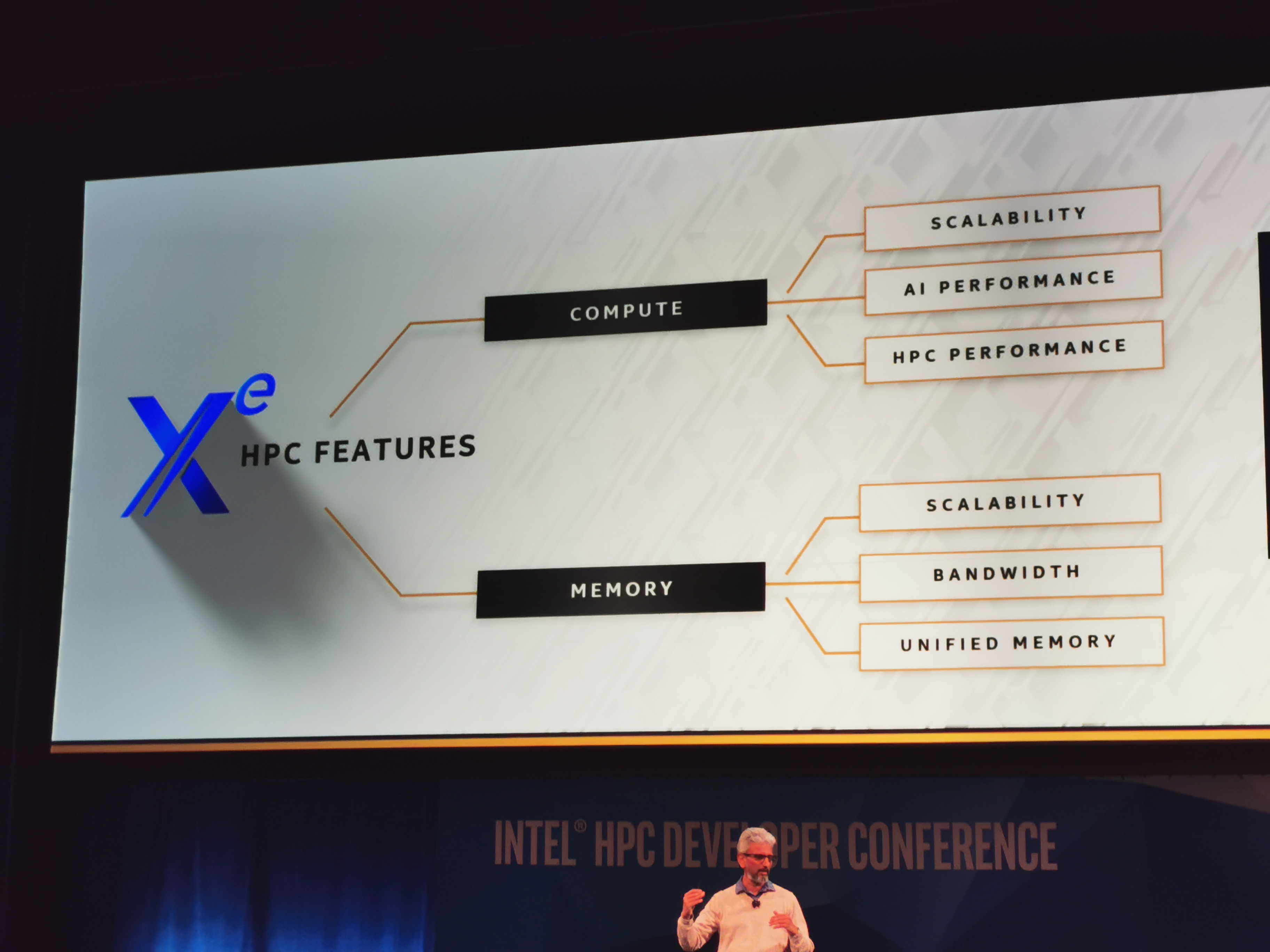

06:58PM EST - Exascale has lots of challeneges

06:59PM EST - Compute density enabled through 7nm and Foveros
06:59PM EST - Diagram shows 8 chiplets with inter-node chips


07:00PM EST - EMIB connectivity for HBM, Foveros for Rambo cache
07:00PM EST - Enables high density and bandwidth/watt

07:01PM EST - Another SoC, called Xe Link
07:01PM EST - Supports unified memory across multple GPUs with CXL

07:01PM EST - GPU will have Xeon Class RAS, as well as ECC, Parity across all memory and cache
07:02PM EST - Ponte Vecchio GPU



07:03PM EST - 16 compute chiplets, HBM
07:03PM EST - This is what's going in Aurora
07:03PM EST - The Exascale supercomputer, coming 2021
07:04PM EST - The AUrora node will have 2 Xeons and 6 Ponte Vecchio GPUs
07:05PM EST - Aurora brings it all together
07:05PM EST - Two Sapphire Rapids GPUs


07:05PM EST - all-to-all connectivity within a node
07:06PM EST - oneAPI
07:06PM EST - 8 fabric endpoints per node
07:06PM EST - Details being out today to help drive the software development early
07:06PM EST - Aurora - Delivered in 2021
07:06PM EST - (don't ask if Q1 or Q4)
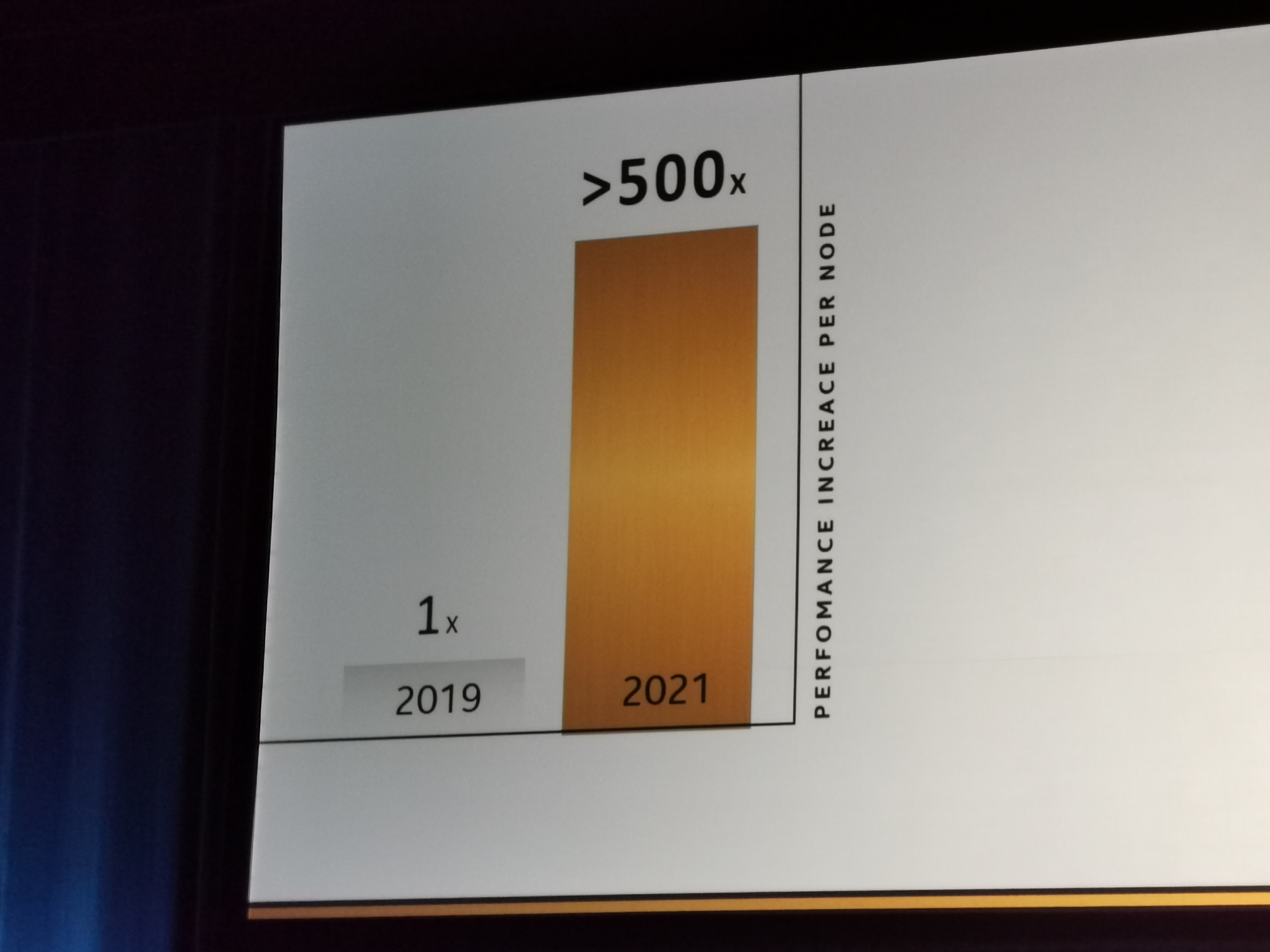
07:08PM EST - AIming for 500x perf per node in HPC by 2021
07:09PM EST - That's a wrap! Time for Q&A. Ping me asap on twitter (@IanCutress) if you have any questions








54 Comments
View All Comments
Zoolook13 - Wednesday, November 20, 2019 - link
CXL, it's mentioned in the story.JayNor - Saturday, December 21, 2019 - link
The story did mention using CXL for cache coherent connections among the CPUs and GPUs within the node, which I presume is also on PCIE5 based on their previous discussions. However, several articles mention use of Slingshort interconnects, which I presume is for between system nodes. For example, this article:https://www.hpcwire.com/2019/03/18/its-official-au...
mode_13h - Monday, November 18, 2019 - link
> That's a wrap! Time for Q&A.So... I guess there weren't any good questions? Or maybe just no good answers?
Ian Cutress - Monday, November 18, 2019 - link
Stay tuned. Will be a separate article.mode_13h - Monday, November 18, 2019 - link
Thank you for the coverage!ABR - Monday, November 18, 2019 - link
So the empire is getting ready to strike back. Nvidia, AMD, and Intel have been converging for years, and now the showdown is coming. AMD was first to recognize the way the winds were blowing when it bought ATI. It hoped for an early, quick victory with its APU paradigm, but neither software nor market were ready. Intel and Nvidia both drew next at the same time, Intel broadening to massively parallel architectures with Larrabee, Nvidia to centralized ones with ARM and Tegra. Both failed, while AMD whiffed with Bulldozer, but now everybody's back for round 2. Intel has been honing its parallel game, and now seems to have learned the importance of the software stack from Nvidia. Meanwhile AMD has regained its hardware mojo and even scored a win with its packaging innovations. Nvidia still has the software lead, but without a real CPU story it has to rely on the big serial era coming to a close fast enough for this not to matter. AMD has the hardware now but lack of vision and execution on the software side is a major weakness. Finally, Intel remains a hardware force, and its history of strong compilers bodes well for its software chances, but it has yet to prove itself in parallel computing. Let the game begin!abufrejoval - Tuesday, November 19, 2019 - link
You summed it up in a rather rare mixture of eloquence and succintness: Bravo!lobz - Monday, November 18, 2019 - link
This on 7nm in 2021? I'm calling utter bs here.HollyDOL - Monday, November 18, 2019 - link
Well, they managed to wake up and deliver Core 2 after being kicked long enough, so it's not completely unimaginable.Otoh I want to see mass delivery and enough benchmarks to believe the claim :-)
mr_tawan - Monday, November 18, 2019 - link
So AMD killed the APU and now Raja is trying to bring it back at Intel ?