SiFive Announces First RISC-V OoO CPU Core: The U8-Series Processor IP
by Andrei Frumusanu on October 30, 2019 10:00 AM ESTPerformance Targets, PPA and Conclusion
The U8-Series microarchitecture will initially be productized as two IP offerings: The U84 and the U87 CPU cores:

The U87 will only be available later next year, whilst the U84 is also being finalised right now. The company has the U84 IP running internally on FPGA platforms.
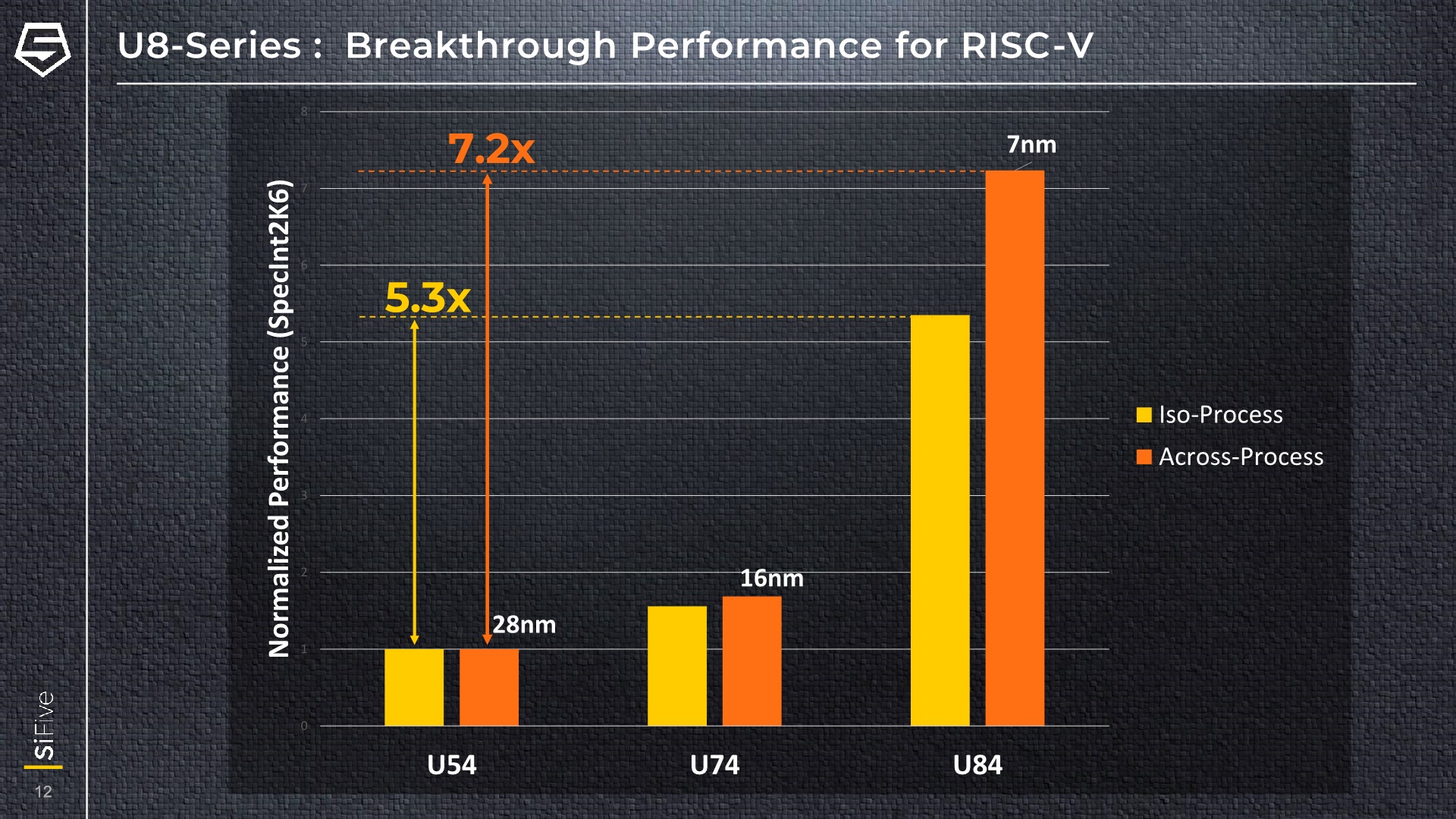
The performance increases compared to previous generation SiFive cores are extremely impressive: Against a U54 at ISO-process, the new U84 features a 5.3x performance increase in SPECint2006. When taking into account the process node improvements that allow the U84 to clock higher, the generational increases that we’d be seeing in products will be more akin to a factor of 7.2x.
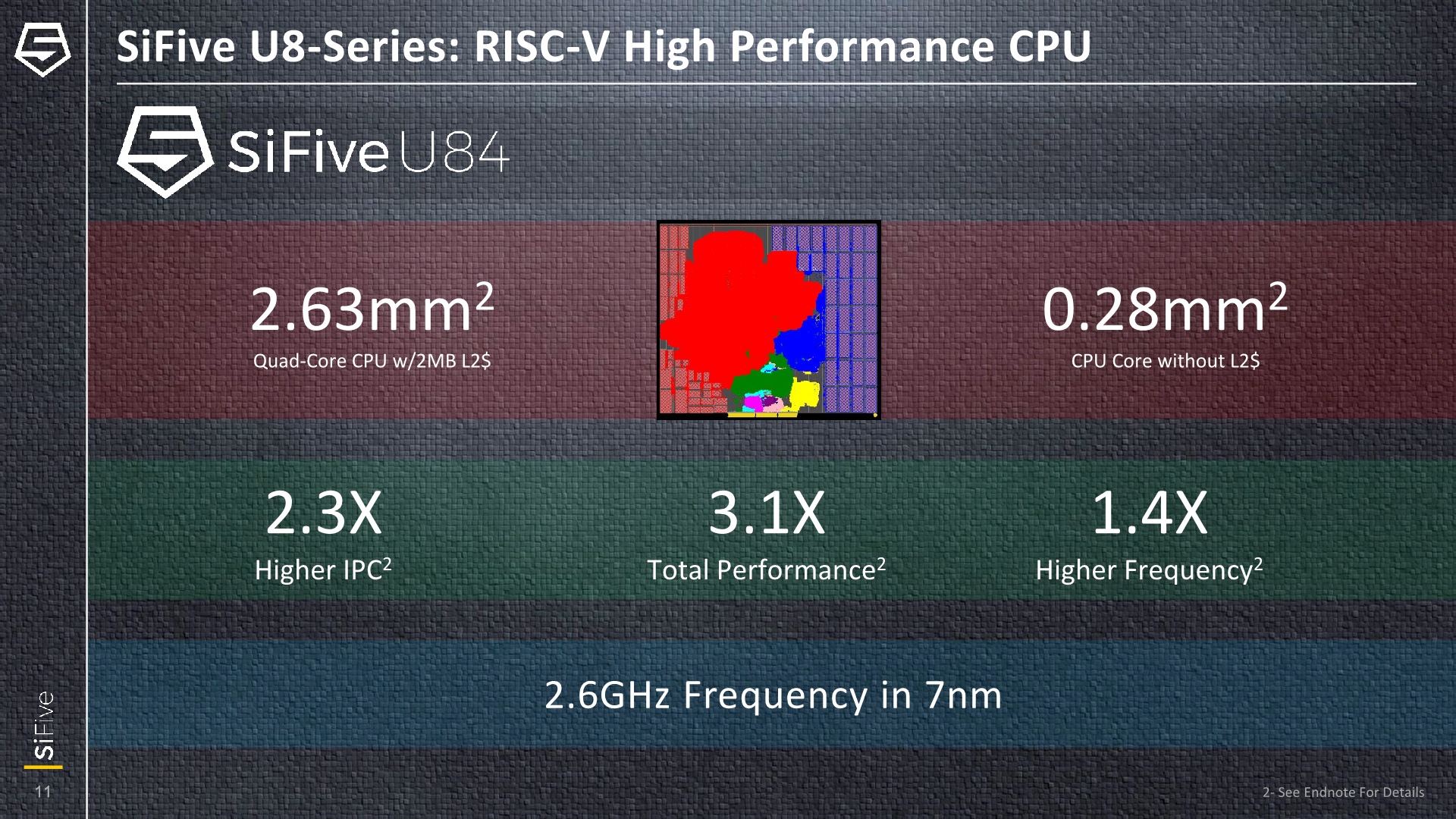
In terms of PPA, compared to a U7-series CPU, IPC increases come in at 2.3x resulting in 3.1x higher performance (ISO-process). A lot of the performance increases of the U8-series come thanks to the increased frequencies capabilities which are 1.4x higher this generation, with the core scaling up to 2.6GHz on 7nm.
On the same 7nm process, the U84 lands in at 0.28mm² per core and a cluster comprising four cores and a 2MB L2 cache measure in at 2.63mm². For comparison, a Arm Cortex-A55 as measured on the Kirin 980, also on 7nm, a core with its 128KB private L2 cache comes in at 0.36mm². Given that SiFive promises of similar performance to a Cortex-A72, which in turn would be more than double the performance of an A55, it looks like SiFive’s U84 core would be extremely competitive in terms of its PPA.

Finally, SiFive is able to configure of up to 9 CPU cores into a coherent cluster with a shared L2. The IP is also able to this in a heterogeneous way, similar to Arm’s big.LITTLE approach, employing both U8 and U7 series and even S-Series CPUs into the same cluster.
Conclusion - A Big Step In a Long Journey
Overall, SiFive’s new U8 core is I think a very important and major step for the company in terms of pushing its products and as well as pushing the RISC-V ecosystem forward. The key takeaway from the U8 is the massively improved performance of the core that now suddenly allows the company to seriously compete against some of Arm’s low- and mid-range cores.
I’m not really expecting to see the core employed in products such as smartphones any time soon as frankly SiFive still has a very long road ahead in terms of improving absolute performance. That being said, in the IoT and embedded markets, I think we’ll see faster and wider adoption of RISC-V cores, and SiFive is certain to see continued growth and interest for years to come. We’re looking forward in observing this future develop.








68 Comments
View All Comments
peevee - Tuesday, November 5, 2019 - link
"ARM is literally 80's RISC too"Armv8? No it is not. It has very many complex instructions, more than any CISC CPU from the 80s.
TeXWiller - Wednesday, October 30, 2019 - link
On the other hand you can find demonstrations on how targeting RISC-V ISA can produce smaller end-products compared to targeting ARM or specifically MIPS.Modularity of the ISA is another thing and the most appealing factor still is the open nature of the ISA. This is what likely drives the adoption outside of US academia in companies like WD and in academic-industrial projects in Europe (the exascale accelerator) and India (national ISA). The aim for some schools is to produce graduates directly familiar with an ISA and architectures utilized in the industry without additional training.
I do wonder what effect the variable length instruction ecoding have on security if the system software is lacking on those demanding edge use-cases in the future, though.
Wilco1 - Wednesday, October 30, 2019 - link
Smaller products in what way? Saving a fraction of a mm^2 due to simplified decode is a great marketing story without doubt. However if you look at a modern SoC, typically less than 5% is devoted to the actual CPU cores. If the resulting larger codesize means you need to add more cache/flash/DRAM, increase clock frequency to deal with the extra instructions or makes it harder for a compiler to produce efficient code, is it really an optimal system-wide decision?TeXWiller - Wednesday, October 30, 2019 - link
I meant in terms of codesize as that was one of the bases of the MIPS comparison. Sorry for the confusion.Wilco1 - Thursday, October 31, 2019 - link
RISC-V is very similar to MIPS - MIPS never was great at codesize. When optimizing for size, compilers call special library functions to emulate instructions which are available on Arm. So you pay for saving a few transistors with lower performance and higher power consumption.zmatt - Thursday, October 31, 2019 - link
It's not a MIPS variant. MIPS is based on work at Stanford. RISC-V is the latest incarnation of the Berkeley RISC project. You are probably thinking of SPARC which is a derivative of earlier RISC project work. MIPS is only related in that it comes from similar ideas but the two projects, Stanford and Berkeley were different.name99 - Thursday, October 31, 2019 - link
That's like making a big deal about the difference between Spanish and Portuguese.Sure, if you're Spanish this is a big deal. But to the rest of the world they're basically the same thing; created by people in constant contact and with the same world view.
zmatt - Friday, November 1, 2019 - link
Well, Spanish and Portuguese are different. And claiming they are the same gets you labeled as either an idiot or a bigot.name99 - Friday, November 1, 2019 - link
Are they as different as Portuguese and Arabic? Spanish and Chinese?Are you really so ignorant that you don't know the family resemblance of Romance languages?
Wilco1 - Thursday, October 31, 2019 - link
RISC-V has practically nothing in common with Berkeley RISC-I/SPARC (no condition codes, no register windows etc). Basically Berkeley adopted Stanford's approach to RISC and created a MIPS variant.