The Intel Core i9-9990XE Review: All 14 Cores at 5.0 GHz
by Dr. Ian Cutress on October 28, 2019 10:00 AM ESTCPU Performance: System Tests
Our System Test section focuses significantly on real-world testing, user experience, with a slight nod to throughput. In this section we cover application loading time, image processing, simple scientific physics, emulation, neural simulation, optimized compute, and 3D model development, with a combination of readily available and custom software. For some of these tests, the bigger suites such as PCMark do cover them (we publish those values in our office section), although multiple perspectives is always beneficial. In all our tests we will explain in-depth what is being tested, and how we are testing.
All of our benchmark results can also be found in our benchmark engine, Bench.
Application Load: GIMP 2.10.4
One of the most important aspects about user experience and workflow is how fast does a system respond. A good test of this is to see how long it takes for an application to load. Most applications these days, when on an SSD, load fairly instantly, however some office tools require asset pre-loading before being available. Most operating systems employ caching as well, so when certain software is loaded repeatedly (web browser, office tools), then can be initialized much quicker.
In our last suite, we tested how long it took to load a large PDF in Adobe Acrobat. Unfortunately this test was a nightmare to program for, and didn’t transfer over to Win10 RS3 easily. In the meantime we discovered an application that can automate this test, and we put it up against GIMP, a popular free open-source online photo editing tool, and the major alternative to Adobe Photoshop. We set it to load a large 50MB design template, and perform the load 10 times with 10 seconds in-between each. Due to caching, the first 3-5 results are often slower than the rest, and time to cache can be inconsistent, we take the average of the last five results to show CPU processing on cached loading.

Application loading is a walk in the park for the Core i9-9990XE.
FCAT: Image Processing
The FCAT software was developed to help detect microstuttering, dropped frames, and run frames in graphics benchmarks when two accelerators were paired together to render a scene. Due to game engines and graphics drivers, not all GPU combinations performed ideally, which led to this software fixing colors to each rendered frame and dynamic raw recording of the data using a video capture device.
The FCAT software takes that recorded video, which in our case is 90 seconds of a 1440p run of Rise of the Tomb Raider, and processes that color data into frame time data so the system can plot an ‘observed’ frame rate, and correlate that to the power consumption of the accelerators. This test, by virtue of how quickly it was put together, is single threaded. We run the process and report the time to completion.
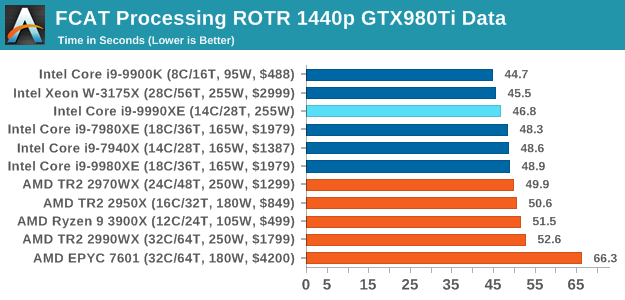
FCAT is getting fairly unified across all the processors, with only a few percent separating all the Intel parts.
3D Particle Movement v2.1: Brownian Motion
Our 3DPM test is a custom built benchmark designed to simulate six different particle movement algorithms of points in a 3D space. The algorithms were developed as part of my PhD., and while ultimately perform best on a GPU, provide a good idea on how instruction streams are interpreted by different microarchitectures.
A key part of the algorithms is the random number generation – we use relatively fast generation which ends up implementing dependency chains in the code. The upgrade over the naïve first version of this code solved for false sharing in the caches, a major bottleneck. We are also looking at AVX2 and AVX512 versions of this benchmark for future reviews.
For this test, we run a stock particle set over the six algorithms for 20 seconds apiece, with 10 second pauses, and report the total rate of particle movement, in millions of operations (movements) per second. We have a non-AVX version and an AVX version, with the latter implementing AVX512 and AVX2 where possible.
3DPM v2.1 can be downloaded from our server: 3DPMv2.1.rar (13.0 MB)
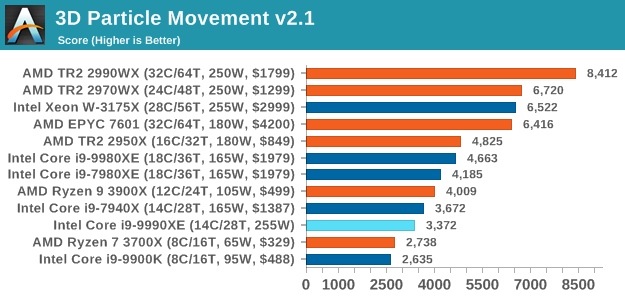
When we run our 3DPM test in a standard mode, the 9990XE again sees a slight regression compared to the 7940X, perhaps indicating that the mesh environment needs some extra MHz.
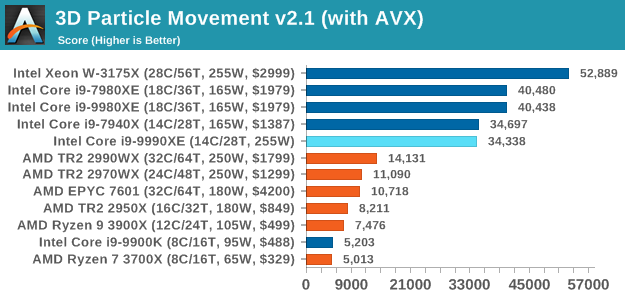
When adding AVX512 into the mix, the 9990XE rises up as with all the other Intel HEDT CPUs, but still can only match the slower 7940X despite having the same number of cores. At this point we're more core limited than frequency limited, indicating that there are some pipeline stalls in this test.
Dolphin 5.0: Console Emulation
One of the popular requested tests in our suite is to do with console emulation. Being able to pick up a game from an older system and run it as expected depends on the overhead of the emulator: it takes a significantly more powerful x86 system to be able to accurately emulate an older non-x86 console, especially if code for that console was made to abuse certain physical bugs in the hardware.
For our test, we use the popular Dolphin emulation software, and run a compute project through it to determine how close to a standard console system our processors can emulate. In this test, a Nintendo Wii would take around 1050 seconds.
The latest version of Dolphin can be downloaded from https://dolphin-emu.org/

Dolphin is a heavily single threaded test, so we see the highest frequency from Intel and AMD at the top here.
DigiCortex 1.20: Sea Slug Brain Simulation
This benchmark was originally designed for simulation and visualization of neuron and synapse activity, as is commonly found in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron / 1.8B synapse simulation, equivalent to a Sea Slug.
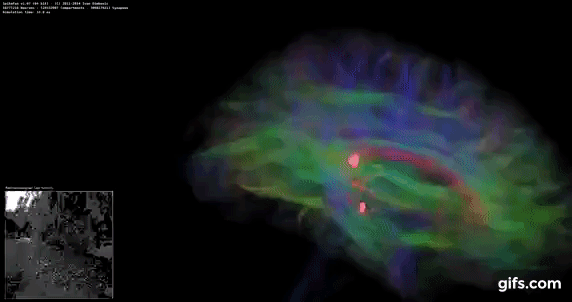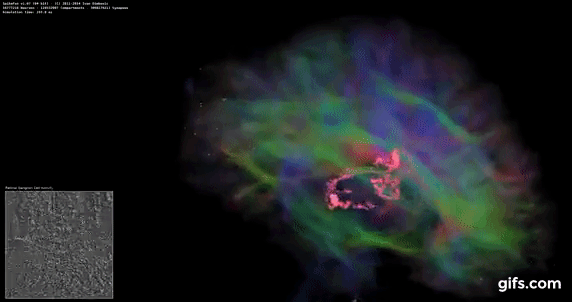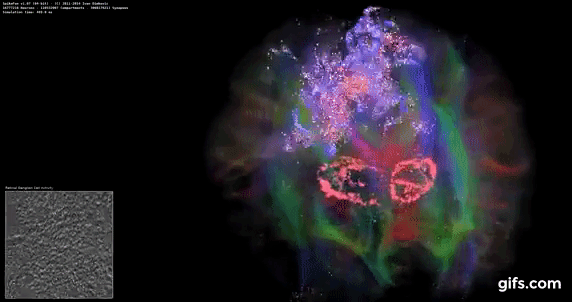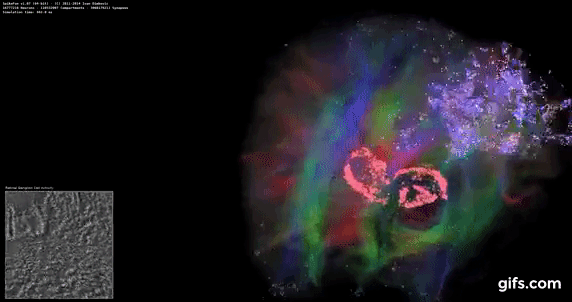
Example of a 2.1B neuron simulation
We report the results as the ability to simulate the data as a fraction of real-time, so anything above a ‘one’ is suitable for real-time work. Out of the two modes, a ‘non-firing’ mode which is DRAM heavy and a ‘firing’ mode which has CPU work, we choose the latter. Despite this, the benchmark is still affected by DRAM speed a fair amount.
DigiCortex can be downloaded from http://www.digicortex.net/
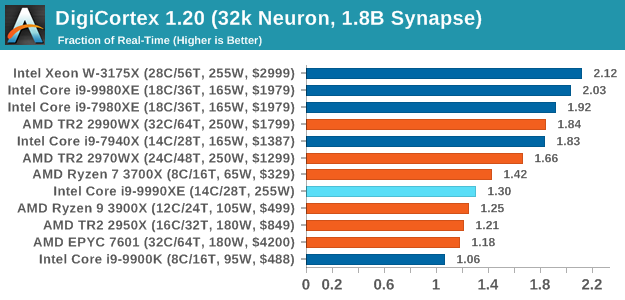
DigiCortex likes memory frequency and internal speeds more than raw core frequency, and again the 9990XE doesn't perform too well here.
y-Cruncher v0.7.6: Microarchitecture Optimized Compute
I’ve known about y-Cruncher for a while, as a tool to help compute various mathematical constants, but it wasn’t until I began talking with its developer, Alex Yee, a researcher from NWU and now software optimization developer, that I realized that he has optimized the software like crazy to get the best performance. Naturally, any simulation that can take 20+ days can benefit from a 1% performance increase! Alex started y-cruncher as a high-school project, but it is now at a state where Alex is keeping it up to date to take advantage of the latest instruction sets before they are even made available in hardware.
For our test we run y-cruncher v0.7.6 through all the different optimized variants of the binary, single threaded and multi-threaded, including the AVX-512 optimized binaries. The test is to calculate 250m digits of Pi, and we use the single threaded and multi-threaded versions of this test.
Users can download y-cruncher from Alex’s website: http://www.numberworld.org/y-cruncher/
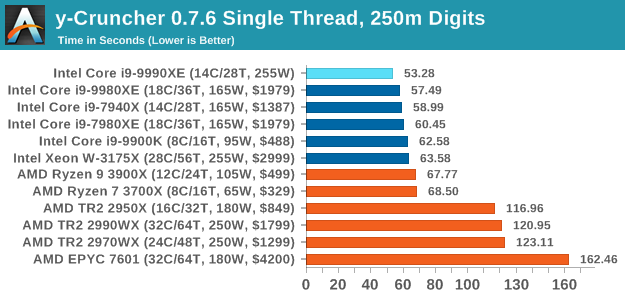
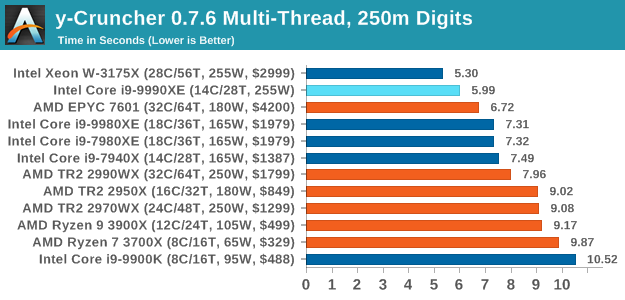
y-Cruncher is an AVX-512 accelerated test, and with the high frequency it gets the top score in our ST test.
Agisoft Photoscan 1.3.3: 2D Image to 3D Model Conversion
One of the ISVs that we have worked with for a number of years is Agisoft, who develop software called PhotoScan that transforms a number of 2D images into a 3D model. This is an important tool in model development and archiving, and relies on a number of single threaded and multi-threaded algorithms to go from one side of the computation to the other.

In our test, we take v1.3.3 of the software with a good sized data set of 84 x 18 megapixel photos and push it through a reasonably fast variant of the algorithms, but is still more stringent than our 2017 test. We report the total time to complete the process.
Agisoft’s Photoscan website can be found here: http://www.agisoft.com/

Agisoft is a variable threaded workload, and it seems the Core i9-9990XE has the best combination of cores and threads.








145 Comments
View All Comments
Sivar - Monday, October 28, 2019 - link
Why such an angry statement?14 is a very respectable number of cores. 14 at 5GHz is a world exclusive.
I wouldn't even call this a product -- more of a hand-picked specialty part auction, which is perfectly reasonable (if uncommon) for any manufacturer to do. The fact that the parts sold indicates the demand is there. Why ignore the demand?
Spunjji - Wednesday, October 30, 2019 - link
The fact that they sold very few of them indicates that the demand is barely there.FunBunny2 - Monday, October 28, 2019 - link
"Stories of companies spending 10s of millions to implement line-of-sight microwave transmitter towers to shave off 3 milliseconds from the latency time is a story I once heard. "There was reporting, mainstream source (Lewis: https://www.telegraph.co.uk/finance/newsbysector/b... that a broker(s) installed a fiber line from the Chicago office to an exchange in NJ.
“It needed its burrow to be straight, maybe the most insistently straight path ever dug into the earth. It needed to connect a data centre on the South Side of Chicago to a stock exchange in northern New Jersey. Above all, apparently, it had to be secret," Mr Lewis said.
bji - Monday, October 28, 2019 - link
I call BS on that story. Why would you spend hundreds of millions (it must have cost at least that right?) to dig a straight 800+ mile tunnel between Chicago and NYC to get a 13 ms latency just so you could be destroyed by offices in NYC with 5 ms latency. Makes no sense. Your only choice is to move physically close to the source, if lowest latency is the winner then that's the only way to get it and be competitive.Authors happily embellish existing stories, misrepresent details, and just plain old make sh** up to sell books. And then news outlets happily garbage-in, garbage-out these stories to get hits. I'm pretty sure that's what happened with that "story".
eek2121 - Monday, October 28, 2019 - link
Companies have done it. Hell years ago I INTERVIEWED with a company that did it. It would blow your mind to find out what the financial folks will do to accelerate trading. A large portion of stock market trades are automated and driven by machine learning or predictive algorithms. How do I know, that position I interviewed for years ago (2003) was for a software developer for such an algorithm. I didn't get the job, because I didn't have the skills they were looking for at the time, but we did have a very interesting conversation about how their platform worked. It's fascinating how finance pushes everything forward.FunBunny2 - Monday, October 28, 2019 - link
" It would blow your mind to find out what the financial folks will do to accelerate trading."yes, yes it would - here: https://www.marketplace.org/2019/10/07/fight-nyse-...
bji - Monday, October 28, 2019 - link
Yes, I believe that those companies probably often spend lots of money to buy competitive advantages. I am simply stating that they'd not be buying a competitive advantage here (since the real competition is based in NYC had has an insurmountable advantage - the laws of physics not letting signals travel between Chicago and Wall St. faster than 13 ms) so they wouldn't spend the money. They would spend money buying an actual competitive advantage, i.e. offices in NYC.mode_13h - Tuesday, October 29, 2019 - link
> Why would you spend hundreds of millions (it must have cost at least that right?) to dig a straight 800+ mile tunnel between Chicago and NYC to get a 13 ms latency just so you could be destroyed by offices in NYC with 5 ms latency. Makes no sense. Your only choice is to move physically close to the source, if lowest latency is the winner then that's the only way to get it and be competitive.When something doesn't seem to make sense, maybe the error is in your understanding of the situation. Did you ever consider that there are financial markets outside of NYC, and that some people might be trading between markets, or using signals from one market to inform trades in others?
Joel Busch - Tuesday, October 29, 2019 - link
This one is easy to answer, because there are two stock exchanges in play. NYSE in New York and CHX in Chicago. If you can send information from one exchange to the other quicker than others then you have an opportunity for arbitrage.One of my professors is Ankit Singla, he works on c-speed networking, he cited this paper in class https://doi.org/10.1111/fire.12036
They say for example:
"Our analysis of the market data confirms that as of April 2010, the fastest communication route connecting the Chicago futures markets to the New Jersey equity markets was through fiber optic lines that allowed equity prices to respond within 7.25–7.95 ms of a price change in Chicago (Adler, 2012). In Au-gust of 2010, Spread Networks introduced a new fiber optic line that was shorter than the pre-existing routes and used lower latency equipment. This technology reduced Chicago–New Jersey latency to approximately 6.65 ms (Steiner, 2010; Adler,2012)."
I don't have the time to read the whole paper right now, I'll just trust my professor here. If there is actually something wrong with their methodology then I think the world would like to hear it.
rahvin - Monday, October 28, 2019 - link
<<“It needed its burrow to be straight, maybe the most insistently straight path ever dug into the earth. It needed to connect a data centre on the South Side of Chicago to a stock exchange in northern New Jersey. Above all, apparently, it had to be secret," Mr Lewis said>>That's just a bunch of hogwash. You couldn't dig a straight line from Chicago to Jersey. It's just fancy sounding hogwash meant to convince those without the logic or background to see it for the hogwash it is. It's no more true than grimm's fairy tales.