The Intel Core i9-9990XE Review: All 14 Cores at 5.0 GHz
by Dr. Ian Cutress on October 28, 2019 10:00 AM ESTCPU Performance: Web and Legacy Tests
While more the focus of low-end and small form factor systems, web-based benchmarks are notoriously difficult to standardize. Modern web browsers are frequently updated, with no recourse to disable those updates, and as such there is difficulty in keeping a common platform. The fast paced nature of browser development means that version numbers (and performance) can change from week to week. Despite this, web tests are often a good measure of user experience: a lot of what most office work is today revolves around web applications, particularly email and office apps, but also interfaces and development environments. Our web tests include some of the industry standard tests, as well as a few popular but older tests.
We have also included our legacy benchmarks in this section, representing a stack of older code for popular benchmarks.
All of our benchmark results can also be found in our benchmark engine, Bench.
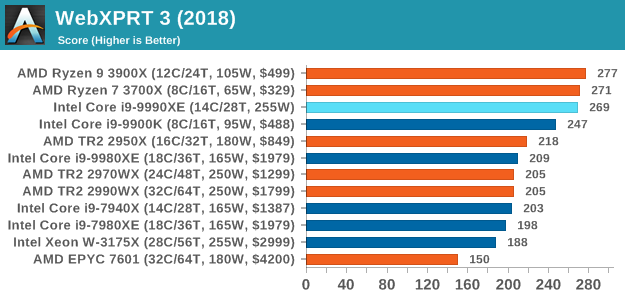
WebXPRT 3: Modern Real-World Web Tasks, including AI
The company behind the XPRT test suites, Principled Technologies, has recently released the latest web-test, and rather than attach a year to the name have just called it ‘3’. This latest test (as we started the suite) has built upon and developed the ethos of previous tests: user interaction, office compute, graph generation, list sorting, HTML5, image manipulation, and even goes as far as some AI testing.
For our benchmark, we run the standard test which goes through the benchmark list seven times and provides a final result. We run this standard test four times, and take an average.
Users can access the WebXPRT test at http://principledtechnologies.com/benchmarkxprt/webxprt/
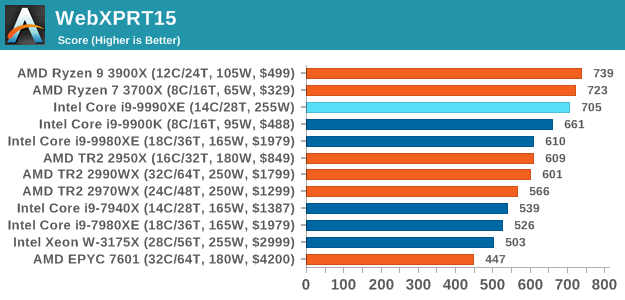
WebXPRT 2015: HTML5 and Javascript Web UX Testing
The older version of WebXPRT is the 2015 edition, which focuses on a slightly different set of web technologies and frameworks that are in use today. This is still a relevant test, especially for users interacting with not-the-latest web applications in the market, of which there are a lot. Web framework development is often very quick but with high turnover, meaning that frameworks are quickly developed, built-upon, used, and then developers move on to the next, and adjusting an application to a new framework is a difficult arduous task, especially with rapid development cycles. This leaves a lot of applications as ‘fixed-in-time’, and relevant to user experience for many years.
Similar to WebXPRT3, the main benchmark is a sectional run repeated seven times, with a final score. We repeat the whole thing four times, and average those final scores.
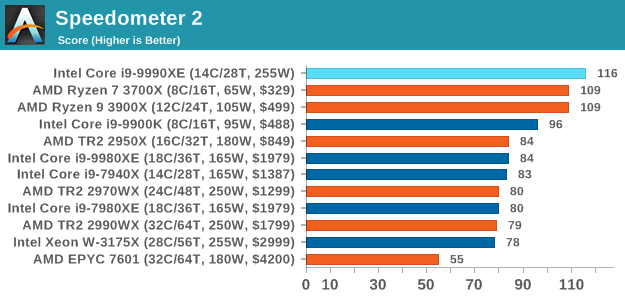
Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a accrued test over a series of javascript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics. We report this final score.
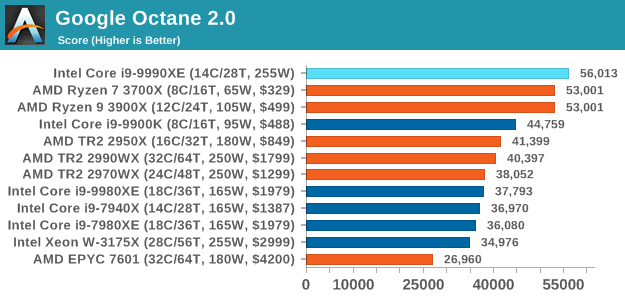
Google Octane 2.0: Core Web Compute
A popular web test for several years, but now no longer being updated, is Octane, developed by Google. Version 2.0 of the test performs the best part of two-dozen compute related tasks, such as regular expressions, cryptography, ray tracing, emulation, and Navier-Stokes physics calculations.
The test gives each sub-test a score and produces a geometric mean of the set as a final result. We run the full benchmark four times, and average the final results.
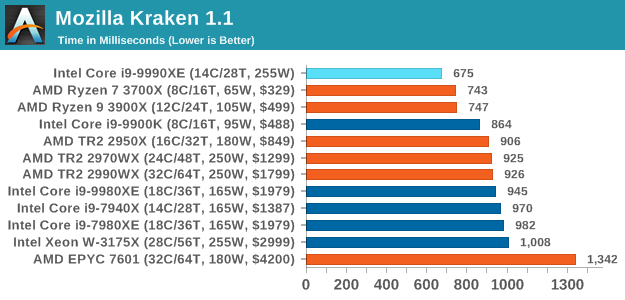
Mozilla Kraken 1.1: Core Web Compute
Even older than Octane is Kraken, this time developed by Mozilla. This is an older test that does similar computational mechanics, such as audio processing or image filtering. Kraken seems to produce a highly variable result depending on the browser version, as it is a test that is keenly optimized for.
The main benchmark runs through each of the sub-tests ten times and produces an average time to completion for each loop, given in milliseconds. We run the full benchmark four times and take an average of the time taken.
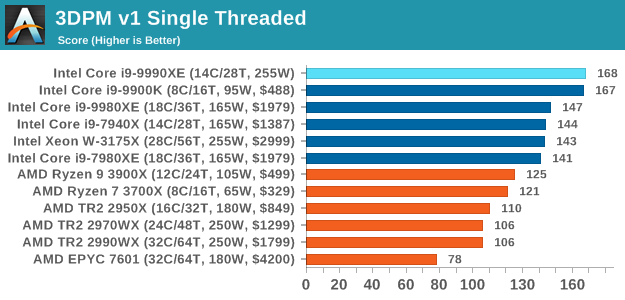
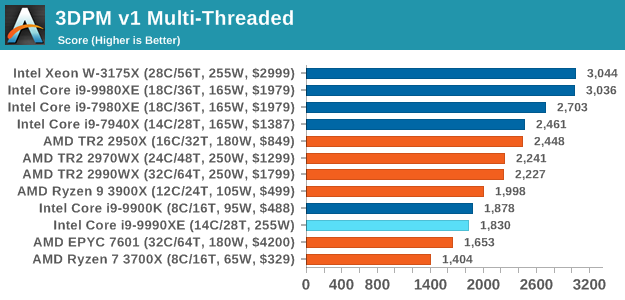
3DPM v1: Naïve Code Variant of 3DPM v2.1
The first legacy test in the suite is the first version of our 3DPM benchmark. This is the ultimate naïve version of the code, as if it was written by scientist with no knowledge of how computer hardware, compilers, or optimization works (which in fact, it was at the start). This represents a large body of scientific simulation out in the wild, where getting the answer is more important than it being fast (getting a result in 4 days is acceptable if it’s correct, rather than sending someone away for a year to learn to code and getting the result in 5 minutes).
In this version, the only real optimization was in the compiler flags (-O2, -fp:fast), compiling it in release mode, and enabling OpenMP in the main compute loops. The loops were not configured for function size, and one of the key slowdowns is false sharing in the cache. It also has long dependency chains based on the random number generation, which leads to relatively poor performance on specific compute microarchitectures.
3DPM v1 can be downloaded with our 3DPM v2 code here: 3DPMv2.1.rar (13.0 MB)
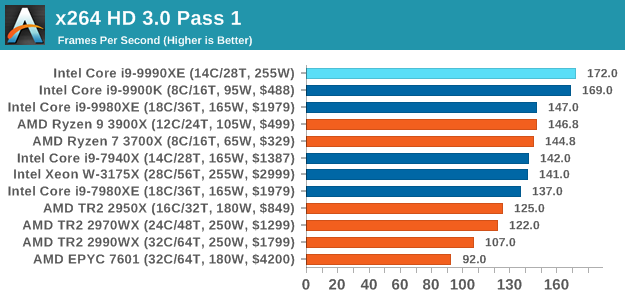
x264 HD 3.0: Older Transcode Test
This transcoding test is super old, and was used by Anand back in the day of Pentium 4 and Athlon II processors. Here a standardized 720p video is transcoded with a two-pass conversion, with the benchmark showing the frames-per-second of each pass. This benchmark is single-threaded, and between some micro-architectures we seem to actually hit an instructions-per-clock wall.
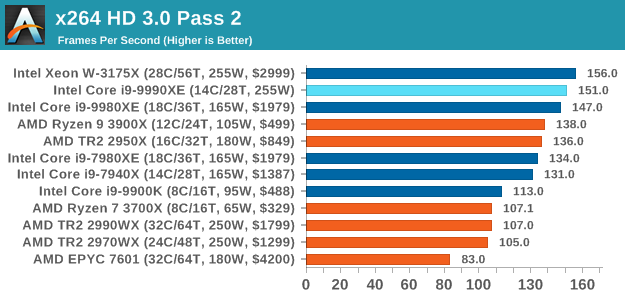








145 Comments
View All Comments
edzieba - Thursday, October 31, 2019 - link
An ASIC has a significant (many months to years) lead time between "we need X design" and functioning silicon. Trading algorithms are a constant arms race being updated to counter others' algorithm changes (who then counter your counters, etc) on the days to hours timescales.shtldr - Tuesday, October 29, 2019 - link
If you've got all the money (which you should, in case you are a successful algorithmic trader), why not go ASIC?Dribble - Monday, October 28, 2019 - link
It's not as simple as you need hundreds of threads or you need one. Compiling is an obvious example. You have a mixture of tasks - some take more threads (e.g. you have a large number of files in a makefile you can compile at once), some take less threads (you have a smaller makefile with only a few files), some take one thread (you need to link).A chip like this with 14 cores and very high single thread performance it turns out is ideal for this sort of task.
Compiling is very much not a niche market.
eek2121 - Monday, October 28, 2019 - link
Word (in the article) is that it helps with web browsing as well. So there is that. ;)That being said, I don't look at this CPU as being competitive to AMD offerings simply because you can't buy the thing. However it is nice to see that Intel can do something if they put their mind to it.
bananaforscale - Thursday, October 31, 2019 - link
Well, multiple cores *do* help with web browsing, doesn't mean you need 14@5 GHz. :DMattZN - Tuesday, October 29, 2019 - link
You don't need all those cores running on a single platform to do HFT. In fact, that winds up being a negative because all the cores are competing for memory cycles. Instead what you want to do is mirror (not split, but do a full mirror) the packet stream to a whole bunch of platforms with fewer cores which can then maximally leverage their memory bandwidth and CPU caches. You also filter the packets inside the NIC itself, not with the CPU.You also don't need to have a high-frequency CPU to minimize response time. The CPU is calculating outcomes from likely moves way ahead of time, long before actually receiving any packet telling it what movement actually happened. When the packet comes in, the CPU really only needs to look up the appropriate response from a table that has already been calculated. In fact, the NIC itself could do the table lookup for certain actions and bypass the CPU entirely.
So you want lots of cores, but they don't actually have to be ultra fast. Anyone using something like this processor to try to 'get ahead' in the HFT game is going to be in for a big surprise.
-Matt
Spunjji - Wednesday, October 30, 2019 - link
Thanks for the clarification. I thought that leaning on a single, many-core high-frequency CPU for this sort of task sounded a lot like optimising the wrong part of the whole process.peevee - Monday, October 28, 2019 - link
That's the point. It does not make them much money, the volume is simply not there. It is for INTEL's bragging.eek2121 - Monday, October 28, 2019 - link
They likely auction the chips due to the aggressive binning required. I expect if they could roll out this kind of chip easily, they would have already. Think: 10 chips for every 100,000 can do 4-5 GHz @ 14 cores, 255 watt TDP.lazarpandar - Monday, October 28, 2019 - link
So if you have an absurd amount of money and can't scale with more cores beyond 14...What a stupid product.