Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics
by Dr. Ian Cutress on September 17, 2019 10:00 AM ESTDefining Turbo, Intel Style
Since 2008, mainstream multi-core x86 processors have come to the market with this notion of ‘turbo’. Turbo allows the processor, where plausible and depending on the design rules, to increase its frequency beyond the number listed on the box. There are tradeoffs, such as Turbo may only work for a limited number of cores, or increased power consumption / decreased efficiency, but ultimately the original goal of Turbo is to offer increased throughput within specifications, and only for limited time periods. With Turbo, users could extract more performance within the physical limits of the silicon as sold.
In the beginning, Turbo was basic. When an operating system requested peak performance from a processor, it would increase the frequency and voltage along a curve within the processor power, current, and thermal limits, or until it hit some other limitation, such as a predefined Turbo frequency look-up table. As Turbo has become more sophisticated, other elements of the design come into play: sustained power, peak power, core count, loaded core count, instruction set, and a system designer’s ability to allow for increased power draw. One laudable goal here was to allow component manufacturers the ability to differentiate their product with better power delivery and tweaked firmwares to give higher performance.
For the last 10 years, we have lived with Intel’s definition of Turbo (or Turbo Boost 2.0, technically) as the defacto understanding of what Turbo is meant to mean. Under this scheme, a processor has a sustained power level, and peak power level, a power budget, and assuming budget is available, the processor will go to a Turbo frequency based on what instructions are being run and how many cores are active. That Turbo frequency is governed by a Turbo table.
The Turbo We All Understand: Intel Turbo
So, for example. I have a hypothetical processor that has a sustained power level (PL1) of 100W. The peak power level (PL2) is 150W*. The budget for this turbo (Tau) is 20 seconds, or the equivalent of 1000 joules of energy (20*(150-100)), which is replenished at a rate of 50 joules per second. This quad core CPU has a base frequency of 3.0 GHz, but offers a single core turbo of 4.0 GHz, and 2-core to 4-core of 3.5 GHz.
So tabulated, our hypothetical processor gets these values:
| Sustained Power Level | PL1 / TDP | 100 W |
| Peak Power Level | PL2 | 150 W |
| Turbo Window* | Tau | 20 s |
| Total Power Budget* | (150-100) * 20 | 1000 J |
| *Turbo Window (and Total Power Budget) is typically defined for a given workload complexity, where 100% is a total power virus. Normally this value is around 95% | ||
*Intel provides ‘suggested’ PL2 values and ‘suggested’ Tau values to motherboard manufacturers. But ultimately these can be changed by the manufacturers – Intel allows their partners to adjust these values without breaking warranty. Intel believes that its manufacturing partners can differentiate their systems with power delivery and other features to allow a fully configurable value of PL2 and Tau. Intel sometimes works with its partners to find the best values. But the take away message about PL2 and Tau is that they are system dependent. You can read more about this in our interview with Intel’s Guy Therien.
Now please note that a workload, even a single thread workload, can be ‘light’ or it can be ‘heavy’. If I created a piece of software that was a never ending while(true) loop with no operations, then the workload would be ‘light’ on the core and not stressing all the parts of the core. A heavy workload might involve trigonometric functions, or some level of instruction-level parallelism that causes more of the core to run at the same time. A ‘heavy’ workload therefore draws more power, even though it is still contained with a single thread.
If I run a light workload that requires a single thread, it will start the processor at 4.0 GHz. If the power of that single thread is below 100W, then I will use none of my budget, as it is refilled immediately. If I then switch to a heavy workload, and the core now consumes 110W, then my 1000 joules of turbo budget would decrease by 10 joules every second. In effect, I would get 100 seconds of turbo on this workload, and when the budget is depleted, the sustained power level (PL1) would kick in and reduce the frequency to ensure that the consumption on the chip stayed at 100W. My budget of energy for turbo would not increase, because the 100 joules/second that is being added is immediately taken away by the heavy workload. This frequency may not be the 3.0 GHz base frequency – it depends on the voltage/power characteristics of the individual chip. That 3.0 GHz base value is the value that Intel guarantees on its hardware – so every one of this hypothetical processor will be a minimum of 3.0 GHz at 100W on a sustained workload.
To clarify, Intel does not guarantee any turbo speed that is part of the specification sheet.
Now with a multithreaded workload, the same thing occurs, but you are more likely to hit both the peak power level (PL2) of 150W, and the 1000 joules of budget will disappear in the 20 seconds listed in the firmware. If the chip, with a 4-core heavy workload, hits the 150W value, the frequency will be decreased to maintain 150W – so as a result we may end up with less than the ‘3.5 GHz’ four-core turbo that was listed on the box, despite being in turbo.
So when a workload is what we call ‘bursty’, with periods of heavy and light work, the turbo budget may be refilled quicker than it is used in light workloads, allowing for more turbo when the workload gets heavy again. This makes it important when benchmarking software one after another – the first run will always have the full turbo budget, but if subsequent runs do not allow the budget to refill, it may get less turbo.
As stated, that turbo power level (PL2) and power budget time (Tau) are configurable by the motherboard manufacturer. We see that on enterprise motherboards, companies often stick to Intel’s recommended settings, but with consumer overclocking motherboards, the turbo power might be 2x-5x higher, and the power budget time might be essentially infinite, allowing for turbo to remain. The manufacturer can do this if they can guarantee that the power delivery to the processor, and the thermal solution, are suitable.
(It should be noted that Intel actually uses a weighted algorithm for its budget calculations, rather than the simplistic view I’ve given here. That means that the data from 2 seconds ago is weighted more than the data from 10 seconds ago when determining how much power budget is left. However, when the power budget time is essentially infinite, as how most consumer motherboards are set today, it doesn’t particularly matter either way given that the CPUs will turbo all the time.)
Ultimately, Intel uses what are called ‘Turbo Tables’ to govern the peak frequency for any given number of cores that are loaded. These tables assume that the processor is under the PL2 value, and there is turbo budget available. For example, here are Intel’s turbo tables for Intel’s 8th Generation Coffee Lake desktop CPUs.
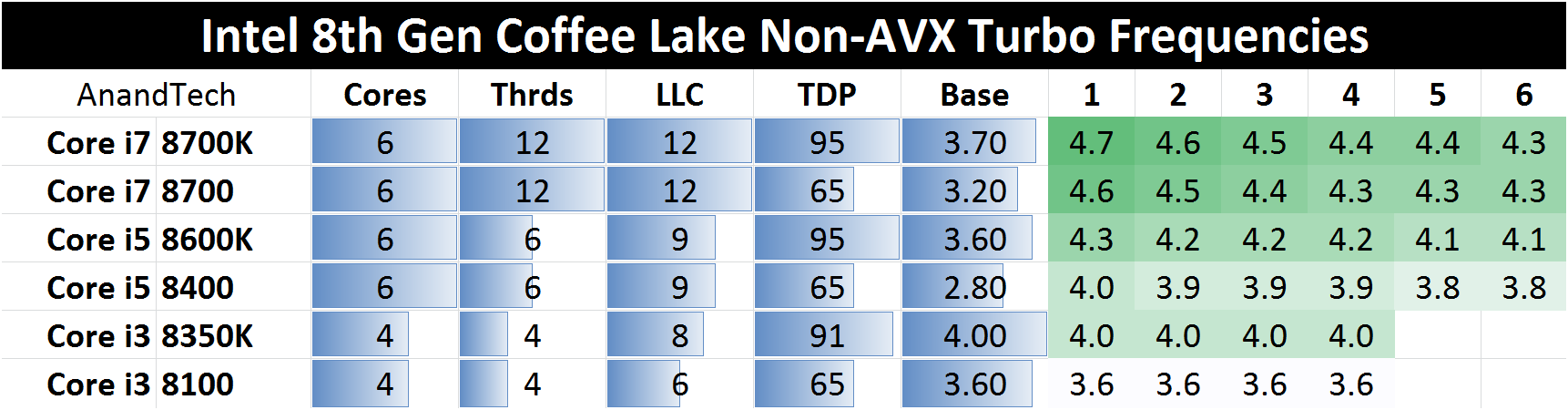
So Intel provides the sustained power level (PL1, or TDP), the Base frequency (3.70 GHz for the Core i7-8700K), and a range of turbo frequencies based on the core loading, assuming the motherboard manufacturer set PL2 isn’t hit and power budget is available.
The Effect of Intel’s Turbo Regime, and Intel’s Binning
At the time, Intel did a good job in conveying its turbo strategy to the press. It helped that staying on quad-core processors for several generations meant that the actual turbo power consumption of these quad-core chips was actually lower than sustained power value, and so we had a false sense of security that turbo could go on forever. With the benefit of hindsight, the nuances relating to turbo power limits and power budgets were obfuscated, and people ultimately didn’t care on the desktop – all the turbo for all the time was an easy concept to understand.
One other key metric that perhaps went under the radar is how Intel was able to apply its turbo frequencies to the CPU.
For any given CPU, any core within that design could hit the top turbo. It allowed for threads to be loaded onto whatever core was necessary, without the need to micromanage the best thread positioning for the best performance. If Intel stated that the single core turbo frequency was 4.6 GHz, then any core could go up to 4.6 GHz, even if each individual core could go beyond that.
For example, here’s a theoretical six-core Core i5-9600K, with a 3.7 GHz base frequency, and a 4.6 GHz turbo frequency. The higher numbers represent theoretical maximums of each core at the turbo voltage.
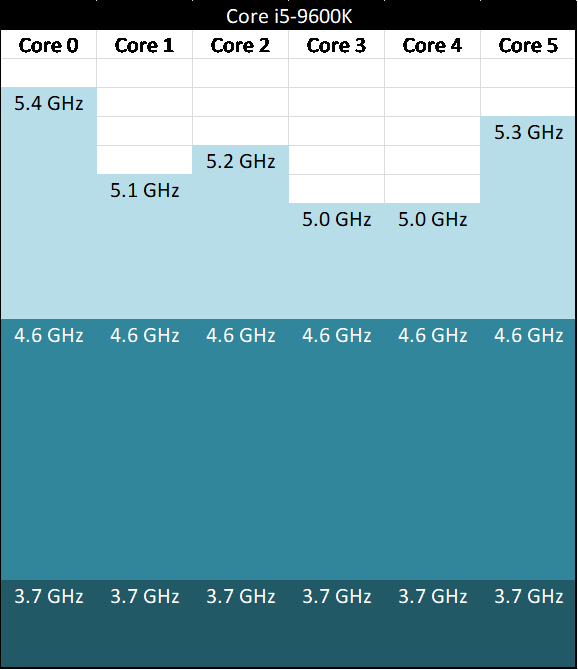
This is actually a strategy related to how Intel segments its CPUs after manufacturing, a process called binning. If a processor has the right power/thermal characteristics to reach a given frequency in a given power, then it could be labelled as the most appropriate CPU for retail and sold as such. Because Intel aimed for a homogeneous monolithic design, every core in the design was tested such that it performed equally (or almost equally) with every other core. Invariably some cores will perform better than others, if tweaked to the limits, but under Intel’s regime, it helped Intel to spread the workloads around as to not create thermal hotspots on the processor, and also level out any wear and tear that might be caused over the lifetime of the product. It also meant that in a hypervisor, every virtual machine could experience the same peak frequencies, regardless of the cores they used.
With binning, Intel (or any other company), is selecting a set of voltages and frequencies for a processor to which it is guaranteed. From the manufacturing, Intel (or others) can see the predicted lifespan of a given processor for a range of frequencies and voltages, and the ones that hit the right mark (based on internal requirements) means that a silicon chip ends up as a certain CPU. For example, if a piece of silicon does hit 9900K voltages and frequencies, but the lifespan rating of that piece of silicon is only two years, Intel might knock it down to a 9700K, which gives a predicted lifespan of fifteen years. It’s that sort of thing that determines how high a chip can perform. Obviously chips that can achieve high targets can also be reclassified as slower parts based on inventory levels or demand.
This is how the general public, the enthusiasts, and even the journalists and reviewers covering the market, have viewed Turbo for a long time. It’s a well-known part of the desktop space and to a large extent is easy to understand. If someone said ‘Turbo’ frequency, everyone was agreed on the same basic principles and no explanation was needed. We all assumed that when Turbo was mentioned, this is what they meant, and this is what it would mean for eternity.
Now insert AMD, March 2017, with its new Zen core microarchitecture. Everyone assumed Turbo would work in exactly the same way. It does not.








144 Comments
View All Comments
Smell This - Wednesday, September 18, 2019 - link
{ s-n-i-c-k-e-r }
BurntMyBacon - Wednesday, September 18, 2019 - link
Electron migration is generally considered to be the result of momentum transfer from the electrons, which move in the applied electric field, to the ions which make up the lattice of the interconnect material.Intuitively speaking, raising the frequency would proportionally increase the number of pulses over a given time, but the momentum (number of electrons) transferred per pulse would remain the same. Conversely, raising the voltage would proportionally increase the momentum (number of electrons) per pulse, but not the number of pulses over a given time. To make an analogy, raising the frequency is like moving your sandpaper faster while raising your voltage is like using coarser grit sandpaper at the same speed.
You might assume that if the total number of electrons are the same, then the wear will be the same? However, there is a certain amount of force required to dislodge an atom (or multiple atoms) from the interconnect material lattice. Though the concept is different, you can simplistically think of it like stationary friction. Increasing the voltage increases the force (momentum) from each pulse which could overcome this resistance where nominal voltages may not be enough. Also, increasing voltage has a larger affect on heat produced than increasing frequency. Adding heat energy into the system may lower the required force to dislodge the atom(s). If the nominal voltage is unable or only intermittently able to exceed the required force, then raising the frequency will have little effect compared to raising the voltage. That said, continuous strain will probably weaken the resistance over time, but it is likely that this still less significant than increasing voltage. Based on this, I would expect (read my opinion) four things:
1) Electron migration becomes exponentially worse the farther you exceed specifications (Though depending on where your initial durability is it may not be problematic)
2) The rate of electron migration is not constant. Holding all variables constant, it likely increases over time. That said, there are likely a lot of process specific variables that determine how quickly the rate increases.
3) Increasing voltage has a greater affect on electron migration than frequency. Increasing frequency alone may be considered far more affordable from a durability standpoint than increases that require significant voltage.
4) Up to a point, better cooling will likely reduce electron migration. We are already aware that increased heat physically expands the different materials in the semiconductor at different rates. It is likely that increased heat energy in the system also makes it easier to dislodge atoms from their lattice. Reducing this heat build-up should lessen the effect here.
Some or all of these may be partially or fully incorrect, but this is where my out of date intuition from limited experience in silicon fabrication takes me.
eastcoast_pete - Wednesday, September 18, 2019 - link
Thanks Ian! And, as mentioned, would also like to hear from you or Ryan on the same for GPUs. With lots of former cryptomining cards still in the (used) market, I often wonder just how badly those GPUs were abused in their former lifes.nathanddrews - Tuesday, September 17, 2019 - link
My hypothesis is that CPUs are more likely to outlive their usefulness long before a hardware failure. CPUs failing due to overclocking is not something we hear much about - I'm thinking it's effectively a non-issue. My i5-3570K has been overclocked at 4.2GHz on air for 7 years without fault. I don't think it has seen any time over 60C. That said, as a CPU, it has nearly exhausted its usefulness in gaming scenarios due to lack of both speed and cores.What would cause a CPU to "burn out" that hasn't already been accounted for via throttling, auto-shutdown procedures, etc.?
dullard - Tuesday, September 17, 2019 - link
Thermal cycling causes CPU damage. Different materials expand at different rates when they heat, eventually this fatigue builds up and parts begin to crack. The estimated failure rate for a CPU that never reaches above 60°C is 0.1% ( https://www.dfrsolutions.com/hubfs/Resources/servi... ). So, in that case, you are correct that your CPU will be just fine.But, now CPUs are reaching 100°C, not 60°C. That higher temperature range doubles the temperature range the CPUs are cycling through. Also, with turbo kicking on/off quickly, the CPUs are cycling more often than before. https://encrypted-tbn0.gstatic.com/images?q=tbn:AN...
GreenReaper - Wednesday, September 18, 2019 - link
Simple solution: run BOINC 24/7, keeps it at 100°C all the time!I'm sure this isn't why my Surface Pro isn't bulging out of its case on three sides...
Death666Angel - Thursday, September 19, 2019 - link
Next up: The RGB enabled hair dryer upgrade to stop your precious silicon from thermal cycling when you shut down your PC!mikato - Monday, September 23, 2019 - link
Now I wonder how computer parts had an RGB craze before hair dryers did. Have there been andy RGB hair dryers already?tygrus - Saturday, September 28, 2019 - link
The CPU temperature sensors have changed type and location. Old sensors were closer to the surface temperature just under the heatsink (more of an average or single spot assumed to be the hottest). Now its the highest of multiple sensors built into the silicon and indicates higher temperatures for the same power&area than before. There is always a temperature gradient from the hot spots to where heat is radiated.eastcoast_pete - Wednesday, September 18, 2019 - link
For me, the key statement in your comment is that your Sandy Bridge i7 rarely if ever went above 60 C. That is a perfectly reasonable upper temperature for a CPU. Many current CPUs easily get 50% hotter, and that's before any overclocking and overvolting. For GPUs, it even worse; 100 - 110 C is often considered "normal" for "factory overclocked" cards.