Hot Chips 31 Live Blogs: Cerebras' 1.2 Trillion Transistor Deep Learning Processor
by Dr. Ian Cutress on August 19, 2019 9:45 PM EST
08:49PM EDT - Some of the big news of today is Cerebras announcing its wafer-scale 1.2 trillion transistor solution for deep learning. The talk today goes into detail about the technology.

08:51PM EDT - Wafer scale chip, over 46,225 mm2, 1.2 trillion transistors, 400k AI cores, fed by 18GB of on-chip SRAM

08:51PM EDT - TSMC 16nm
08:51PM EDT - 215mm x 215mm - 8.5 inches per side
08:51PM EDT - 56 times larger than the largest GPU today
08:52PM EDT - Built for Deep Learning
08:52PM EDT - DL training is hard (ed: this is an understatement)

08:52PM EDT - Peta-to-exa scale compute range
08:53PM EDT - The shape of the problem is difficult to scale
08:53PM EDT - Fine grain has a lot of parallelism
08:53PM EDT - Coarse grain is inherently serial
08:53PM EDT - Training is the process of applying small changes, serially
08:53PM EDT - Size and shape of the problem makes training NN really hard

08:53PM EDT - Today we have dense vector compute
08:54PM EDT - For Coarse Grained, require high speed interconnect to run mutliple instances. Still limited
08:54PM EDT - Scaling is limited and costly
08:54PM EDT - Specialized accelerators are the answer

08:55PM EDT - NN: what is the right architecture
08:55PM EDT - Need a core to be optimized for NN primitives

08:55PM EDT - Need a programmable NN core
08:55PM EDT - Needs to do sparse compute fast
08:55PM EDT - Needs fast local memory
08:55PM EDT - All of the cores should be connected with a fast interconnect
08:56PM EDT - Cerebras uses flexible cores. Flexible general ops for control processing

08:56PM EDT - Core should handle tensor operations very efficiency
08:56PM EDT - Forms the bulk fo the compute in any neural network
08:56PM EDT - Tensors as first class operands
08:57PM EDT - fmac native op
08:57PM EDT - NN naturally creates sparse networks

08:58PM EDT - The core has native sparse processing in the hardware with dataflow scheduling
08:58PM EDT - All the compute is triggered by the data
08:58PM EDT - Filters all the sparse zeros, and filters the work
08:58PM EDT - saves the power and energy, and get performance and acceleration by moving onto the next useful work
08:58PM EDT - Enabled because arch has fine-grained execution datapaths
08:58PM EDT - Many small cores with independent instructions
08:59PM EDT - Allows for very non-uniform work
08:59PM EDT - Next is memory

08:59PM EDT - Traditional memory architectures are not optimized for DL
08:59PM EDT - Traditional memory requires high data reuse for performane
09:00PM EDT - Normal matrix multiply has low end data reuse
09:00PM EDT - Translating Mat*Vec into Mat*Mat, but changes the training dynamics
09:00PM EDT - Cerebras has high-perf, fully distributed on-chip SRAM next to the cores
09:01PM EDT - Getting orders of magnitude higher bandwidth

09:01PM EDT - ML can be done the way it wants to be done
09:01PM EDT - High bandwidth, low latency interconnect

09:01PM EDT - fast and fully configurable fabric
09:01PM EDT - all hw based communication avoicd sw overhead
09:02PM EDT - 2D mesh topology
09:02PM EDT - higher utlization and efficiency than global topologies
09:02PM EDT - Need more than a single die
09:02PM EDT - Solition is a wafer scale
09:03PM EDT - Build Big chips
09:03PM EDT - Cluster scale perf on a single chip

09:03PM EDT - GB of fast memory (SRAM) 1 clock cycle from the core
09:03PM EDT - That's impossible with off-chip memory
09:03PM EDT - Full on-chip interconnect fabric
09:03PM EDT - Model parallel, linear performance scaling
09:04PM EDT - Map the entire neural network onto the chip at once
09:04PM EDT - One instance of NN, don't have to increase batch size to get cluster scale perf
09:04PM EDT - Vastly lower power and less space

09:04PM EDT - Can use TensorFlow and PyTorch
09:05PM EDT - Performs placing and routing to map neural network layers to fabric
09:05PM EDT - Entire wafer operates on the single neural network
09:05PM EDT - Challenges of wafer scale
09:05PM EDT - Need cross-die connectivity, yield, thermal expansion


09:06PM EDT - Scribe line separates the die. On top of the scribe line, create wires
09:07PM EDT - Extends 2D mesh fabric across all die
09:07PM EDT - Same connectivity between cores and between die
09:07PM EDT - More efficient than off-chip

09:07PM EDT - Full BW at the die level
09:08PM EDT - Redundancy helps yield

09:08PM EDT - Redundant cores and redundant fabric links
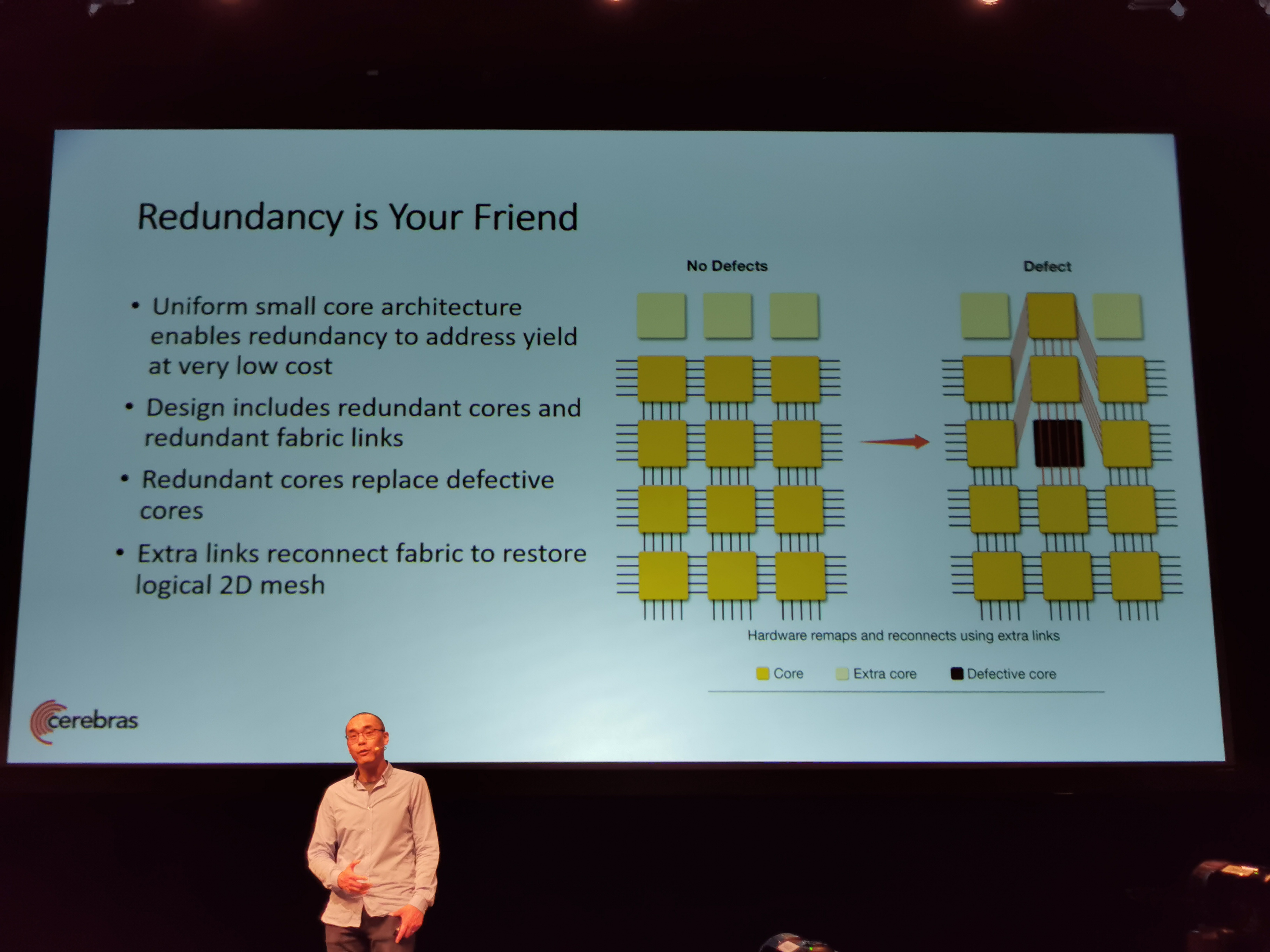
09:08PM EDT - Reconnect the fabric with links
09:08PM EDT - Drive yields high
09:09PM EDT - Transparent to software
09:09PM EDT - Thermal expansion

09:09PM EDT - Normal tech, too much mechanical stress via thermal expansion
09:09PM EDT - Custom connector developed
09:09PM EDT - Connector absorbs the variation in thermal expansion

09:10PM EDT - All components need to be held with precise alignment - custom packaging tools

09:10PM EDT - Power and Cooling

09:11PM EDT - Power planes don't work - isn't enough copper in the PCB to do it that way
09:11PM EDT - Heat density too high for direct air cooling
09:12PM EDT - Bring current perpendicular to the wafer. Water cooled perpendicular too


09:14PM EDT - Q&A Time

09:14PM EDT - Q and A
09:14PM EDT - Already in use? Yes
09:15PM EDT - Can you make a round chip? Square is more convenient
09:15PM EDT - Yield? Mature processes are quite good and uniform
09:16PM EDT - Does it cost less than a house? Everything is amortised across the wafer
09:17PM EDT - Regular processor for housekeeping? They can all do it
09:17PM EDT - Is it fully synchronous? No
09:20PM EDT - Clock rate? Not disclosed
09:20PM EDT - That's a wrap. Next is Habana








28 Comments
View All Comments
Threska - Tuesday, August 20, 2019 - link
Sheriff Brody: You gonna need a bigger heatsink.vladpetric - Thursday, August 22, 2019 - link
There is actually very little benefit to this approach.The reason is simple - power consumption. Not mentioned in the article is that the chip takes a whooping 15 KW! You need insane refrigeration to keep something like this working. This is primarily why you don't get more CPU cores per chip - power density.
It's not that these people have leapfrogged Intel or AMD in any way - the approach is simply impractical for the vast majority of applications.
Now are there actual benefits to the close clustering of the chips? Absolutely, the latency between cores is really small. How much does that matter ... well, it greatly depends on the workload.
jospoortvliet - Saturday, August 24, 2019 - link
In case of ML it might very well make sense... bandwidth seems to be the limiting factor in training, which means it needs a lot of bw - which means it eats a lot of power not doing compute but moving data around. This design cuts down on those power costs so it might very well out-perform a 30kw cluster worth of smaller accelerators which all waste loads of power just pumping data around.twtech - Saturday, August 31, 2019 - link
15KW sounds like a lot, but with 400k cores, it's only 0.0375 watts per core.biohazard918 - Friday, September 6, 2019 - link
Core should be in quotes. Its is basically a shader unit. Still power consumption looks like it is in the ballpark of reasonable. If you go based on "core" count this thing is 78 titan v's. Which works out to 192 watts per titan equivalent. Obviously this is an extreme simplification but it shows how the math can work. 15kw sounds like a lot but if it is replacing dozens of gpus and their host systems it can still come out on top in terms of efficiency.They are also claiming water cooling is sufficient and I don't see any reason to doubt them on that. Thermal density should be similar to a gpu but an air cooler just isn't going to scale well to something that large. Water shouldn't have that problem.
peevee - Thursday, August 29, 2019 - link
2 obvious things which should have been done 10 years ago but big companies are too conservative):+ in-memory computing
+ wafer-scale (it is idiotic to cut wafers for datacenters)
- not general-purpose, limited market, high fixed cost proportion.
Greys - Wednesday, August 26, 2020 - link
Just one microcircuit per plate? Incredible. I think this is a step into the future. I admire scientists and inventors. I wonder which university you need to enter and what stages of preparation and education you need to go through in order to become a specialist and invent a deep learning processor. I know a service https://www.sopservices.net/sop-writing-services/ which will help to prepare a personal application for admission, but the further success of the training already depends on each of us. To invent something is incredible success.WilliamErups - Thursday, July 29, 2021 - link
Alter your key pad font on Instagram to produce your pictures seem far better. It functions in most programs: Intuition, Instagram, Whatsapp and so forth https://fontsprokeyboard.com/lingojam-fonts-for-in...">https://fontsprokeyboard.com/lingojam-fonts-for-in... This instagram keyboard tweak is a cost-free instagram keyboard package. The typefaces job everywhere in any application also. Just mount the mobile app and enable the keyboard adjust your computer keyboard settings.Use instagram typefaces generator to create stunning fonts instantaneously. It's an easy option for those who aren't great at creating and do not have enough time to test out difficult shapes and fashoins. Instagram typefaces electrical generator enables you to pick from many different fonts instantly. Use the convenient device to choose your favourite shape and size then obtain the font set up on instagram. You may individualize your instagram textual content by using this instagram fonts power generator. Instagram typefaces are easily available on internet so you can get the trendy typeface you would like for instagram.
Instagram keyboard is amongst the most cherished and the majority of used instagram resources. Each and every customer in the social media foundation uses it in a different way https://apps.apple.com/app/id1503238062">find here Nonetheless, this brilliant computer keyboard will make it much more intriguing and easier for end users. There are many things you can do with this particular typefaces computer keyboard inside the app and so that you can increase its power, this is a list of handful of suggestions.
Receive the wanted font for instagram from your instagram fonts art gallery. There are numerous of typefaces readily available for cost-free within the instagram fonts gallery. You can opt for any of them based on your choice and as outlined by your require. Even so, you need to continue to keep one important thing in mind. While choosing any of the typefaces, you should always go for those who are without charge as the ones that are paid are of no use in creating your information appealing.
Consumption of instagram fonts within each iphone app and in all programs including Twitter and facebook is greatly increasing. Many people like to use this particular computer keyboard to enable them to make their information far more interesting. The reason why the majority of people like instagram is its vibrant and different look. Every person feels like publishing anything exclusive on instagram. To make your profile a lot more exclusive, you can consider to utilize several of the special fonts within every mobile app.
It is possible to alter your computer keyboard fonts manually by downloading them online or you can even buy them manually mounted on your computer by browsing various websites supplying typeface typefaces without charge. There are numerous of websites offered that offer cost-free fonts for usage in every programs which include instagram. This way, you are able to make positive changes to key pad typefaces anytime and anywhere you need. These fonts are extremely simple to put in on your computer system and also it is possible to download it directly from a certain site.
Installing typefaces on your pc is not difficult. Just click on the typeface typefaces and also the proper site will unlock. There you can opt for the kind and scale of the font which you prefer to use in the apps. The majority of the font keyboards permits the person to make use of only one kind of font in the apps along with the customer also can modify them as many times he/she wants.
Key-board is a great device that permits you to make unique and eye-catching pictures, text messages and images. Should you be an instagram user, you need to have observed the many graphics uploaded by various end users. Everybody utilizes instagram for different uses. Nonetheless, none is aware the importance of instagram typefaces. So, if you wish to have more consideration and make amazing images with instagram, change your keyboard font in the instagram app and save your time and money.