Hot Chips 31 Analysis: In-Memory Processing by UPMEM
by Dr. Ian Cutress on August 19, 2019 3:15 PM EST
One of the key critical future elements about this world of compute is moving data about. Moving data requires power, to the point where calling data from memory can consume more power than actually doing ‘compute’ work on it. This is why we have caches, but even these require extensive management built in to the CPU. For simple operations, like bit-shifts or AND operations, the goal is to move the ability to do that compute onto the main DRAM itself, so it doesn’t have to shuttle back and forth. This year at Hot Chips, UPMEM is one of the first companies to showcase their new technology.
For anyone that has done any form of general purpose compute, pushing a bunch of inputs through an algorithm to get a result, and for those that have written the code, there are typically two high-level mental stages to conquer: first is getting it to work, and second is optimizing it. The algorithm needs to produce the correct result, and the faster the better – a slow correct result often isn’t useful, and a fast incorrect result is useless. If it can be done in less power, than that also decreases overhead.
The idea behind In-Memory Processing, or ‘Processing In-Memory’, is that a number of those simple integer or floating point operations should be done while the memory is still in DRAM – no need to cart it over to the CPU, do the operation, and then send it back. If the data can stay there and be updated, this saves time and power without affecting the result. Alternatively, perhaps compute on the CPU can be reduced if results are sent back out to main memory and a final XOR is applied to the data in memory. That frees up the main CPU core to do other compute related things, or reduces the effective memory bandwidth should it be a limiting factor.
What UPMEM has done is develop a data processing unit (DPU) that is built into the DRAM chip itself, on the DRAM process node. Each DPU has access to 64 MB of DRAM, and has the equivalent of 1 GB/s bandwidth to that memory. The DPU is built on a clean 32-bit ISA with a raft of optimizations, such 0-cycle conditional jmps, combined SHIFT+X instructions (such as SHIFT+ADD or SHIFT+SUB), basic logic instructions, shift and rotate instructions. The programming model is such that C-based libraries are in play taking care of all the common issues, and UPMEM expects for most apps for it to require a few hundred lines of code and a team of a handful of people need only take 2-4 weeks to update the software.
The big numbers that UPMEM are quoting involve better TCO, better ROI, and a potential target market of $10B. We’ll go through these in due course.
Processing In-Memory DRAM, or PIM-DRAM
(Personally I prefer the name PIM-DIMM, but oh well)
What UPMEM is proposing is a standard DDR4 RDIMM like product for which each 64 MB of memory has access to one of its DPUs. The DPU is built into the DRAM itself, using the manufacturing node that the memory is made in. For example, UPMEM is promoting that it is making a 4 Gb DDR4-2400 chip to be used in modules that embeds 8 DPUs in 512 MB, with the DPUs running at 500 MHz. UPMEM plans to put 16 of these 4 Gb chips onto a single DDR4 RDIMM module, providing an 8 GB module with 128 DPUs inside.
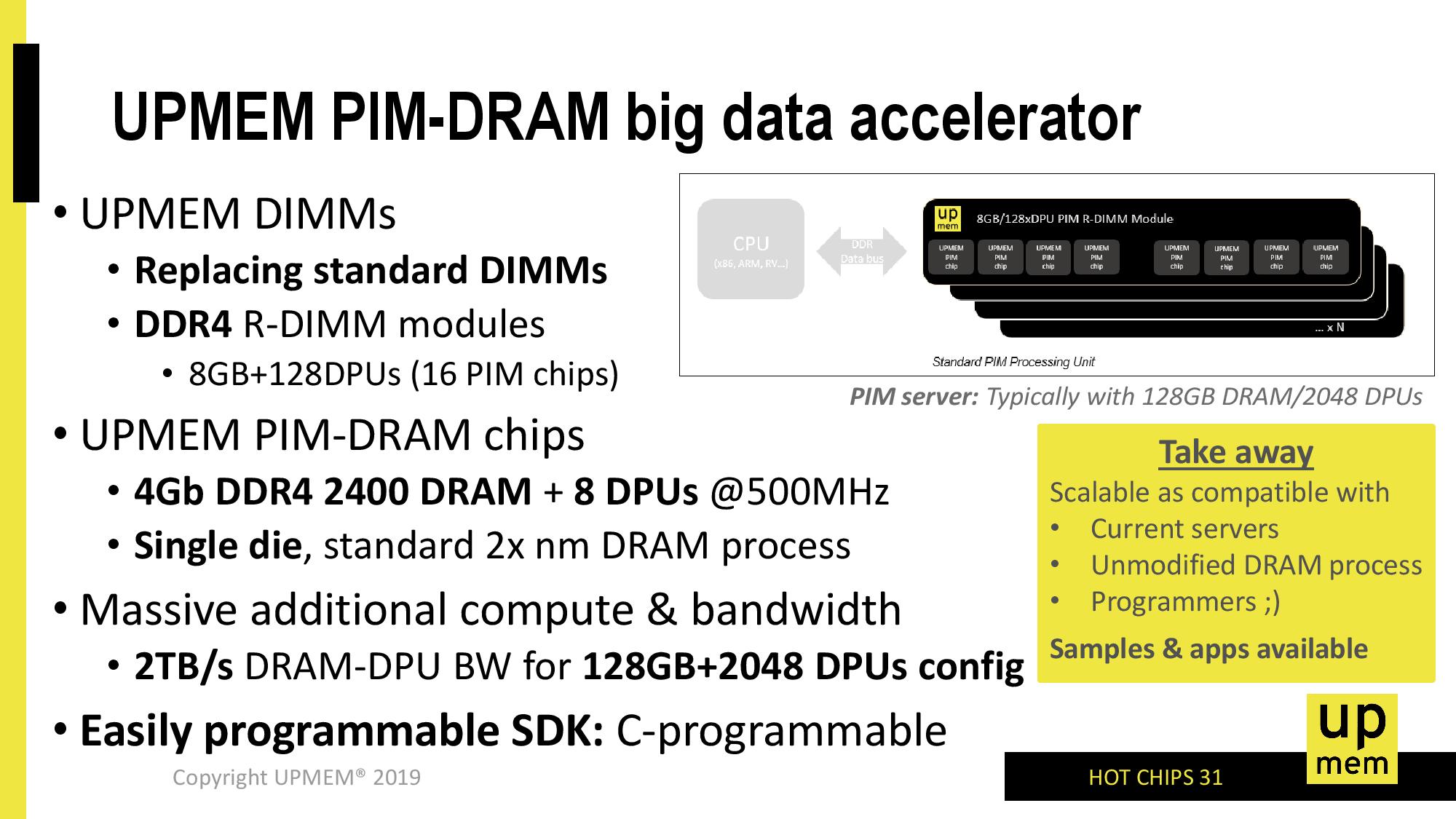
The goal is to eventually produce 128 GB modules with 2048 DPUs in total. At an effective 1 GB/s bandwidth between a DPU and its 64 MB of memory, this would imply an effective 2 TB/s bandwidth between the DPUs and memory. This is needed due to the way the DPU works, which is explained below.
The processor and technology are patented, but UPMEM has stated that they are working with a memory vendor on a 20-nm class process. Adding in the DPU cores adds a very negligible amount of die area, and can be enabled within 2-3 metal layers, as the logic is a magnitude less dense than a leading edge logic implementation. The idea is to achieve a total energy efficiency of 10x combined with scalability, compared to the leading CPU implementations.
Currently UPMEM has software simulations and hardware FPGA verification simulators for customers – in fact, interested parties can emulate the UPMEM platform on an AWS f1.16x large instance. Actual PIM-DRAM module samples are shipping to high profile customers in Q3, with a plan to ramp through the next year as more parties are interested and get on-board. Citing performance examples, UPMEM has stated that they have seen speedups of 22x—25x on Genomics pattern matching, an 18x speed up in throughput for database index searching at 1/100th the latency, and an 14x TCO gain for index search applications.

On the side of cost, UPMEM hasn’t stated how much it plans to sell its technology for, but promise to be a marginal cost compared to alternative solutions. In one presentation, the company stated that their solution can replace a potential $40000 server with a $400 enhanced memory solution, noting that using PIM has knock-on effects for software licensing, datacenter space, and power consumption/efficiency.
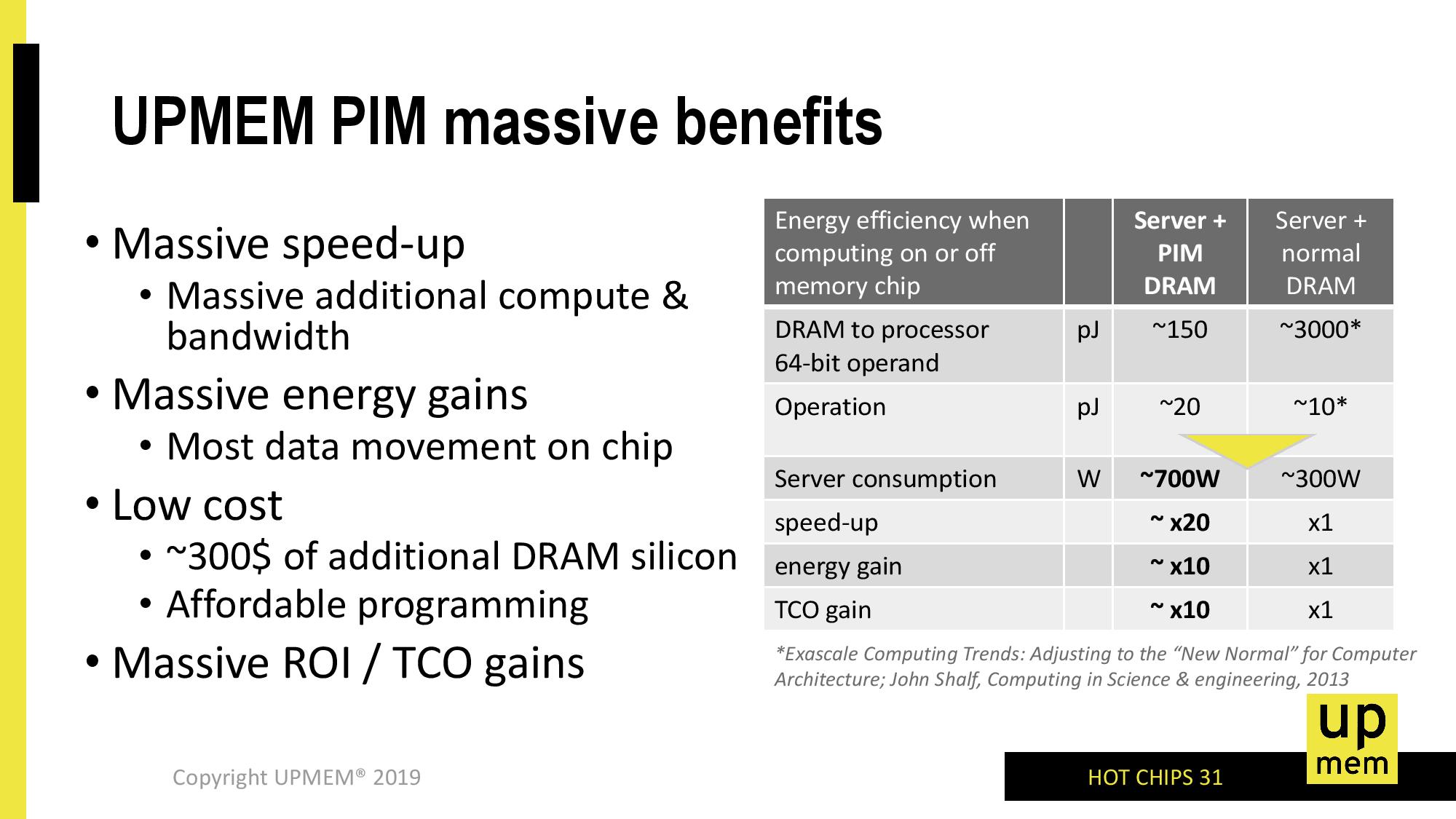
UPMEM puts some data on that power consumption. In this slide, the company compares two servers, one with PIM-DRAM and one without. In this case, a ‘DRAM to processor 64-bit operand’ recall requires 3000 pJ on a regular server, pulling the data out of DRAM and through to the caches, whereas the same operation on PIM-DRAM where it only has to move the data onto a DPU takes only 150 pJ of energy. The operation itself on the DPU actually requires 2x the power (20 pJ compared to 10 pJ), but the overall gain in power efficiency is 170 pJ vs 3010 pJ, or just under 20x.
One thing that this slide states that might be confusing is the server power consumption – the regular server is listed as only 300W, but the PIM solution is up to 700W. This is because the power-per-DRAM module would increase under UPMEM’s solution.
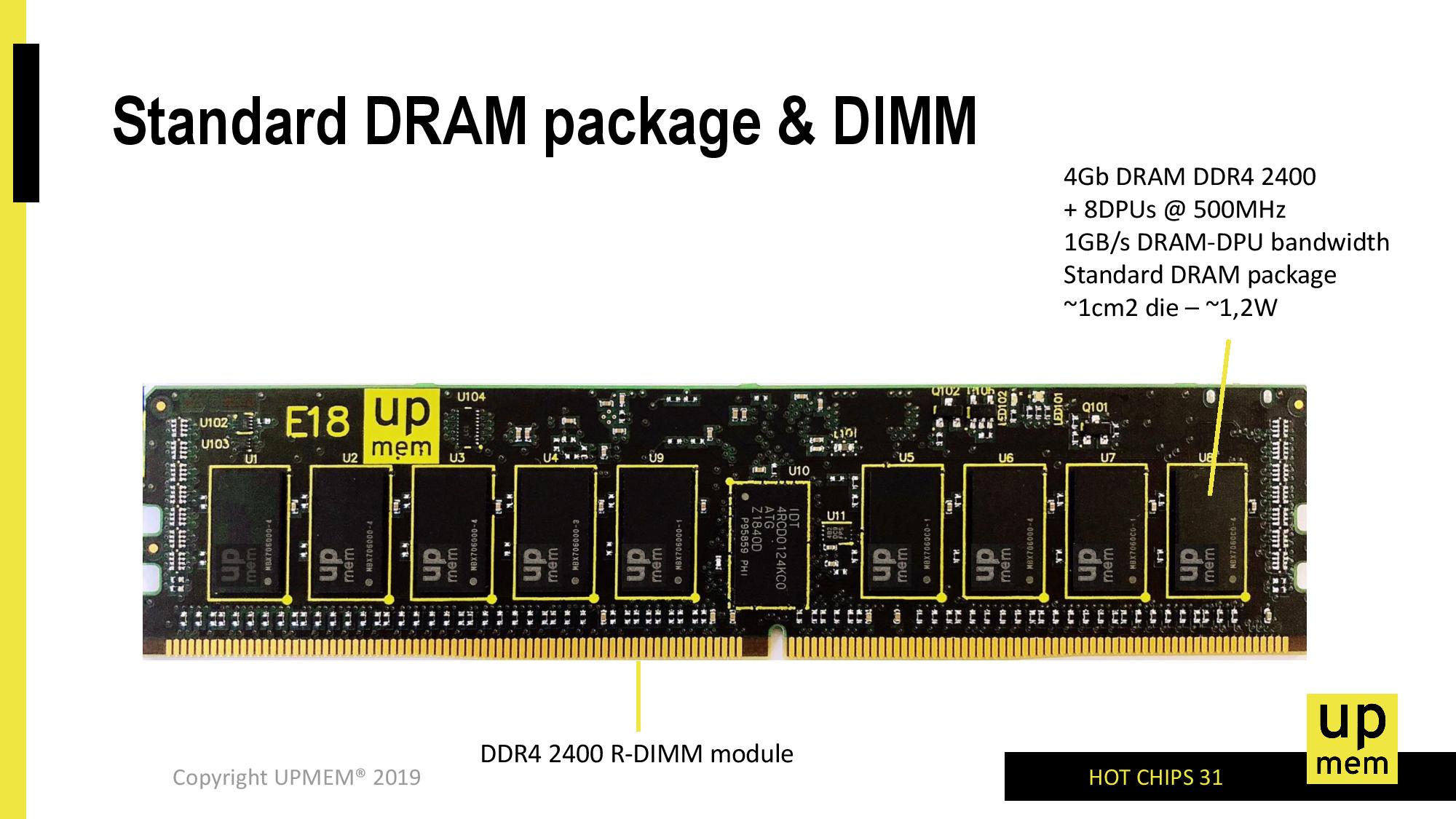
The module that UPMEM is proposing as its first product is that 8 GB DDR4-2400 module mentioned previously, with 128 DPUs each covering 64 MB of memory and running at 500 MHz. For a single 4 Gb die (there are 16 of them in an 8 GB module, 18 for RDIMM ECC), we are still at a regular 1 cm2 die size but the power required per chip is ~1.2 watts.
If we go into all 16/18 chips, we can see that each 8GB module is going to be in the 19.2-21.6 watts. That’s a lot of power for DRAM, and actually pushes up against the limit of what a DDR4 slot is often rated for. To put some perspective here, Intel’s 512 GB Optane module has an 18 W running mode for servers that can cool that much, but can run as low as 12 W. UPMEM hasn’t stated if it offers the ability for its customers to scale down the power per module by reducing the DPU frequency.
UPMEM’s goal is to replace DRAM modules in servers with PIM-DRAM modules as drop-in replacements. The company states that the DDR4 interface isn’t the best for this sort of thing, but they have worked around it. In one presentation, the company notes that at present there needs to be non-PIM-DRAM installed at a minimum for an OS.








38 Comments
View All Comments
philehidiot - Wednesday, August 21, 2019 - link
Kill joy. But thanks for playing along with my drunken, technically illiterate comments.FunBunny2 - Tuesday, August 20, 2019 - link
"The idea behind In-Memory Processing, or ‘Processing In-Memory’, is that a number of those simple integer or floating point operations should be done while the memory is still in DRAM – no need to cart it over to the CPU, do the operation, and then send it back."FWIW, back in the late 70s TI built a mini, and later a chip with the ISA, which had only a couple of registers. One was an instruction pointer another was the context pointer and perhaps one or two more. All instructions were executed on memory resident data. Deja Vu all over again.
SaberKOG91 - Friday, August 23, 2019 - link
Those were stack machines and were quickly replaced by virtual machines running on RISC processors for efficiency sake. In Flynn's Taxonomy these fall more into the category of MIMD (Multiple Instruction Multiple Data) machines, whereas stack machines are SISD (Single-Instruction Single Data) machines. These chips are basically a modern take on the Stanford VIRAM processors from the late 90's early 00's. Their biggest advantage has to do with not needing to swap RAM in and out of caches to access all of it. If you could bypass the data caches and directly access RAM from the CPU you may incur higher latencies, but the energy cost wouldn't be as bad as you might think.abufrejoval - Tuesday, August 27, 2019 - link
The TMS9900 microprocessor did indeed use a RAM based register file to save CPU transistors while supporting a full 16-bit architecture in those 8-bit days. But that was only possible because even the simplest instructions typically took several clock cycles to complete back then so the overhead of accessing a RAM based register file didn't matter that much if any: Operating on RAM didn't slow computation, truly justifying the Random Access Memory name. Today RAM is the new tape even with 3-4 levels of cache memory.In the case of the TMS9900 data did actually get carried back and forth twice as often, as it as transferred over a multiplexed 8-bit RAM bus to the non-multiplexed 16-bit 256 Byte scratchpad RAM that represented the register file and then would do ALU operations with CPU-RAM read-write operations only to transfer the results back to ordinary RAM afterwards.
TI lost $111 on that venture, perhaps another reason not to repeat that approach.
blacklion - Friday, August 23, 2019 - link
I wonder, how memory allocation is done from point of veiw of Host?They write: work is submitted to DPU via some OS driver. Ok, this part is clear.
But it is only half of the story. DPUs works with physical memory. User-level code (on host processor) works with virtual addresses. So, to prepare task for DPU it needs to know virtual to physical translation, which is typically not allowed for user programs.
And even worse: it needs to allocate chunks of memory in contiguous physical (not virtual!) address space. Again, typical OSes doesn't have such API.
Example: we want to add two arrays of float32 and store result into third. Let say for sake of simplicity, each source array is 16MiB. So, we need to allocate 3 chunks of 16MiB in SAME 64MiB PHYSICAL SPACE to be able to process this data with DPUs! As far as I know, no general-purpose OS supports such allocations!
And it could not be solved with "simple driver", it is changes to very heart of virtual memory subsystem of OS.
I can not find anything about this part in slide deck :(
TomWomack - Thursday, August 29, 2019 - link
That's exactly the same problem as allocating memory on GPU, though at least accessing the memory from the CPU requires only (careful - the CPU cache hierarchy doesn't know about the processors in the memory!) cache invalidation rather than trips over a PCIe bus.ThopTv - Wednesday, August 28, 2019 - link
One of the key critical future elements about this world of compute is moving data about. Moving data requires power, to the point where calling data fromSenbon-Sakura - Thursday, November 18, 2021 - link
As the large bandwidth of DRAM, I guess the vector instructions will achieve more gains for upmem, but why only the scalar instructions are supported in it?