The Ice Lake Benchmark Preview: Inside Intel's 10nm
by Dr. Ian Cutress on August 1, 2019 9:00 AM EST- Posted in
- CPUs
- Intel
- GPUs
- 10nm
- Core
- Ice Lake
- Cannon Lake
- Sunny Cove
- 10th Gen Core
Cache and TLB Updates
One of the biggest changes in the new Sunny Cove core is the cache hierarchy. Throughout most of the last decade, Intel has kept the same cache configuration among its server cores with very few changes, aside from improving the micro-op cache through Sandy Bridge today, but with Sunny Cove, we get some key updates.
From our microarchitecture disclosure article, we know that Sunny Cove brings with it an increased L1 data cache, as well as a doubled L2 cache, from Skylake. With this comes more associativity as well.
| Core Cache Comparison | ||||||
| Sunny Cove |
AnandTech | Cannon Lake |
Skylake | Sandy Bridge |
AMD Zen 2 |
|
| 48 KB 12-way |
L1-D | 32 KB 8-way |
32 KB 8-way |
32 KB 8-way |
32 KB 8-way |
|
| 32 KB 8-way |
L1-I | 32 KB 8-way |
32 KB 8-way |
32 KB 8-way |
32 KB 8-way |
|
| 512 KB 8-way |
L2 | 256 KB 4-way |
256 KB 4-way |
256 KB 8-way |
512 KB 8-way |
|
| 2 MB 16-way |
L3/core | 2 MB 16-way |
2 MB 16-way |
2MB 16-way |
4 MB 16-way |
|
| 2304 | uOp Cache | 1536 | 1536 | 1536 | 4096 | |
I’ve also included the size of the micro-op cache in this comparison, because we understand that the L1-I and the micro-op cache are typically located next to each other in the die design – increasing the size of one typically means limiting the size of the other, however given that both of them work to accelerate the same types of data, it is important to find the right balance: AMD for Zen 2 decided to halve the L1-I and double its associativity, and then double the micro-op cache from 2k to 4k entries. For Sunny Cove, Intel has increased the L1-D by 50%, but also increased the micro-op cache by 50%, taking advantage of the second generation 10nm process.
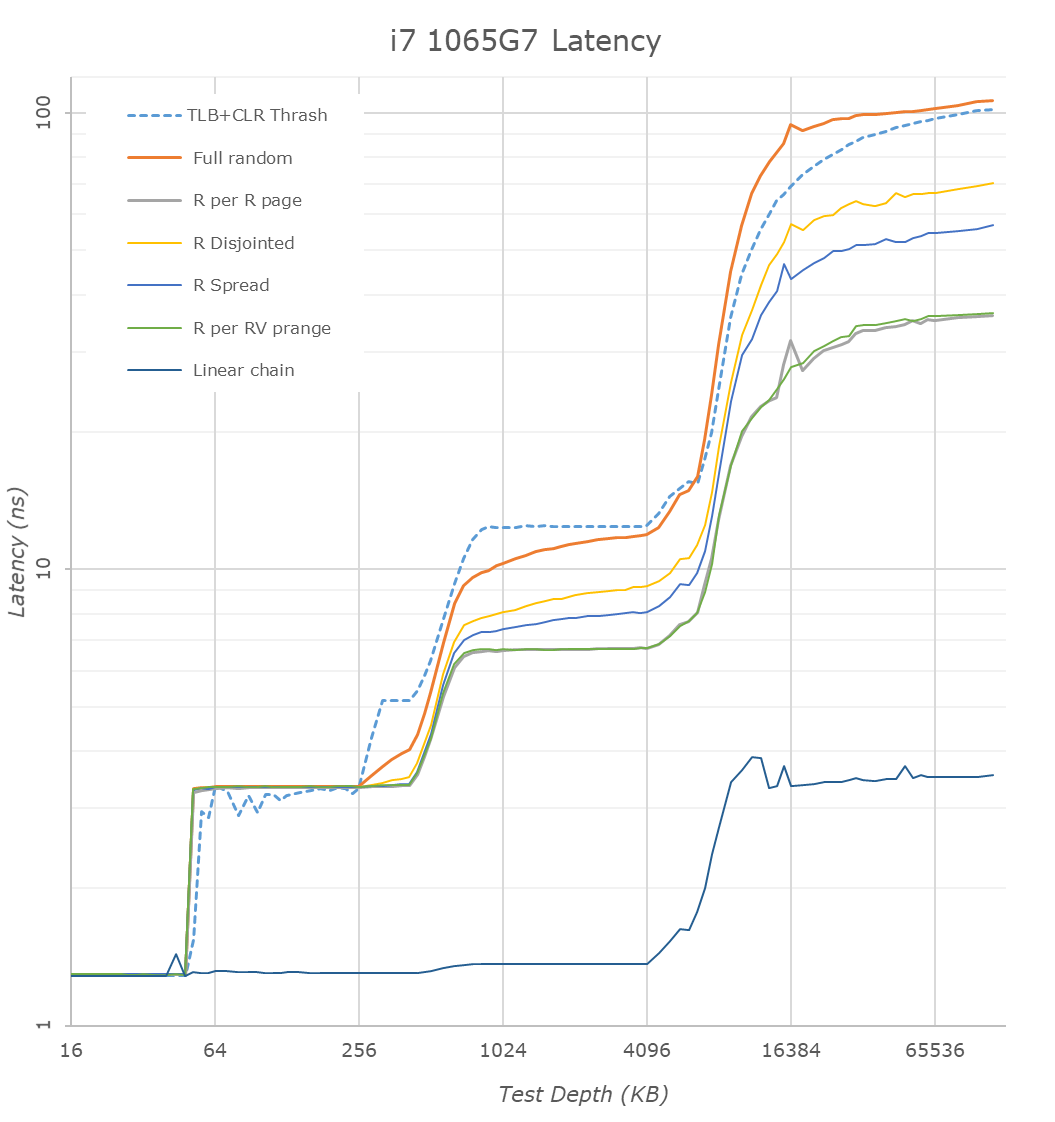
In the above latency graph comparison, we can notably see the new increased cache capacities. The L1’s increase from 32KB to 48KB is well visible, as well as the L2 increase from 256KB to 512KB.
On the part of the L2 it’s interesting to see that again the new core’s TLB structures don’t quite cover the whole capacity of the L2 and that’s why the latter half of the L2 has worse access latencies for L1D TLB miss patterns.
L3 latencies look similar, however we’ll dwell into that just in a bit. The DRAM latencies of course are apples and oranges in this case as Intel’s new LPPDR4X memory controller in the new ICL part doesn’t have a counter-part we can compare to, but as expected the memory latency is notably worse than a desktop part so no big surprises there.
What’s rather disappointing however is that we’re not really seeing any kind of change to the prefetchers and our access patterns between the two microarchitectures look identical. We had expected Intel to improve in this regard, but alas it seems, at least for our test cases, there’s been no improvements.
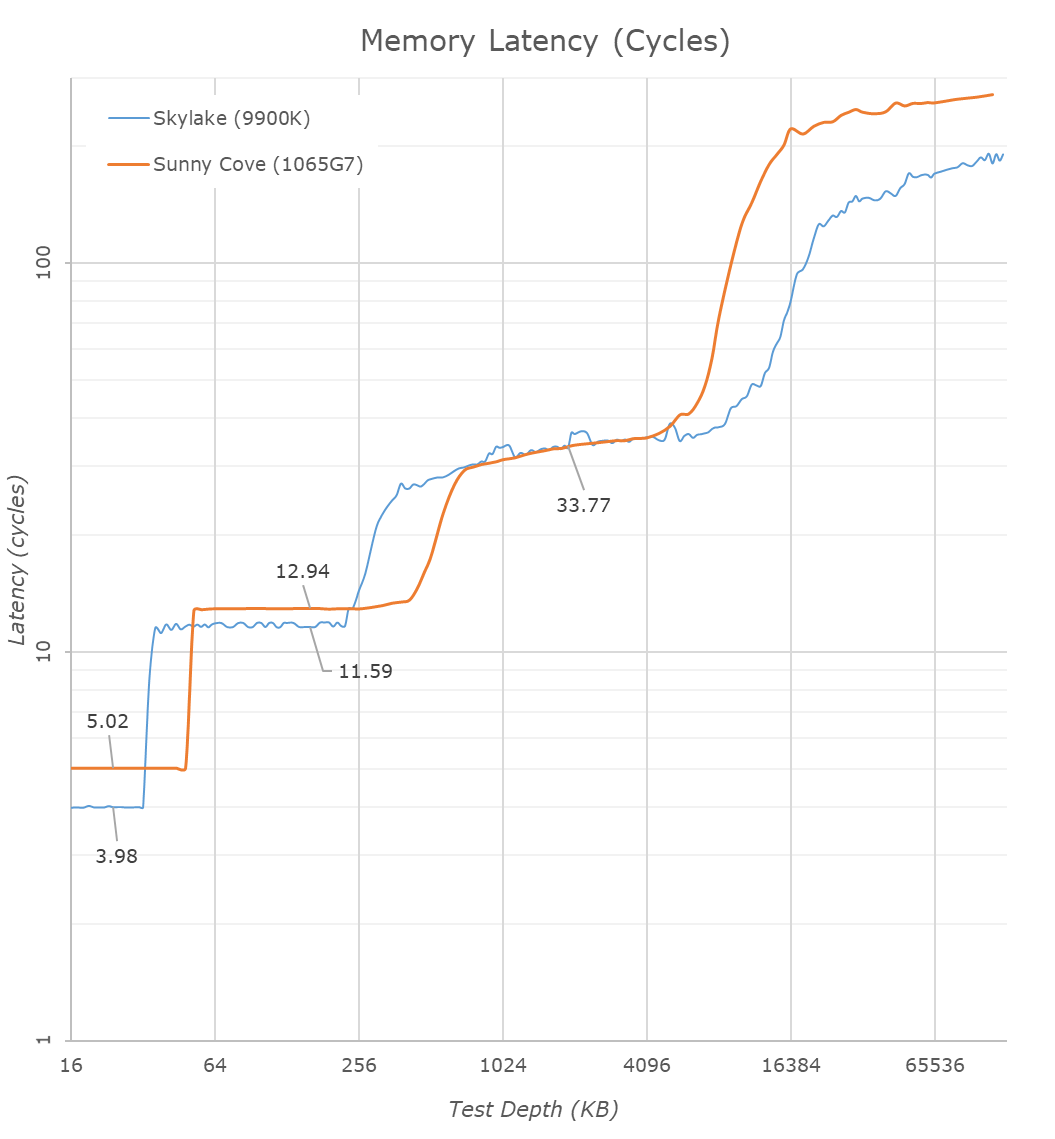
One of the major balancing acts with cache sizes is also cache latency. The bigger the cache, the longer it takes to retrieve data from it – increasing associativity can do this as well. Intel for the longest time has cited a 4-cycle latency to its L1 cache, and a 12-cycle latency to its L2 cache. This changes, in quite a substantial way.
| Core Cache Latency (in cycles) | ||||||
| Sunny Cove | AnandTech | Cannon Lake |
Skylake | Sandy Bridge |
AMD Zen 2 |
|
| 5 | L1 | 4 | 4 | 4 | 4 | |
| 13 | L2 | 12 | ~12 | 12 | 12 | |
| 30-36 | L3 | 26-37 | 34 | |||
Due to the increase in the L1 cache, that 4-cycle latency is now a 5-cycle latency. Intel is hoping that its double L1 store bandwidth will help hide that latency, however adding 20% latency onto every data fetch is a heavy hit to take. This is why a lot of the rest of the core is also beefed up, so work can still continue to cover for this extra cycle. It is worth noting that Intel’s Atom cores in the past had an L1 latency of 3 cycles, however they have also since moved to 4-cycle.
The L2 also changes, from 12 cycles to 13 cycles. You can’t double a cache for free, and it is interesting to note here that now AMD and Intel share the same L2 cache size and the same associativity, however AMD has a cycle advantage on Intel. This has a knock on effect for L3 cache latency too, which has increased from ~26-37 cycles to ~30-36 cycles on Intel, from Skylake. The latency here isn’t uniform because the cache isn’t uniform, and accessing non-local L3 slices comes with a latency penalty, as say opposed to AMD’s uniform latency L3.
One of the biggest additions Intel was keen to make in our Sunny Cove microarchitecture disclosure is the increase in the L1 bandwidth. Based on our testing, Skylake’s L1 data cache was capable of 2x32-byte read and 1x32-byte write per clock. For Sunny Cove this has increased, but it gets a bit more complicated. In one clock Sunny cove can perform 2x64-byte reads and either 1x64-byte write, or 1x32-byte write, or 2x16-byte writes. So both reads and writes, at peak, have doubled with bit width, with the write configurations being a bit more complex.

We can see the direct effects of the bandwidth change in our bandwidth tests. The L1 store bandwidth is extremely evident as it measures in at 222GB/s on the ICL part, while only reaching 139GB/s on the 28% higher clocked 9900K. If we normalise for frequency, we indeed see a doubling of the store bandwidth of the new core.
The L2 cache bandwidth looks unchanged from Skylake – the part here lags behind with an equal amount to the frequency difference. Surprisingly, the L3 bandwidth fares quite well here and is almost at parity to the desktop 9900K even though the frequency difference. The DRAM bandwidth is inferior on the ICL mobile chip, but again that’s to be expected due to the apples and oranges DRAM architecture comparison.
Moving on to the TLB configurations, and it turns out that Intel has moved where this data is stored. This data is typically stored in CPUID.02h, however it is now found in CPUID.18h, and the info between different page sizes and capabilities is now given as subdivisions. The TLBs look as follows, and broken down into configurations:
| Sunny Cove TLB | |||
| AnandTech | Type | Entries | Associativity |
| L1-D | 4K | 64 | 4-way |
| L1-D | 2M | 32 | 4-way |
| L1-D | 1G | 8 | full |
| L1-I | 4K+2M | 8 | full |
| L1-I | 4K+2M+1G | 16 | full |
| L2 | 4K+2M | 1024 | 8-way |
| L2 | 4K+1G | 1024 | 8-way |
This means that for 4K and 2M L1-I entries, there are a total 8+16 = 24 possible, but only 16 1G possible. For 4K L2 entries, there are 1024 + 1024 = 2048 entries possible, however only 1024 each of 2M/1G are possible. The peak numbers align with what Intel has told us in our microarchitecture disclosure, however it is good to dive into what is possible.








261 Comments
View All Comments
HStewart - Thursday, August 1, 2019 - link
I actually think the Ice Lake with eGPU setup would be quite nice, even without it - I believe with performance numbers that Dell XPS 13 2in1 could possibly give my Dell XPS 15 2in1 a run for its money.Also I curious with Thunderbolt 3 on the CPU now if any performance - keep in mind this is basically future USB4
One thing I saw related to SigGraph 2019, is AVX512 enhancements for 3d graphics processing coming in 3d ( not gaming but professional content creation ) world that it as 2x performance improvement on older systems - not sure how much this applies to Ice Lake system and require Xe to make it function
https://software.intel.com/en-us/siggraph/2019-ove...
RSAUser - Friday, August 2, 2019 - link
Tossing your GPU into an enclosure to run via thunderbolt is not a good idea, you're going to be heavily limited due to the added latency. It's a solution you only do as you are constantly traveling and never use the desktop while your laptop can't even run basic games.Phynaz - Friday, August 2, 2019 - link
What added latency. It’s pciegglaw - Sunday, August 4, 2019 - link
There are several decent reviews of eGPU enclosures out fairly recently - my conclusion from all of them was how INCONVENIENT it would be considering the size of the enclosures, total cost of the setup, and not a single enclosure I've seen reviewed matches the regular desktop performance. I would not travel with the eGPU, and if I'm at home a small micro-ATX build or ITX build ends up less cluttered and using a smaller footprint than a laptop + eGPU at a fraction of the price with better performance.sing_electric - Thursday, August 1, 2019 - link
There's an issue with CPU names in the 1st table ("Intel 10nm Ice Lake-U Series CPUs"):All the chips are listed as "Core i7" before their suffixes. When reading the new name nomenclature, I was like "wait, Intel's using Core i7 for.... everything now?" Later tables don't have this problem, though.
Ian Cutress - Thursday, August 1, 2019 - link
Should be fixed :)sing_electric - Thursday, August 1, 2019 - link
Much easier to read! And good that Intel's not using... "brand inflation?"ShowsOn - Thursday, August 1, 2019 - link
The two different (?) shades of dark blue makes these charts very hard to understand. Accept the faster dark blue bars are the 9900K, but it is just visually confusing.Ryan Smith - Thursday, August 1, 2019 - link
You make a good point. We've changed the SPEC charts so that all products use distinct colors. Thanks!zodiacfml - Thursday, August 1, 2019 - link
yawn. 10nm for nothing except the better IGP. they could have at least made it at least 6 core at lower clock speeds but more performance than last gen. at the same TDP. in fairness, this 10nm die is probably larger than AMD's single Ryzen 3000 7nm die