The Ice Lake Benchmark Preview: Inside Intel's 10nm
by Dr. Ian Cutress on August 1, 2019 9:00 AM EST- Posted in
- CPUs
- Intel
- GPUs
- 10nm
- Core
- Ice Lake
- Cannon Lake
- Sunny Cove
- 10th Gen Core
Cache and TLB Updates
One of the biggest changes in the new Sunny Cove core is the cache hierarchy. Throughout most of the last decade, Intel has kept the same cache configuration among its server cores with very few changes, aside from improving the micro-op cache through Sandy Bridge today, but with Sunny Cove, we get some key updates.
From our microarchitecture disclosure article, we know that Sunny Cove brings with it an increased L1 data cache, as well as a doubled L2 cache, from Skylake. With this comes more associativity as well.
| Core Cache Comparison | ||||||
| Sunny Cove |
AnandTech | Cannon Lake |
Skylake | Sandy Bridge |
AMD Zen 2 |
|
| 48 KB 12-way |
L1-D | 32 KB 8-way |
32 KB 8-way |
32 KB 8-way |
32 KB 8-way |
|
| 32 KB 8-way |
L1-I | 32 KB 8-way |
32 KB 8-way |
32 KB 8-way |
32 KB 8-way |
|
| 512 KB 8-way |
L2 | 256 KB 4-way |
256 KB 4-way |
256 KB 8-way |
512 KB 8-way |
|
| 2 MB 16-way |
L3/core | 2 MB 16-way |
2 MB 16-way |
2MB 16-way |
4 MB 16-way |
|
| 2304 | uOp Cache | 1536 | 1536 | 1536 | 4096 | |
I’ve also included the size of the micro-op cache in this comparison, because we understand that the L1-I and the micro-op cache are typically located next to each other in the die design – increasing the size of one typically means limiting the size of the other, however given that both of them work to accelerate the same types of data, it is important to find the right balance: AMD for Zen 2 decided to halve the L1-I and double its associativity, and then double the micro-op cache from 2k to 4k entries. For Sunny Cove, Intel has increased the L1-D by 50%, but also increased the micro-op cache by 50%, taking advantage of the second generation 10nm process.
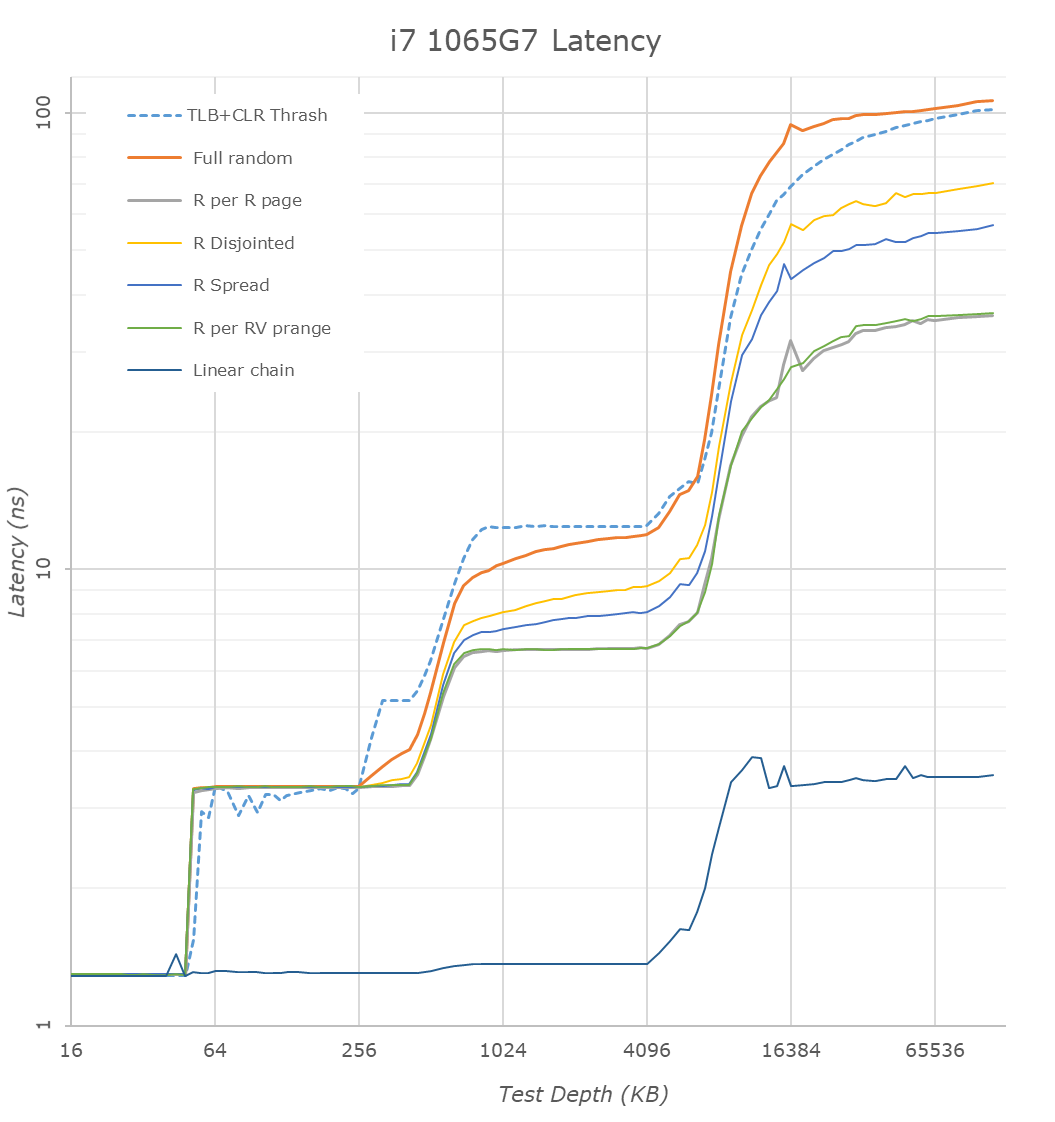
In the above latency graph comparison, we can notably see the new increased cache capacities. The L1’s increase from 32KB to 48KB is well visible, as well as the L2 increase from 256KB to 512KB.
On the part of the L2 it’s interesting to see that again the new core’s TLB structures don’t quite cover the whole capacity of the L2 and that’s why the latter half of the L2 has worse access latencies for L1D TLB miss patterns.
L3 latencies look similar, however we’ll dwell into that just in a bit. The DRAM latencies of course are apples and oranges in this case as Intel’s new LPPDR4X memory controller in the new ICL part doesn’t have a counter-part we can compare to, but as expected the memory latency is notably worse than a desktop part so no big surprises there.
What’s rather disappointing however is that we’re not really seeing any kind of change to the prefetchers and our access patterns between the two microarchitectures look identical. We had expected Intel to improve in this regard, but alas it seems, at least for our test cases, there’s been no improvements.
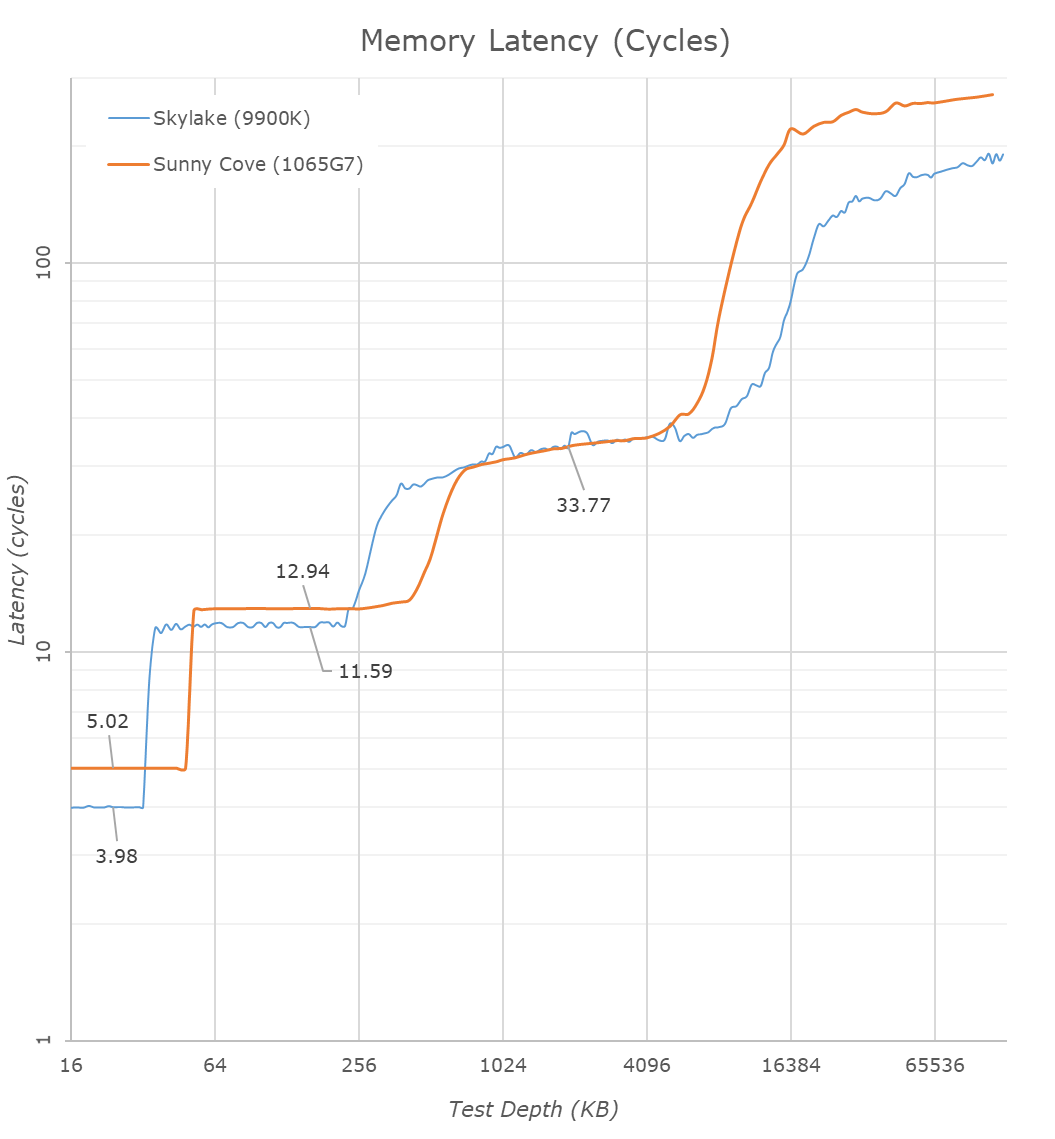
One of the major balancing acts with cache sizes is also cache latency. The bigger the cache, the longer it takes to retrieve data from it – increasing associativity can do this as well. Intel for the longest time has cited a 4-cycle latency to its L1 cache, and a 12-cycle latency to its L2 cache. This changes, in quite a substantial way.
| Core Cache Latency (in cycles) | ||||||
| Sunny Cove | AnandTech | Cannon Lake |
Skylake | Sandy Bridge |
AMD Zen 2 |
|
| 5 | L1 | 4 | 4 | 4 | 4 | |
| 13 | L2 | 12 | ~12 | 12 | 12 | |
| 30-36 | L3 | 26-37 | 34 | |||
Due to the increase in the L1 cache, that 4-cycle latency is now a 5-cycle latency. Intel is hoping that its double L1 store bandwidth will help hide that latency, however adding 20% latency onto every data fetch is a heavy hit to take. This is why a lot of the rest of the core is also beefed up, so work can still continue to cover for this extra cycle. It is worth noting that Intel’s Atom cores in the past had an L1 latency of 3 cycles, however they have also since moved to 4-cycle.
The L2 also changes, from 12 cycles to 13 cycles. You can’t double a cache for free, and it is interesting to note here that now AMD and Intel share the same L2 cache size and the same associativity, however AMD has a cycle advantage on Intel. This has a knock on effect for L3 cache latency too, which has increased from ~26-37 cycles to ~30-36 cycles on Intel, from Skylake. The latency here isn’t uniform because the cache isn’t uniform, and accessing non-local L3 slices comes with a latency penalty, as say opposed to AMD’s uniform latency L3.
One of the biggest additions Intel was keen to make in our Sunny Cove microarchitecture disclosure is the increase in the L1 bandwidth. Based on our testing, Skylake’s L1 data cache was capable of 2x32-byte read and 1x32-byte write per clock. For Sunny Cove this has increased, but it gets a bit more complicated. In one clock Sunny cove can perform 2x64-byte reads and either 1x64-byte write, or 1x32-byte write, or 2x16-byte writes. So both reads and writes, at peak, have doubled with bit width, with the write configurations being a bit more complex.

We can see the direct effects of the bandwidth change in our bandwidth tests. The L1 store bandwidth is extremely evident as it measures in at 222GB/s on the ICL part, while only reaching 139GB/s on the 28% higher clocked 9900K. If we normalise for frequency, we indeed see a doubling of the store bandwidth of the new core.
The L2 cache bandwidth looks unchanged from Skylake – the part here lags behind with an equal amount to the frequency difference. Surprisingly, the L3 bandwidth fares quite well here and is almost at parity to the desktop 9900K even though the frequency difference. The DRAM bandwidth is inferior on the ICL mobile chip, but again that’s to be expected due to the apples and oranges DRAM architecture comparison.
Moving on to the TLB configurations, and it turns out that Intel has moved where this data is stored. This data is typically stored in CPUID.02h, however it is now found in CPUID.18h, and the info between different page sizes and capabilities is now given as subdivisions. The TLBs look as follows, and broken down into configurations:
| Sunny Cove TLB | |||
| AnandTech | Type | Entries | Associativity |
| L1-D | 4K | 64 | 4-way |
| L1-D | 2M | 32 | 4-way |
| L1-D | 1G | 8 | full |
| L1-I | 4K+2M | 8 | full |
| L1-I | 4K+2M+1G | 16 | full |
| L2 | 4K+2M | 1024 | 8-way |
| L2 | 4K+1G | 1024 | 8-way |
This means that for 4K and 2M L1-I entries, there are a total 8+16 = 24 possible, but only 16 1G possible. For 4K L2 entries, there are 1024 + 1024 = 2048 entries possible, however only 1024 each of 2M/1G are possible. The peak numbers align with what Intel has told us in our microarchitecture disclosure, however it is good to dive into what is possible.








261 Comments
View All Comments
Phynaz - Friday, August 2, 2019 - link
What? TDP doesn’t mean what you think it does.Alexvrb - Monday, August 5, 2019 - link
I didn't feel like quoting the entire paragraph. But please DO elaborate. Then tell me how useful TDP is when they let OEMs set PL2 and Tau to... anything, really. You can take two "95W" processors and their power and thermals under load are radically different across a range of mainboards. The is reflected in mobile as well, where they let OEMs do pretty much whatever - the results aren't constrained by the processor no matter what the claimed TDP is. That doesn't even COUNT overclocking.Meanwhile AMD chips don't hand over control to mainboards unless you ARE overclocking, which is how it SHOULD be.
Alistair - Friday, August 2, 2019 - link
I didn't see any discussion or comparison vs. the i7-9850H. Let's see a 28W TDP version of the 6 core i7-9850H put against these new chips. Same money, 50 percent more cores. Anyone in their right mind should be looking for an i7-9850H or 9750H laptop instead over these 10nm products. Where is the 6 core 10nm CPU? Don't buy a 4 cores laptop if you're looking for good performance in 2019-2020 imo.If you want a 4 core laptop get a cheaper 14nm based laptop. If you want performance get a 6 core. I really really don't see the point in these products.
Alexvrb - Friday, August 2, 2019 - link
They gotta do *something* with all those 10nm wafers. Ian can't eat them all, and China said they don't want any more half-baked 10nm products after the last go-around. Maybe in 2020 we'll see 10nm++ and it will be as good as phase one 10nm was supposed to be.But yeah, their current 10nm products are a bit disappointing outside of the fatter GPUs and better memory speeds. If you're using something with a dGPU there's little point vs their own 14++, it only starts to make sense if you want AMD-like iGPU performance with the latest Core processor design. Even then that's only limited to models with a high EU count (48+) as the 32 EU models just look meh.
They're going to have some stiff competition when 7nm Zen 2 APUs launch. I guess that's why they're attacking the low-power first, as AMD is still stuck on 12nm rehash Zen+ products for now.
InvidiousIgnoramus - Friday, August 2, 2019 - link
I still find it amusing that the architecture with "Ice" in it's name has low clock speeds presumably from power/heat issues.abufrejoval - Friday, August 2, 2019 - link
Great work! And kudos to AMD to make Intel work so much harder to get good news out!Two die carrier layouts but the chips looking identical:
First of all, I assume that the bigger and square chip is essentially the North-Bridge in 14nm?
And the smaller rectangular one the CPU+iGPU?
And I guess at 64EU we are talking about more than 60% of die area going to iGPU while even at quad core and AES-512 the CPU + cache will be perhaps 30%?
Is there any HSA or GPGPU compute to 'pay' for that iGPU surface and power in professional workloads?
Or is it really just for gaming?
Am I also correct to assume that of the extra thermal budget in the 28Watt parts, none really goes to the CPU, only allows it to stay within the 15 Watt envelope while the iGPU is also running?
Are we talking different die layouts and sizes for dual/quad CPUs and 64/32 iGPU EUs or is it really all just binning, meaning that an Core i3-1000G1 is a chip where 70% surface area of an Core i7-1060G7 failed to make it?
Why am I thinking they are heading down a path without consumer value returns?
I got a Lenovo S730 i7-8565U or Whisky Lake recently for a little over €1000 and I got a couple of J5005 Atoms recently for a little over €100 (admittedly complete notebook vs. RAM less Mini-ITX mainboard). The difference in power is 15 vs 10 Watts.
Both are fairly competent 2D machines even at 4k. Both are terrible gaming machines, but I don't really think that ultrabook portable gaming performance is a selling point.
If I were free to choose CPU vs. GPU real-estate, I'd definitely go left, say 6 or 8 CPU cores or just higher sustained turbos and make do with the J5005's 18 iGPU EUs, because CPU power is what I profit from professionally.
For GPU, every € I spend gets me vastly more gaming experience in less mobile form factors, which is fine: I don't see how I could run in a game and outside without breaking my newest toy.
Sahrin - Friday, August 2, 2019 - link
$426 for a quad core in 2019. What a time to be alive.eva02langley - Friday, August 2, 2019 - link
So basically... expensive, low yield, 4 cores, low frequency.Outside of better IGPU, barely matching AMD offering, and AVX512, which is not even a matter for a 4 cores CPU, 10nm is an abysmal failure.
Phynaz - Friday, August 2, 2019 - link
So basically....you’re an imbecileKorguz - Friday, August 2, 2019 - link
your one to talk phynaz, i guess you want to be stuck on quad cores in notebooks for ever ???