The AMD Radeon RX 5700 XT & RX 5700 Review: Navi Renews Competition in the Midrange Market
by Ryan Smith on July 7, 2019 12:00 PM ESTCompute
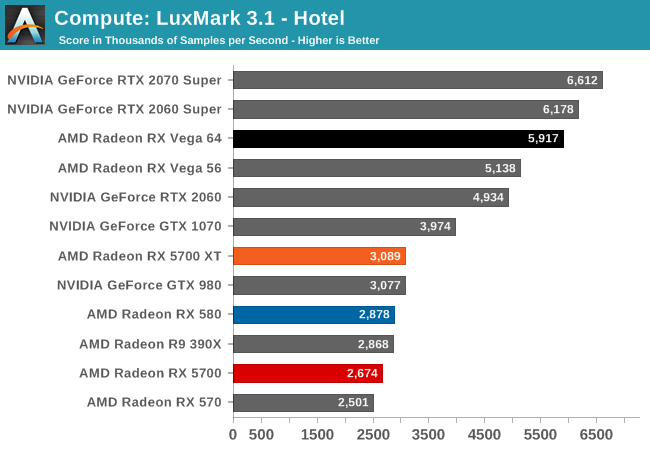
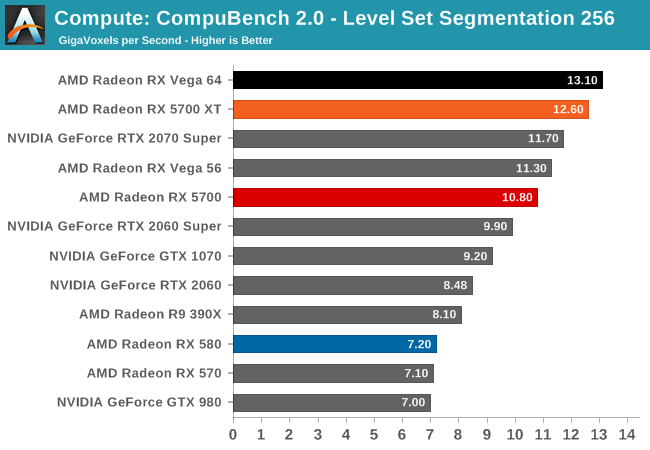
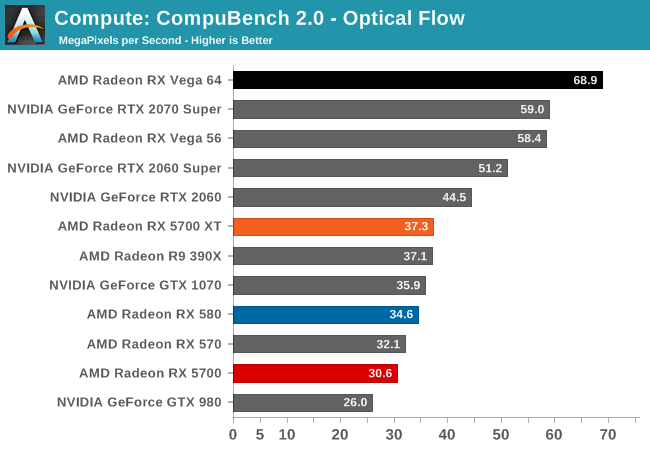
Unfortunately, as I mentioned earlier in my testing observations, the state of AMD's OpenCL driver stack at launch is quite poor. Most of our compute benchmarks either failed to have their OpenCL kernels compile, triggered a Windows Timeout Detection and Recovery (TDR), or would just crash. As a result, only three of our regular benchmarks were executable here, with Folding@Home, parts of CompuBench, and Blender all getting whammied.
And "executable" is the choice word here, because even though benchmarks like LuxMark would run, the scores the RX 5700 cards generated were nary better than the Radeon RX 580. This a part that they can easily beat on raw FLOPs, let alone efficiency. So even when it runs, the state of AMD's OpenCL drivers is at a point where these drivers are likely not indicative of anything about Navi or the RDNA architecture; only that AMD has a lot of work left to go with their compiler.
That said, it also serves to highlight the current state of OpenCL overall. In short, OpenCL doesn't have any good champions right now. Creator Apple is now well entrenched in its own proprietary Metal ecosystem, NVIDIA favors CUDA for obvious reasons, and even AMD's GPU compute efforts are more focused on the Linux-exclusive ROCm platform, since this is what drives their Radeon Instinct sales. As a result, the overall state of GPU computing on the Windows desktop is in a precarious place, and at this rate I wouldn't be entirely surprised if future development is centered around compute shaders instead.








135 Comments
View All Comments
rUmX - Sunday, July 7, 2019 - link
It's no longer the same architecture. RDNA vs GCN. The fact that a 36 CU (5700) consistently beats Vega 56 (56 CU) shows the design changes. Sure part of it is clock speeds and having 64 ROPs but still Navi is much more efficient than GCN, and it's doing it with much less shaders. Imagine a bigger Navi can match it exceed the 2080 TI.Kevin G - Sunday, July 7, 2019 - link
Not all those transistors are for the improved CUs either. There is a new memory controller to support GDDR6, new video codec engine and some spent on the new display controller to support DSC for 4K120 on DP 1.4.peevee - Thursday, July 11, 2019 - link
Why would GDDR6 need substantially more transistors than GDDR5? Video codec seems more or less the same also.Looks like there are some hidden features not enabled yet, hard to explain that increase in transistors per stream processor (not CU) otherwise (CUs are just twice as wide).
Meteor2 - Monday, July 8, 2019 - link
I was wondering the same thing.JasonMZW20 - Tuesday, July 16, 2019 - link
Because it's now a VLIW2 architecture via RDNA. Each CU is actually a dual-CU set (2x32SPs, 64 SPs total) and is paired with another dual-CU to form of workgroup processor (4x32) or 128 SPs. Tons of cache has been added and rearranged. This requires space and extra logic.Geometry engines (via Primitive Units) are fully programmable and are no longer fixed function. This also requires extra logic. Rasterizer, ROPs, and Primitive Unit with 128KB L1 cache are closely tied together.
Navi definitely replaces both Polaris and Vega 10/20 for gaming, so average out Polaris 30 (5.7B) and Vega 10 (12.5B) transistor amounts and you'll be somewhere near Navi 10. Vega 20 is still great at compute tasks, so I don't see it being phased out in professional markets soon.
Cooe - Tuesday, March 23, 2021 - link
... RDNA is NOT VLIW (like Terascale) ANYTHING. It's still exclusively a scaler SIMD architecture like GCN.tipoo - Sunday, July 7, 2019 - link
Do those last (at least two) Beyond3D tests look a little suspect to anyone? Multiple AMD generations all clustering around 1.0, almost looks like a driver cap.rUmX - Sunday, July 7, 2019 - link
Ugh no edit... I meant "Big Navi can match or exceed 2080 TI".Kevin G - Sunday, July 7, 2019 - link
Looking at the generations it doesn't surprise me about the RX 580 but it is odd to see the RX 5700 there, especially when Vega is higher. An extra 20% of bandwidth for the RX 5700 via compression would go a long way at 4K resolutions.Ryan Smith - Sunday, July 7, 2019 - link
It's a weird situation. The default I use for the test is to try to saturate the cards with several textures; however AMD's cards do better with just 1-2 textures. I'll have a longer explanation once I get caught up on writing.From my notes: (in GB/sec, random/black)
UINT8 1 Tex: 333/472
FP32 1 Tex: 445/469
UNIT8 6 Tex: 389/406
FP32 6 Tex: 406/406