The AMD Radeon RX 5700 XT & RX 5700 Review: Navi Renews Competition in the Midrange Market
by Ryan Smith on July 7, 2019 12:00 PM ESTCompute
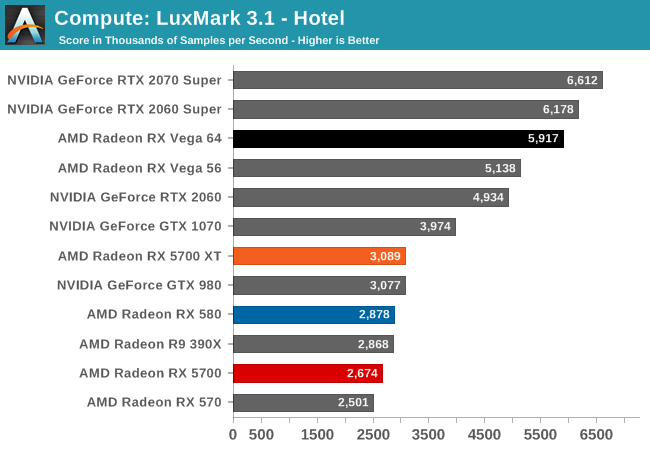
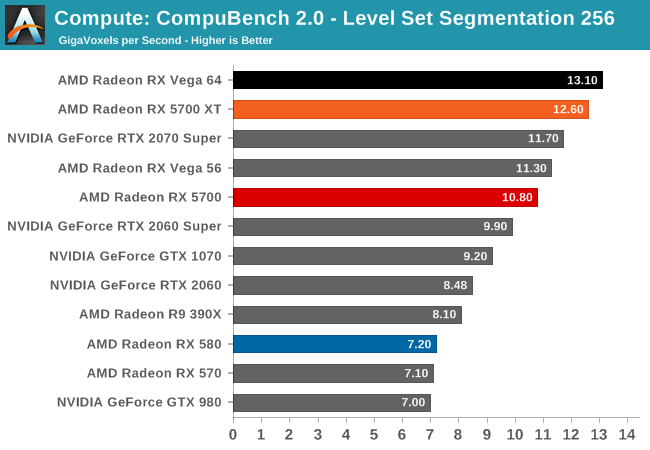
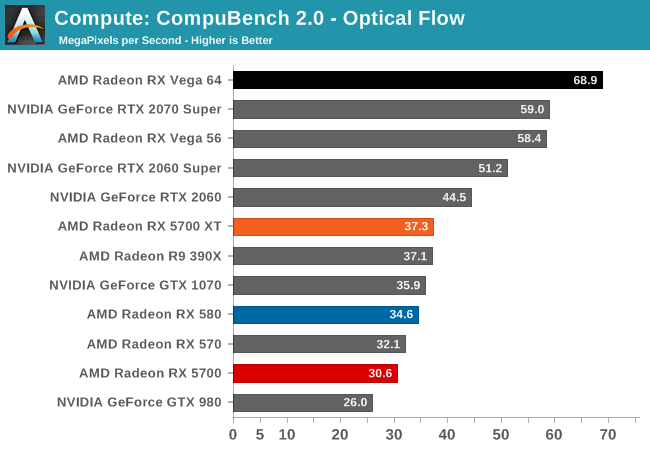
Unfortunately, as I mentioned earlier in my testing observations, the state of AMD's OpenCL driver stack at launch is quite poor. Most of our compute benchmarks either failed to have their OpenCL kernels compile, triggered a Windows Timeout Detection and Recovery (TDR), or would just crash. As a result, only three of our regular benchmarks were executable here, with Folding@Home, parts of CompuBench, and Blender all getting whammied.
And "executable" is the choice word here, because even though benchmarks like LuxMark would run, the scores the RX 5700 cards generated were nary better than the Radeon RX 580. This a part that they can easily beat on raw FLOPs, let alone efficiency. So even when it runs, the state of AMD's OpenCL drivers is at a point where these drivers are likely not indicative of anything about Navi or the RDNA architecture; only that AMD has a lot of work left to go with their compiler.
That said, it also serves to highlight the current state of OpenCL overall. In short, OpenCL doesn't have any good champions right now. Creator Apple is now well entrenched in its own proprietary Metal ecosystem, NVIDIA favors CUDA for obvious reasons, and even AMD's GPU compute efforts are more focused on the Linux-exclusive ROCm platform, since this is what drives their Radeon Instinct sales. As a result, the overall state of GPU computing on the Windows desktop is in a precarious place, and at this rate I wouldn't be entirely surprised if future development is centered around compute shaders instead.








135 Comments
View All Comments
Zoolook13 - Friday, July 19, 2019 - link
1080 has 7,2 Billion trans, and 1080 Ti has 11,7B IIRC, so your figures are all wrong and there is a number of features on Navi that isn't in Pascal, not to mention it's vastly superior in compute.ajlueke - Wednesday, July 10, 2019 - link
At the end of the day, the 5700 is on the identical performance per watt and performance per dollar curve as the "advanced" Turing GPUs. From that we can infer that that "advanced" Turing features really don't amount to much in terms of performance.Also, the AMD RDNA GPUs are substantially smaller in die area than the NVidia counterparts. More chips per wafer, and thus lower production costs. AMD likely makes more money on each sale of Navi than NVidia does on Turing GPUs.
CiccioB - Wednesday, July 10, 2019 - link
So having "less features is better" is now the new AMD fanboys motto?The advanced Turing express its power when you use those features, not when you test the games that:
1. Have been optimized exclusively for GCN architecture showin
2. Use few polygons as AMD's GPUs geometry capacity is crap
3. Turn off Turing exclusive features
Moreover the games are going to use those new feature s as AMD is going to add them in RDNA2, so you already know these piece of junks are going to have zero value in few months.
Despite this, the size is not everything, as 7nm wafer do not cost as 12nm ones and being small is a need more than a choice:in fact AMD is not going to produce the bigger GPUs with all the advanced features (or just a part of them that fit on a certain die size, as they are going to be fatter than these) on this PP until it comes to better costs, the same is doing Nvidia that does not need 7nm to create better and less power hungry cards.
These GPUs are just a fill up waiting for the next real ones that have the features then next console will enjoy. And this will surely include VRS and somewhat a RT acceleration of some sort as AMD cannot be without to not be identified as being left in stone age.
You know these piece of junk will be soon forget as they are not good for nothing but to fil the gap as Vega tried in the past, The time to create a decent architecture was not enough. They are still behind and all they are trying is to make a disturbance move just by placing the usual discounted cards with not new features exploiting TSMC 7nm granted allocation for Ryzen and EPYC.
It does not cost AMD anything stil making a new round of zero margin cards as they have done all these years, but they gain in visibility and make pressure to Nvidia with it features rich big dies.
SarruKen - Tuesday, July 9, 2019 - link
Last time I checked the turing cards were on 12nm, not 16...CoachAub - Tuesday, July 9, 2019 - link
The article states in the graphic that Navi has PCI-e 4.0 Support (2x bandwidth). Now, if this card is paired with the new X570 mobo, will this change benchmark results? I'd really like to see this card paired with a Ryzen 3000 series on an X570 mobo and tested.CiccioB - Wednesday, July 10, 2019 - link
No, it won't. Today GPUS can't even saturare 8x PCIe-3 gen bandwidth, do having more does not help at all. Non in the consumer market, at least.peevee - Thursday, July 11, 2019 - link
They absolutely do saturate everything you give them, but only for very short periods necessary to load textures etc from main memory, which is dwarfed by loading them from storage (even NVMe SSDs) first.BUT... the drivers might have been optimized (at compile time and/or manual ASM snippets) for AMD CPUs. And that makes significant difference.
CiccioB - Friday, July 12, 2019 - link
Loading time is not the bottleneck of the GPU PCIe bandwidth, nor the critical part of its usage. Lading textures and shade code in .3 secs instead of 0.6s does not make any difference.You need more bandwidth only when you saturate the VRAM and the card starts using system memory.
But being much slower than VRAM, having PCIe 2, 3 or 4 does not change much: you'll have big stuttering and frame drops.
And in SLI/cross fire mode PCIe 3 8x is still not fully saturated. So at the end, PCIe 4 is useless for GPUs. It is a big boost for NVe disk and to increase the number of available connections using half of the PCIe 3 lines for each of them.
msroadkill612 - Thursday, July 25, 2019 - link
"Today GPUS can't even saturare 8x PCIe-3 gen bandwidth, do having more does not help at all. "It is a sad reflection on the prevailing level of logic, that this argument has gained such ~universal credence.
It presupposes that "todays" software is set in stone, which is absurd. ~Nothing could be less true.
Why would a sane coder EVEN TRY to saturate 8GB/s, which pcie 2 x16 was not so long ago when many current games evolved their DNA?
The only sane compromise has been to limit game's resource usage to mainstream gpu cache size.
32GB/s tho, is a real heads up.
It presents a competitive opportunity to discerningly use another tier in the gpu cache pool, 32GB/s of relatively plentiful and cheap, multi purpose system ram.
We have historically seen a progression in gpu cache size, and coders eager to use it. 6GB is getting to the point where it doesnt cut it on modern games with high settings.
ajlueke - Wednesday, July 10, 2019 - link
In the Radeon VII review, the Radeon VII produced 54.5 db in the FurMark test. This time around, the 5700 produced 54.5 db so I would expect that the Radeon VII and 5700 produce identical levels of noise.Except for one caveat. The RX Vega 64 is the only GPU present in both reviews. In the Radeon VII review it produced 54.8db, nearly identical to the Radeon VII. In the 5700 review, it produced 61.9 db, significantly louder than the 5700.
So are the Radeon VII and 5700 identical in noise? Would the Radeon VII also have run at 61.9 db in this test with the 5700? Why the discrepancy with the Vega result? A 13% gain in noise in the identical test with the identical GPU makes it difficult to determine how much noise is actually being generated here.