The AMD 3rd Gen Ryzen Deep Dive Review: 3700X and 3900X Raising The Bar
by Andrei Frumusanu & Gavin Bonshor on July 7, 2019 9:00 AM ESTSPEC2006 & 2017: Industry Standard - ST Performance
One big talking point around the new Ryzen 3000 series is the new augmented single-threaded performance of the new Zen 2 core. In order to investigate the topic in a more controlled manner with better documented workloads, we’ve fallen back to the industry standard SPEC benchmark suite.
We’ll be investigating the previous generation SPEC CPU2006 test suite giving us some better context to past platforms, as well as introducing the new SPEC CPU2017 suite. We have to note that SPEC2006 has been deprecated in favour of 2017, and we must also mention that the scores posted today are noted as estimates as they’re not officially submitted to the SPEC organisation.
For SPEC2006, we’re still using the same setup as on our mobile suite, meaning all the C/C++ benchmarks, while for SPEC2017 I’ve also went ahead and prepared all the Fortran tests for a near complete suite for desktop systems. I say near complete as due to time constraints we’re running the suite via WSL on Windows. I’ve checked that there are no noticeable performance differences to native Linux (we’re also compiling statically), however one bug on WSL is that it has a fixed stack size so we’ll be missing 521.wrf_r from the SPECfp2017 collection.
In terms of compilers, I’ve opted to use LLVM both for C/C++ and Fortran tests. For Fortran, we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 8.0.0-svn350067-1~exp1+0~20181226174230.701~1.gbp6019f2 (trunk) clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git 24bd54da5c41af04838bbe7b68f830840d47fc03) -Ofast -fomit-frame-pointer -march=x86-64 -mtune=core-avx2 -mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions.
The Ryzen 3900X system was run in the same way as the rest of our article with DDR4-3200CL16, same as with the i9-9900K, whilst the Ryzen 2700X had DDR-2933 with similar CL16 16-16-16-38 timings.
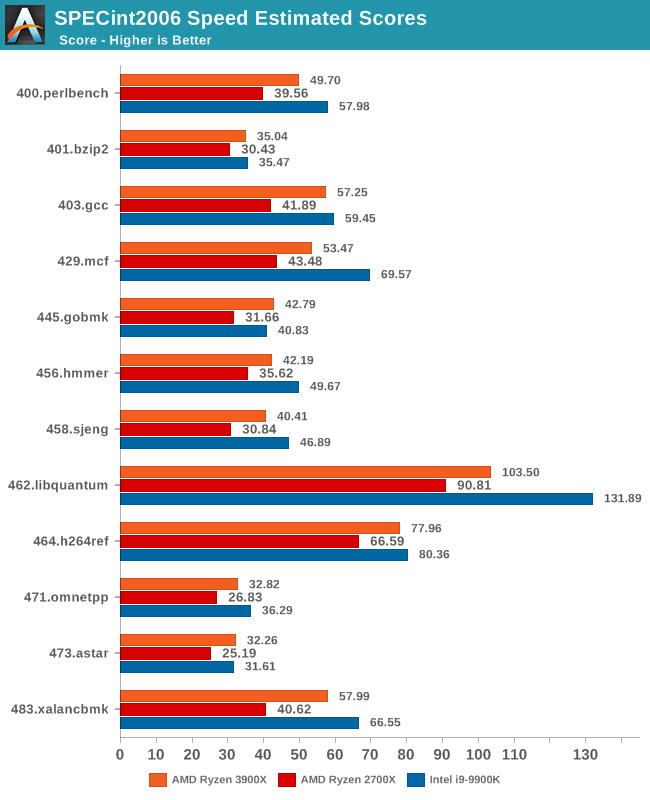
In terms of the int2006 benchmarks, the improvements of the new Zen2 based Ryzen 3900X is quite even across the board when compared to the Zen+ based Ryzen 2700X. We do note however somewhat larger performance increases in 403.gcc and 483.xalancbmk – it’s not immediately clear as to why as the benchmarks don’t have one particular characteristic that would fit Zen2’s design improvements, however I suspect it’s linked to the larger L3 cache.
445.gobmk in particular is a branch-heavy workload, and the 35% increase in performance here would be better explained by Zen2’s new additional TAGE branch predictor which is able to reduce overall branch misses.
It’s also interesting that although Ryzen3900X posted worse memory latency results than the 2700X, it’s still able to outperform the latter in memory sensitive workloads such as 429.mcf, although the increases for 471.omnetpp is amongst the smallest in the suite.
However we still see that AMD has an overall larger disadvantage to Intel in these memory sensitive tests, as the 9900K has large advantages in 429.mcf, and posting a large lead in the very memory bandwidth intensive 462.libquantum, the two tests that put the most pressure on the caches and memory subsystem.
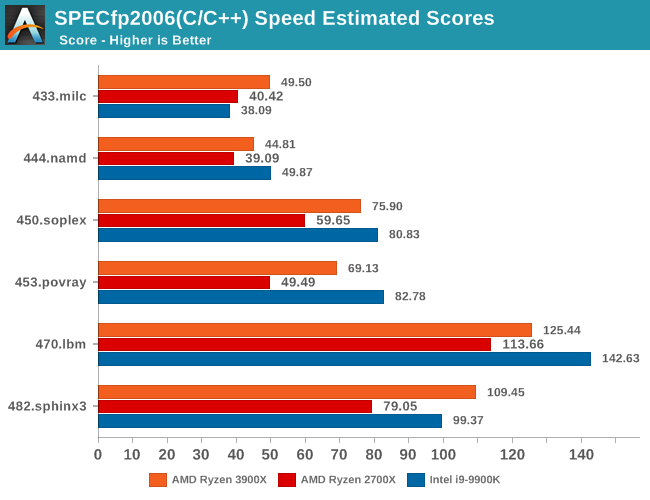
In the fp2006 benchmarks, we gain see some larger jumps on the part of the Ryzen 3900X, particularly in 482.sphinx3. These two tests along with 450.soplex are characterized by higher data cache misses, so Zen2’s 16MB L3 cache should definitely be part of the reason we see such larger jumps.
I found it interesting that we’re not seeing much improvements in 470.lbm even though this is a test that is data store heavy, so I would have expected Zen2’s additional store AGU to greatly benefit this workload. There must be some higher level memory limitations which is bottlenecking the test.
453.povray isn’t data heavy nor branch heavy, as it’s one of the more simple workloads in the suite. Here it’s mostly up to the execution backend throughput and the ability of the front-end to feed it fast enough that are the bottlenecks. So while the Ryzen 3900X provides a big boost over the 2700X, it’s still largely lagging behind the 9900K, a characteristic we’re also seeing in the similar execution bottlenecked 456.hmmer of the integer suite.
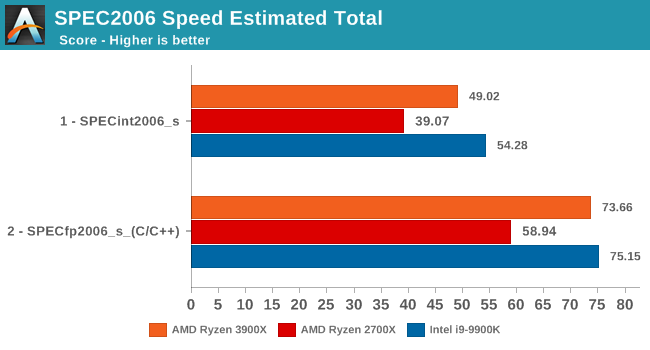
Overall, the 3900X is 25% faster in the integer and floating point tests of the SPEC2006 suite, which corresponds to an 17% IPC increase, above AMD's officially published figures for IPC increases.
Moving on to the 2017 suite, we have to clarify that we’re using the Rate benchmark variations. The 2017 suite’s speed and rate benchmarks differ from each other in terms of workloads. The speed tests were designed for single-threaded testing and have large memory demands of up to 11GB, while the rate tests were meant for multi-process tests. We’re using the rate variations of the benchmarks because we don’t see any large differentiation between the two variations in terms of their characterisation and thus the performance scaling between the both should be extremely similar. On top of that, the rate benchmarks take up to 5x less time (+1 hour vs +6 hours), and we're able run them on more memory limited platforms (which we plan on to do in the future).
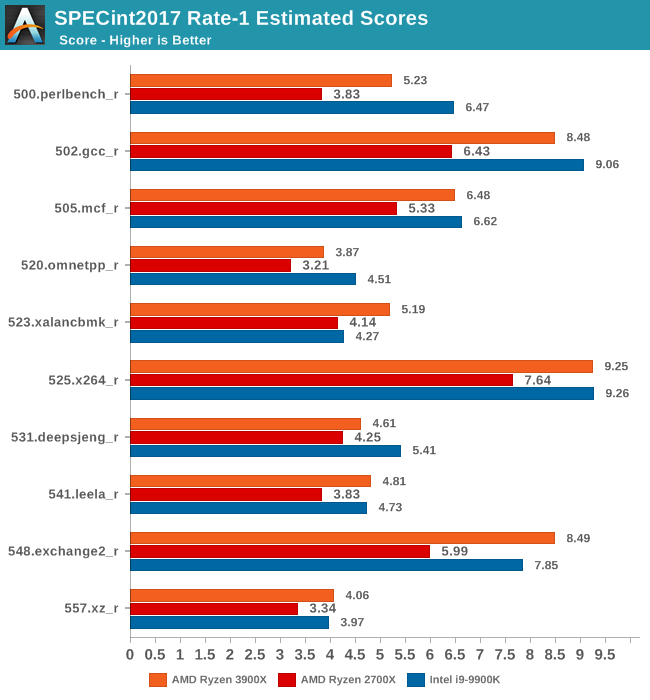
In the int2017 suite, we’re seeing similar performance differences and improvements, although this time around there’s a few workloads that are a bit more limited in terms of their performance boosts on the new Ryzen 3900X.
Unfortunately I’m not quite as familiar with the exact characteristics of these tests as I am with the 2006 suite, so a more detailed analysis should follow in the next few months as we delve deeper into microarchitectural counters.
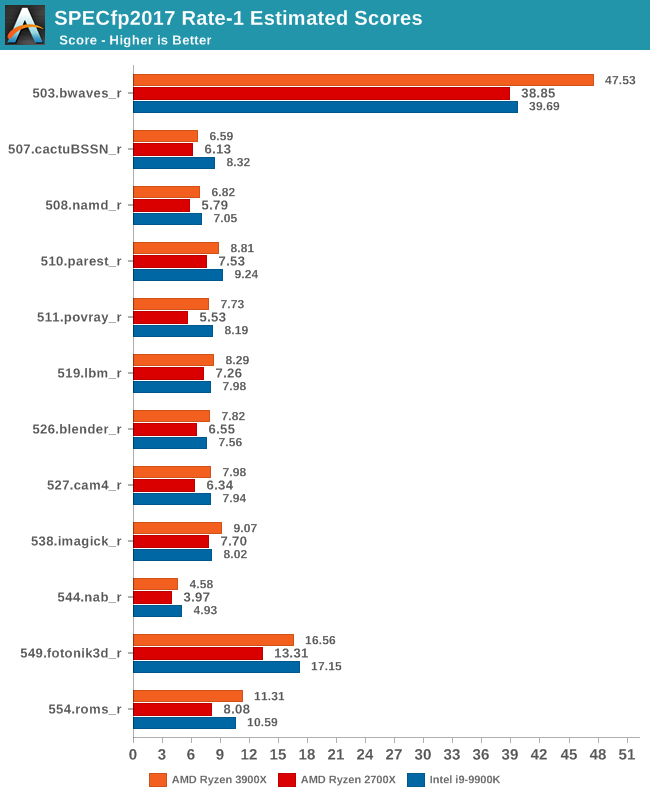
In the fp2017 suite, things are also quite even. Interesting enough here in particular AMD is able to leapfrog Intel’s 9900K in a lot more workloads, sometimes winning in terms of absolute performance and sometimes losing.
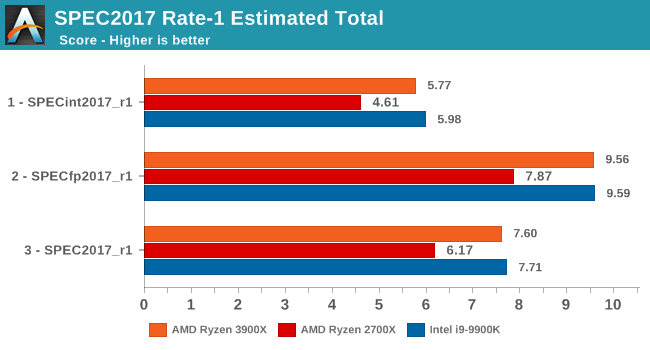
As for the overall performance scores, the new Ryzen 3900X improves by 23% over the 2700X. Although closing the gap greatly and completely, it’s just a hair's width shy of actually beating the 9900K’s absolute single-threaded performance.
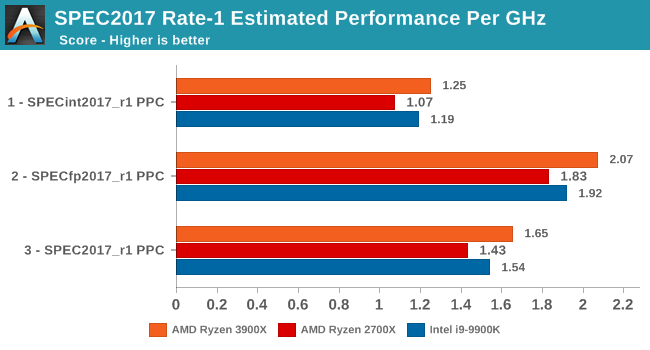
Normalising the scores for frequency, we see that AMD has achieved something that the company hasn’t been able to claim in over 15 years: It has beat Intel in terms of overall IPC. Overall here, the IPC improvements over Zen+ are 15%, which is a bit lower than the 17% figure for SPEC2006.
We already know about Intel’s new upcoming Sunny Cove microarchitecture which should undoubtedly be able to regain the IPC crown with relative ease, but the question for Intel is if they’ll be able to still maintain the single-thread absolute performance crown and continue to see 5GHz or similar clock speeds with the new core design.








447 Comments
View All Comments
miabk - Thursday, October 15, 2020 - link
Good working and positive thinking.https://unitconverters.online/