<b>Updated</b> CPU Cheatsheet - Seven Years of Covert CPU Operations
by Jarred Walton on August 28, 2004 9:00 AM EST- Posted in
- CPUs
Intel Cheat Sheet
 |
 |
 |
 |
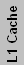 |
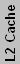 |
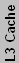 |
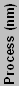 |
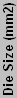 |
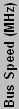 |
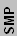 |
|
| Intel IA32/EM64T Processors | |||||||||||
| Covington | Cel | Slot 1 | 266/300 | 8K+8K | 7.5 | 350 | 118 | 66 | |||
| Mendocino | Cel ("A") | Slot 1 | 266-433 | 16K+16K | 128K | 19 | 250 | 154 | 66 | 1-2 | |
| Mendocino | Cel ("A") | 370 | 233-533 | 16K+16K | 128K | 19 | 250 | 154 | 66 | 1-2 | |
| Coppermine-128 | Cel ("A") | 370 | 533-766 | 16K+16K | 128K | 28* | 180 | 106 | 66 | ||
| Coppermine-128 | Cel ("A") | 370 | 800-1100 | 16K+16K | 128K | 28* | 180 | 106 | 100 | ||
| Klamath | P II | Slot 1 | 233-333 | 16K+16K | 512K | 7.5+37.2 | 350 | 203+L2 | 66 | 1-2 | |
| Deschutes | P II | Slot 1 | 266-333 | 16K+16K | 512K | 7.5+37.2 | 250 | 118+L2 | 66 | 1-2 | |
| Deschutes | P II | Slot 1 | 350-450 | 16K+16K | 512K | 7.5+37.2 | 250 | 118+L2 | 100 | 1-2 | |
| Deschutes | P II Xeon | Slot 2 | 400-450 | 16K+16K | 512K | 7.5+37.2 | 250 | 118+L2 | 100 | 1-2 | |
| Deschutes | P II Xeon | Slot 2 | 400-450 | 16K+16K | 1M | 7.5+74.4 | 250 | 118+L2 | 100 | 1-2 | |
| Deschutes | P II Xeon | Slot 2 | 450 | 16K+16K | 2M | 7.5+148.8 | 250 | 118+L2 | 100 | 1-2 | |
| Katmai | P III | Slot 1 | 450-600 | 16K+16K | 512K | 9.5+37.2 | 250 | 131+L2 | 100 | 1-2 | |
| Katmai | P III B | Slot 1 | 533-600 | 16K+16K | 512K | 9.5+37.2 | 250 | 131+L2 | 133 | 1-2 | |
| Tanner | P III Xeon | Slot 2 | 500, 550 | 16K+16K | 512K | 9.5+37.2 | 250 | 128+L2 | 100 | 1-8 | |
| Tanner | P III Xeon | Slot 2 | 500, 550 | 16K+16K | 1M | 9.5+74.4 | 250 | 128+L2 | 100 | 1-8 | |
| Tanner | P III Xeon | Slot 2 | 500, 550 | 16K+16K | 2M | 9.5+148.8 | 250 | 128+L2 | 100 | 1-8 | |
| Cascades** | P III Xeon | Slot 2 | 600-1000 | 16K+16K | 256K | 28.1 | 180 | 106-90 | 133 | 1-2 | |
| Cascades | P III Xeon | Slot 2 | 700 | 16K+16K | 1M | 180 | 210? | 100 | 1-4 | ||
| Cascades | P III Xeon | Slot 2 | 700, 900 | 16K+16K | 2M | 180 | 385 | 100 | 1-4 | ||
| Coppermine** | P III | Slot 1 | 550-1000 | 16K+16K | 256K | 28.1 | 180 | 106-90 | 100 | 1-2 | |
| Coppermine** | P III B | Slot 1 | 533-1000 | 16K+16K | 256K | 28.1 | 180 | 106-90 | 133 | 1-2 | |
| Coppermine** | P III E | 370 | 500-1100 | 16K+16K | 256K | 28.1 | 180 | 106-90 | 100 | 1-2 | |
| Coppermine** | P III EB | 370 | 533-1133 | 16K+16K | 256K | 28.1 | 180 | 106-90 | 133 | 1-2 | |
| Tualatin | Cel ("A") | 370 | 1000-1400 | 16K+16K | 256K | 28.1 | 130 | 80 | 100 | ||
| Tualatin | P III | 370 | 1000-1333 | 16K+16K | 256K | 28.1 | 130 | 80 | 133 | 1-2 | |
| Tualatin | P III S | 370 | 1133-1400 | 16K+16K | 512K | 45.9 | 130 | 110? | 133 | 1-2 | |
| Willamette | Cel-128 | 478 | 1700-1800 | 12Ku+8K | 128K | 36.5 | 180 | 217* | 100 | ||
| Willamette | P 4 | 423 | 1300-2000 | 12Ku+8K | 256K | 42 | 180 | 217 | 100 | ||
| Willamette | P 4 | 478 | 1500-2400 | 12Ku+8K | 256K | 42 | 180 | 217 | 100 | ||
| Foster | Xeon DP | 603 | 1400-2000 | 12Ku+8K | 256K | 42 | 180 | 217 | 100 | 1-2 | |
| Foster | Xeon MP | 603 | 1400, 1500 | 12Ku+8K | 256K | 512K | 42+37? | 180 | 100 | 1-4 | |
| Foster | Xeon MP | 603 | 1600 | 12Ku+8K | 256K | 1M | 42+74? | 180 | 100 | 1-4 | |
| Northwood | Cel | 478 | 1400-2800 | 12Ku+8K | 128K | 36.5 | 130 | 131? | 100 | ||
| Northwood | Mob. Cel. | 478 | 1400-2800 | 12Ku+8K | 256K | 130 | 100 | ||||
| Northwood** | P 4 | 478 | 1800-2600 | 12Ku+8K | 512K | 55 | 130 | 146-131 | 100 | ||
| Northwood** | P 4 "B" | 478 | 2267-2800 | 12Ku+8K | 512K | 55 | 130 | 146-131 | 133 | ||
| Northwood** | P 4 HTT | 478 | 3067 | 12Ku+8K | 512K | 55 | 130 | 146-131 | 133 | ||
| Northwood** | P 4 "C" | 478 | 2400-3400 | 12Ku+8K | 512K | 55 | 130 | 146-131 | 200 | ||
| Gallatin** | P 4 EE | 478 | 3200-3400 | 12Ku+8K | 512K | 2M | 55+123 | 130 | 231-237? | 200 | |
| Prestonia | Xeon DP | 603 | 1600-3000 | 12Ku+8K | 512K | 55 | 130 | 100 | 1-2 | ||
| Prestonia | Xeon DP | 604 | 2000-3067 | 12Ku+8K | 512K | 55 | 130 | 133 | 1-2 | ||
| Prestonia | Xeon DP | 604 | 3067-3200 | 12Ku+8K | 512K | 1M | 55+61 | 130 | 133 | 1-2 | |
| Gallatin | Xeon MP | 603 | 1500-2800 | 12Ku+8K | 512K | 1M | 55+61 | 130 | 100 | 1-4 | |
| Gallatin** | Xeon MP | 603 | 2000-2700 | 12Ku+8K | 512K | 2M | 55+123 | 130 | 231-237? | 100 | 1-4 |
| Gallatin | Xeon MP | 603 | 3000 | 12Ku+8K | 512K | 4M | 55+246? | 130 | 100 | 1-4 | |
| Prescott 256? | Cel D | 478/775 | 2400-3200 | 12Ku+16K | 256K | 90 | 133 | ||||
| Prescott | P 4 "A" | 478 | 2400-2800 | 12Ku+16K | 1M | 125 | 90 | 112 | 133 | ||
| Prescott | P 4 "E" | 478 | 2800-3400 | 12Ku+16K | 1M | 125 | 90 | 112 | 200 | ||
| Prescott | P 4 "E" | T/775 | 2800-??? | 12Ku+16K | 1M | 125 | 90 | 112 | 200 | ||
| Prescott | P 4 "E" | T/775 | ???-??? | 12Ku+16K | 2M | 90 | 200/266 | ||||
| Nocona | Xeon | T/775? | 2800-3600+ | 12Ku+16K | 1M | 125 | 90 | 112? | 200 | 1-2 | |
| Irindale | 2M | 90 | 200? | ||||||||
| Banias | Cel M | 478M | 1300-1500 | 32K+32K | 512K | 130 | 100 | ||||
| Banias | P M | 478M | 900-1800 | 32K+32K | 1M | 130 | 100 | ||||
| Dothan | Cel M | 478M | 900-1500 | 32K+32K | 1M | 90 | 100/133 | ||||
| Dothan | P M | 478M | 1000-2400 | 32K+32K | 2M | 90 | 100/133 | ||||
| Potomac | 65 | ||||||||||
| Smithfield | 2C | ||||||||||
| Jonah | P M? | 65? | 2C | ||||||||
| Tulsa | |||||||||||
| Merom | |||||||||||
| Conroe | |||||||||||
| Gilo | |||||||||||
| Whitefield | |||||||||||
|
|
|
|
|
|
|
|
|
|
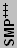 |
|
| Intel IA64 Processors | |||||||||||
| Merced**** | Itanium1 | PAC-418 | 733-800 | 16K+16K | 96K | 2-4M | 25+300 | 180 | 300 | 66 | 512 |
| McKinley+ | Itanium2 | PAC-611 | 900-1000 | 16K+16K | 256K | 1.5-3M | 221 | 180 | 421 | 100 | 512 |
| Deerfield | Itanium2 | PAC-611 | 1000, 1500? | 16K+16K | 256K | 1.5M? | 130 | 266? | 100 | 512 | |
| Madison++ | Itanium2 | PAC-611 | 1300-1500? | 16K+16K | 256K | 2-6M | 477 | 130 | 374 | 100 | 512 |
| Fanwood | Itanium2 | PAC-611 | 1500-1667? | 16K+16K | 256K | 9M | 130 | 100/166 | 512 | ||
| Montecito | Itanium2? | 24M? | 1700? | 90 | 2C? | ||||||
| Millington | Itanium2? | ||||||||||
| Dimona | Itanium2? | 2C | |||||||||
| Montvale | Itanium2? | ||||||||||
| Tukwila | Itanium2? | 16C? | |||||||||
| Foxton | Itanium2? | ||||||||||
| Pellston | Itanium2? | ||||||||||
| * Die Size and/or transistor count is based off a larger CPU core with a portion of the die disabled. | |||||||||||
| ** Various steppings/sources listed different die sizes. | |||||||||||
| *** The bus speed on the P4, PM, CM, and Itanium is quad-pumped, but the CPU multiplier is based off the listed speed. | |||||||||||
| **** Figures for Merced based off of 4M L3 cache version. | |||||||||||
| + Figures for McKinley based off 3M L3 cache version. | |||||||||||
| ++ Figures for Madison based off 6M L3 cache version. | |||||||||||
| +++ All Itaniums are said to be 512-way SMP capable, but this is more a factor of the motherboard and system design than the chip itself (I think). | |||||||||||
Notes on the Intel side of things are similar to the AMD side. There are again a couple cores that have an asterisk, indicating that the core was a "downgraded" version of a faster core, mostly with the Celeron processors. The double-asterisks are for chips that had varying die sizes in the various steppings. This probably occurs to a small degree in most chips, but in the Cascades, Coppermine, and Northwood cores, the changes were well documented and rather drastic. Thoroughbred A to B in AMD was only a 4 mm2 die size increase, while Coppermine fluctuated between 106 mm2 to 90 mm2, and Northwood went from 146 mm2 to 131 mm2. My guess is that it was due in part to hand-optimizing the layouts of the cores, but if anyone has precise details on the hows and whys of the decreases, I would like to hear them.
In order to make the charts fit nicely within the space constraints, x86-64 was removed from the column lists. As of now, the only Intel CPUs that are known to include x86-64 support are the Nocona and Potomac cores. There will almost certainly be more in the future. The L1 cache of the P4 chips includes a trace cache, which stores decoded micro-ops, abbreviated uops. In the chart above, the trace cache corresponds to the L1 instruction cache found in typical CPUs, and 12Ku+16K means the cache has the ability to store 12,000 micro-ops as well as a standard 16KB of L1 data cache.
You can see that Intel also has 2C (dual core) designs in their roadmap, as well as a highly speculative 16C (sixteen core!) Itanium. Whether or not Tukwila will ever see the light of day is anyone's guess - it could simply be a mythical design that some hardware sites fantasize about. Transistor count on such a chips would likely be several BILLION transistors. (On a different note, I was recently up in Tukwila, WA purchasing a mountain bike from a pawn shop. They didn't have any processors for sale, unfortunately.)
In contrast to AMD, Intel has had several major architecture revisions during the past seven or so years. AMD pretty much stuck with the K7/Athlon core for all their processors, which was admittedly a very good design. Intel, with its deeper pockets, attacked on numerous fronts. First was the Pentium III line, which more or less ended in a draw with their rival AMD. Prompted by marketing - because "clockspeed sells" - Intel came up with a radical new architecture dubbed NetBurst, the basis of the Pentium 4. NetBurst was a success on the desktop, but it really was too power hungry for laptops, so Intel decided to pursue a completely separate architecture for its mobile processors, which is now also penetrating Blade and other low voltage markets. Finally, shortly after the launch of the Athlon 64, Intel countered with their reworked NetBurst architecture and the Prescott line of processors. Add to this the long-awaited launch of IA-64 (roughly ten years in the making!) which was a completely new architecture that was even more radical than NetBurst. Intel has been busy, needless to say.
For their desktop chips, SMP was available both officially and unnofficially. The Celeron chips were not intended for SMP use and were never validated (by Intel) to work in such configurations. However, enterprising motherboard makers like Abit with their BP6 board allowed users to run early Celerons in dual CPU configurations. Intel put a stop to that with Coppermine-128 and Tualatin-256 (if you can call it that) Celerons. The P3 Xeon chips were all "multi-processor" configurations, capable of up to 8-way SMP. Such support was more dependent on the motherboard and chipset, though, so most setups topped out at 4-way SMP. Intel had a chipset that linked two 4-way buses together for their 8-way configuration, while ServerWorks created a chipset and motherboard that supported 8-way directly. In theory, they could have even followed Intel's example and linked two buses together to have a 16-way SMP setup, although at that point motherboard size becomes a difficult issue.
Itanium and SMP is a special case that needs further clarification. SMP is not always listed in the above chart, but all Itaniums are said to be capable of 512-way SMP. This is really more of a factor of the motherboard(s) and system design than the chip itself. For example, special high-end clustered systems have been built using AMD Athlon MP and Opteron CPUs as well as Xeon chips that have as many as 128 chips in a "single" system. Itanium is a similar case with SMP. Motherboards with up to eight sockets exist for Itanium, but 512-way SMP requires special hardware beyond the motherboard. (Please feel free to correct me if that's wrong, but I'm pretty sure this is the case. I can't imagine what a motherboard for 512 Itaniums would even look like if it were to exist - 8x8 feet in size?)
Update: A couple people pointed out issues with the naming of the Celeron processors. At the time, Intel used "A" to designate processors that overlapped an existing model. So there were cacheless Celeron 266/300 processors, and the 266/300 with 128K L2 cache had an "A" suffix. This occurred again with the Celeron 533, and once more with the Celeron 1000/1100. In a similar vein, the Klamath core was only 350 nm, while Deschutes was 250 nm. It was initially listed as 350/250 as there were certain Deschutes cores that were released as a pseudo-Klamath, for instance the P2 300 MHz SL2W8. There was not any way to actually tell (other that word of mouth) which P2 chips had the Klamath core and which had the Deschutes core. The chart has now been corrected by putting in a 250 nm 266-333 Deschutes line.








74 Comments
View All Comments
JarredWalton - Wednesday, September 1, 2004 - link
Jenand - thanks for the information. There are certainly some errors in the Itanium charts, but very few people seem to know much about the architecture, so I haven't gotten any corrections. Most of the future IA64 chips are highly speculative in terms of featurs.Incidentally, it looks like Tukwilla (and Dimona) will be 4 core designs, with motherboards support 4 CPUs, thus "16C" - or something like that. As for Fanwood, I really don't know much about it other than the name and some speculation that it *might* be the same as Madison9M. Or it might be a Dual Processor version of Madison, which is multi-processor.
http://endian.net/details.asp?ItemNo=3835
http://www.xbitlabs.com/news/cpu/display/200311101...
At the very least, Fanwood will have more than just a 9 MB cache configuration, it's probably safe to say.
JarredWalton - Wednesday, September 1, 2004 - link
If Prescott and Pentium M both use the exact same branch predictor, then yes, the Prescott would be more accurate than Banias. However, with the doubling of the cache size on Dothan, I can't imagine Intel would leave it with inferior branch prediction. So perhaps it goes something like this in terms of branch prediction accuracy:P6 cores
Willamette/Northwood
Banias
Prescott
Dothan
Possibly with the last two on the same level.
I'm still waiting to see if we can get pipeline stage information from Intel, but I have encountered several other sources online that refer to the Willamette/Northwood as having a 28 stage pipeline. Guess there's no use in beating a dead horse, though - either Intel will pass on information and we can have a definite, or it will remain an unknown. Don't hold your breath on Intel, though. :)
IntelUser2000 - Wednesday, September 1, 2004 - link
"Intel claims that the combination of the loop detector and indirect branch predictor gives Centrino a 20% increase in overall branch prediction accuracy, resulting in a 7% real performance increase."Sure, but Prescott also has Pentium M's branch predictor enhancements in addition to the enhancements made to Willamette, while Pentium M didn't get Willamette's enhancements, just the indirect branch predictor.
Yes it says 20% increase, but from what? PIII, P4? Prescott?
jenand - Tuesday, August 31, 2004 - link
There are a few errors and some missing information on the IPF sheet:1) Fanwood will get 4M(?) L3 or so, not 9M. You probably mixed it up with its bigger brother Madison9M, both to be released soon.
2)Foxton and Pelleston are code names for technologies used in Montecito, not CPU code names.
3) Dimona and Tukwila are "pairs" (just like Madison/Deerfield, Madison9M/Fanwood and Montecito/Millington) both will be made on 45nm nodes and are scheduled for 2007. Montvale is probably a shrink of Montecito or Millington to the 65nm node and will probably be launched in 2006.
4) Montecito and Millington will be made on 90nm and use the PAC-611 socket. The FSB of Montecito will be 100MHZ for compatibility reasons, but will also be introduced at a higher FSB (166MHz?) late in 2005.
5) Fanwood will probably get 100MHz and 133MHz FSB, not 166MHz. Same goes for Millington.
I hope it was helpful. Please note that I don't have any internal information I only read the rumors.
JarredWalton - Tuesday, August 31, 2004 - link
Heh... one last link. Hannibal discusses why the PM is able to have better branch prediction with a smaller BTB in his article about the PM. At the bottom of the following page is where he specifically discusses the improvements to the P4:http://castor.arstechnica.com/cpu/004/pentium-m/pe...
And his summary: "Intel claims that the combination of the loop detector and indirect branch predictor gives Centrino a 20% increase in overall branch prediction accuracy, resulting in a 7% real performance increase. Of course, the usual caveats apply to these statistics, i.e. the increase in branch prediction accuracy and that increase's effect on real-world performance depends heavily on the type of code being run. Improved branch prediction gives the PM a leg up not only in terms of performance but in terms of power efficiency as well. Because of its improved branch prediction capabilities, the PM wastes less energy speculatively executing code that it will then have to throw away once it learns that it mispredicted a branch."
He could be wrong, of course, but personally I trust his research on CPUs more than a lot of other sites - after all, he does *all* architectures, not just x86. Hopefully, Intel will provide me (Kristopher) with some direct answers. :)
JarredWalton - Tuesday, August 31, 2004 - link
In case that last wasn't clear, I'm not saying the CPU detection is really that blatant, but if the CPU detection is required for accuracy, it *could* be that bad. Rumor, by the way, puts the Banias core at 14 or 15 stages, and the Dothan *might* add one more stage.JarredWalton - Tuesday, August 31, 2004 - link
Regarding Pentium M, I believe the difference to the branch prediction isn't merely a matter of size. It has a new indirect branch predictor, as well as some other features. Basically, P-M is designed for power usage first, and so they made a lot more elegant design decisions at times, whereas Northwood and Prescott are more of a brute force approach.As for the differences between various AT articles, it's probably worth pointing out that this is the first article I've ever written for Anandtech, so don't be too surprised that it has some differences of opinion. Who's right? It's difficult to say.
As for the program mentioned in that thread, I downloaded it and ran it on my Athlon 64. You know what the result was? 13.75 to 13.97 cycles. Since a branch miss doesn't actually necessitate a flush of the entire pipeline, that would mean that it's estimating the length of the A64 as probably 15 or 16 stages - off by a factor of 33% or so. If it were off by that same amount on Prescott, that would put Prescott at [drumroll...] 23 stages.
I've passed on some questions for Intel to Kristopher Kubuki, so maybe we can get the real poop. Until then, it's still a case of "nobody knows for sure". Estimating pipeline lengths based off of a program that reports accurate results on P4 and Northwood cores is at best a guess, I would say.
Incidentally, I looked at the source code, and while I haven't really studied it extensively, there is a CPU detection, so the mispredict penalty is calculated differently on P4, P6, and *other* architectures. Maybe it's okay, maybe it's not, but if accurate results are dependent on CPU detection, that sort of calls the whole thing into question.
if CPU=P6 then printf("12 stages.\n")
else if CPU=P4 then printf("10 stages.\n")
else if....
Hopefully, it *is* relatively accurate, but as I said, ~14 cycles mispredict penalty on an Athlon 64 is either incorrect, or AMD actually created a 15 stage pipeline and didn't tell anyone. :)
IntelUser2000 - Monday, August 30, 2004 - link
Okay, I don't know further than that. But one question: Since the old P4 article from Anandtech states 10 stage pipelin P6 core, and Prescott is claimed to have 31 stages and you claim otherwise, it tells that there is individual errors in the SAME site. So whether Hannibal's site can be trusted is doubtful because of that fact too, no? Also, take a look at this link: http://www.realworldtech.com/forums/index.cfm?acti...I asked a guy in the forums about it and that link is about the responses to it.
One example Hannibal's site may be wrong is this: http://arstechnica.com/cpu/004/prescott-future/pre...
At the end of that link it says: "There's actually another reason why the Pentium M won't benefit as much from hyperthreading. The Pentium M's branch predictor is superior to Prescott's, so the Pentium M is less likely to suffer from instruction-related pipeline stalls than the Prescott. This improved branch prediction, in combination with its shorter pipeline, means improved execution efficiency and less of a need for something like hyperthreading."
Now, we know Pentium M has shorter pipeline than Prescott but better branch prediction? I really think its wrong, since one of the major improvements of BOTH Prescott and Pentium M in branch prediction is improvements in indirect branch prediction, PLUS, Prescott and Northwood I believe, has bigger BTB buffer size, somewhere in the order of 8x, because Pentium M used indirect branch prediction improvements to save die size and putting more buffer definitely doesn't coincide with that.
Fishie - Monday, August 30, 2004 - link
This is a great summary of the processor cores. I would like to see the same thing done with video cards.JarredWalton - Monday, August 30, 2004 - link
#49 - Did you even read the links in post #44? Did you read post #44? Let's make it clear: the Willamette and Northwood cores were 20 stage pipelines coupled to an 8 stage prefetch/decode unit (which feeds into the trace cache). This much, we know for sure. The Prescott core appears to be 23 stages with the same (essentially) 8 stage prefetch/decode unit. So, you can call early P4 cores 20 stages, in which case Prescott is 23 stages, or you can call Prescott 31 stages, in which case early P4 cores were 28 stages.If you look at the chart in the link to Anandtech, notice how the P4 pipeline is lacking in fetch and decode stages? Anyway, there's nothing that says the AT chart you linked from Aug 2000 is the DEFINITIVE chart. People do make errors, and Intel hasn't been super forthcoming about their pipelines. I'll give you a direct link to where Hannibal talks about the P6 and P4 pipelines - take it up with him if you must:
http://arstechnica.com/cpu/004/pentium-1/pentium-1...
Synopsis: In the AT picture, the P6 pipeline has 2 fetch and 2 decode stages, while Hannibal describes it as 3.5 BTB/Fetch stages and 2.5 Decode stages.
http://arstechnica.com/cpu/01q2/p4andg4e/p4andg4e-...
Here, the P4 and G4e architectures are compared, but if you read this page, it explains the trace cache and how it effects things. Specifically: "Only when there's an L1 cache miss does that top part of the front end kick in in order to fetch and decode instructions from the L2 cache. The decoding and translating steps that are necessitated by a trace cache miss add another eight pipeline stages onto the beginning of the P4's pipeline, so you can see that the trace cache saves quite a few cycles over the course of a program's execution."
-----------------------
Further reading:
http://episteme.arstechnica.com/eve/ubb.x?a=tpc&am...
The comments in the "Discuss" section of the article contain further elaboration by Hannibal on the Prescott: "The 31 stages came from the fact that if you include the trace cache in the pipeline (which Intel normally doesn't and I didn't here) then the P4's pipeline isn't 20 stages but 28 (at least I think that's the number). So if you add three extra stages to 28 you get 31 total stages."
The problem is, Intel simply isn't coming out and directly stating what the facts are. It *could* be that Prescott is really 31 stages (as Intel has said) plus another 8 to 10 stages of fetch/decode logic, putting the "total" length at 39 to 41 stages. However, given the clockspeed scaling - rather, the lack thereof - it would not be surprising to have it "only" be 23 stages plus 8 fetch/decode stages. After all, the die shrink to 90 nm should have been able to push the Northwood core to at least 4 GHz, which seems to be what the Prescott is hitting as well.
Unless you actually work for Intel and can provide a definitive answer? I, personally, would love some charts from Intel documenting all of the stages of both the initial NetBurst pipeline as well as the Prescott pipeline. (Maybe I should mention this to Anand...?)