Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTInference: ResNet-50
After training your model on training data, the real test awaits. Your AI model should now be able to apply those learnings in the real world and do the same for new real-world data. That process is called inference. Inference requires no back propagation as the model is already trained – the model has already determined the weights. Inference also can make use of lower numerical precision, and it has been shown that even the accuracy from using 8-bit integers is sometimes acceptable.
From a high-level workflow perfspective, a working AI model is basically controlled by a service that, in turn, is called from another software service. So the model should respond very quickly, but the total latency of the application will be determined by the different services. To cut a long story short: if inference performance is high enough, the perceived latency might shift to another software component. As a result, Intel's task is to make sure that Xeons can offer high enough inference performance.
Intel has a special "recipe" for reaching top inference performance on the Cascade Lake, courtesy of the DL Boost technology. DLBoost includes the Vector Neural Network Instructions, which allows the use of INT8 ops instead of FP32. Integer operations are intrinsically faster, and by using only 8 bits, you get a theoretical peak, which is four times higher.
Complicating matters, we were experimenting with inference when our Cascade Lake server crashed. For what it is worth, we never reached more than 2000 images per second. But since we could not experiment any further, we gave Intel the benefit of the doubt and used their numbers.
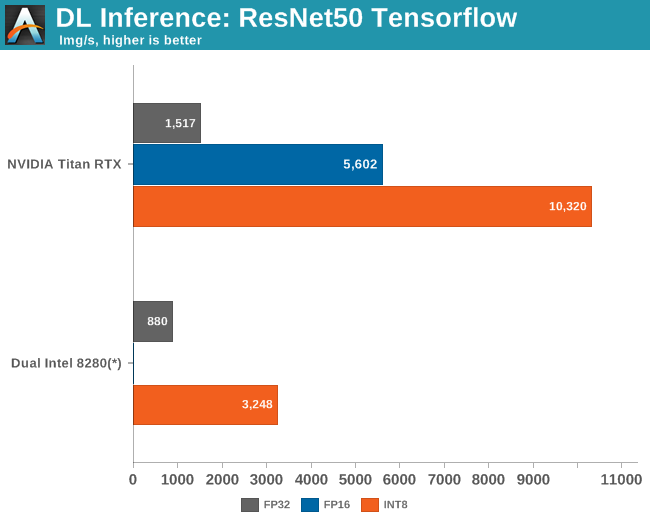
Meanwhile the publication of the 9282 caused quite a stir, as Intel claimed that the latest Xeons outperformed NVIDIA's flagship accelerator (Tesla V100) by a small margin: 7844 vs 7636 images per second. NVIDIA reacted immediately by emphasizing performance/watt/dollar and got a lot of coverage in the press. However, the most important point in our humble opinion is that the Tesla V100 results are not comparable, as those 7600 images per second were obtained in mixed mode (FP32/16) and not INT8.
Once we enable INT8, the $2500 Titan RTX is no less than 3 times faster than a pair of $10k Xeons 8280s.
Intel cannot win this fight, not by a long shot. Still, Intel's efforts and NIVIDA’s poking in response show how important it is for Intel to improve both inference and training performance; to convince people to invest in high end Xeons instead of a low end Xeon with a Tesla V100. In some cases, 3 times slower than NVIDIA's offering might be good enough as the inference software component is just one part of the software stack.
In fact, to really analyze all of the angles of the situation, we should also measure the latency on a full-blown AI application instead of just measuring inference throughput. But that will take us some more time to get that one right....








56 Comments
View All Comments
Gondalf - Tuesday, July 30, 2019 - link
Kudos to the article from a technical point of view :), a little less for the weak analysis of the server market. Johan say that Intel is slowing down in server but the server market is growing fast.Unfortunately it is not: Q1 this year was the worst quarter of server market in 8 quarters with a grow of only 1%. Q2 will be likely on a negative trend, moreover there is a general consensus that 2019 will be a negative year with a drop in global revenue.
So there recent Intel drop is consistent with a drop of the demand in China in Q2.
To be underlined that a GPU has to be piloted and every GPU like Tesla is up, there is a one or two Xeons on the motherboard.
GPU is only an accelerator, but without a cpu is useless. Intel slides about upcoming threat from competitors are related to the existence of AMD in HPC , IBM and some sparse ARM based SKUs for custom applications.
A GPU is welcomed, it helps to sell more Xeons.
eastcoast_pete - Tuesday, July 30, 2019 - link
More a question than anything else: What is the state of AI-related computing on AMD (graphics) hardware? I know NVIDIA is very dominant, but is it mainly due to an existing software ecosystem?BenSkywalker - Wednesday, July 31, 2019 - link
AMD has two major hurdles to overcome when specifically looking at AI/ML on GPUs, essentially non existent software support and essentially non existent hardware support. AMD has chosen the route of focusing on general purpose cores that can perform solidly on a variety of traditional tasks both in hardware and software. AI/ML benefit enormously from specialized hardware that in turn takes specialized software to utilize.This entire article is stacking up $40k worth of Intel CPUs against a consumer nVidia part and Intel gets crushed whenever nVidia can use it's specialized hardware. Throw a few Tesla V100s in to give us something resembling price parity and Intel would be eviscerated.
AMD needs tensor cores, a decade worth of tools development, and a decade worth of pipeline development(university training, integration into new systems and build out on to those systems, not hardware pipeline) in order to get where nVidia is now if they were standing still.
The software ecosystem is the biggest problem long term, everyone working in the field uses CUDA whenever they can, even if AMD mopped the floor with nVidia on the hardware side, for their GPUs to get traction they would need all the development tools nVidia has spent a decade building, but right now their GPUs are throttled by nVidia because of specialized hardware.
abufrejoval - Tuesday, July 30, 2019 - link
Some telepathy must be involved: Just a day or two before this appeared online, I was looking for Johan de Gelas' last appearance on AT in 2018 and thinking that it was high time for one of my favorite authors to publish something. Ever so glad you came out with the typical depth, quality and relevance!While GAFA and BATX seem to lead AI and the frameworks, their problems and solutions mostly fit their needs and as it turns out the vastest number of use cases cannot afford the depth and quality they require, nor do they benefit from it, either: If the responsibility of your AI is to monitor for broken drill bits from vibration, sound, normal and thermal visuals, the ability to identify cats in every shape and color has no benefit.
The big guys typically need to solve a sharply defined problem in a signle domain at a very high quality: They don't combine visual with audio and the inherent context in time-series video is actually ignored, as their AIs stare at each frame independently, hunting for known faces or things to tag and correlate social graphs and products.
Iterating over ML approaches, NN designs and adequate hyperparameters for training requires months even with clusters of DGX workstations and highly experience ML experts. What makes all that effort worthwhile is that the inference part can then run at relatively low power on your mobile phone inside WeChat, Facebook, Instagram, Google keyboard/translate (or some other "innocent" background app) at billions of instances: Trial and train until you have trained the single sufficiently good network design in days, weeks or even months and then you can deploy inference to billions of devices on battery power.
Few of us smaller IT companies can replicate that, but again, few of us need to, because we have a vastly higher number of small problems to solve and with a few orders of magnitude less of a difference in training:inference efforts: 1Watt of difference makes or brakes the usability of inference model on mobile target devices, 100 Watts of difference in a couple of servers running a dozen instances of a less optimized and well trained model won't justify an ML-expert team working through another five pizzas.
As the complexity of your approach (e.g. XGBoost or RF) is perhaps much smaller or your network are much simpler than those of GAFA/BATX you actually worry about how to scale-in not out and batch dozens of training for model iteration and mix that with some QA or even production inference streams on GPUs which Linux understands or treats little better than a printer with DMA.
Intel quite simply understands that while you get famous with the results you get from training AIs e.g. on GPUs, the money is made from inference at the lowest power and lowest operational overhead: Linux (or Unix for that matter), knows how to manage virtual memory (preferably uniform) and CPUs (preferably few); a memory hierarchy deeper than the manual for your VCR and more types and numbers of cores than Unics first hard disk had in blocks, confuse it.
But I'd dare say that AMD understood it much longer and much better. When they came up with the HSA on their first APUs, this GPGPU blend, which allowed switching the compute model with a function call makes CUDA look very brutish indeed.
Writing code able to take full advantage of these GPGPU capabilites is still a nightmare, because high-level languages have abstraction levels far too low for what these APUs or VNNI CPUs can execute in a single clock cycle, but from the way I read it, the Infinity Fabric is about making those barriers as low as they can possibly be in terms of hardware and memory space.
And RISC-V goes beyond what all x86 advocates still suffer from: An instruction set that's not designed for modular expandability.
FunBunny2 - Wednesday, July 31, 2019 - link
"Trial and train until you have trained the single sufficiently good network design in days, weeks or even months and then you can deploy inference to billions of devices on battery power."when and if this capability is used for something useful, e.g. cure for cancer, rather than yet another scheme to extract moolah from rubes. then I'll be interested.
keg504 - Tuesday, July 30, 2019 - link
Why do you say on the testing page that AMD is colour coded in orange, and then put them in grey?808Hilo - Wednesday, July 31, 2019 - link
Client/server renamed again...There is no AI. That stuff is very very dumb. look at the diagramm above. Nothing new. Data, script does something, parsing and readout of vastly unimportant info. I have not seen a single meaningful AI app. Its now year 25 of the Internet and I am terribly bored. Next please.
J7SC_Orion - Wednesday, July 31, 2019 - link
This explains very nicely why Intel has been raiding GPU staff and pouring resources into Xe Discrete Graphics...if you can't beat them, join them ?tibamusic.com - Saturday, August 3, 2019 - link
Thank you very much.Threska - Saturday, August 3, 2019 - link
What a coincidence. The latest humble bundle is "Data Analysis & Machine Learning by O'Reilly"https://www.humblebundle.com/books/data-analysis-m...