Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTExploring Parallel HPC
HPC benchmarking, just like server software benchmarking, requires a lot of research. We are definitely not HPC experts, so we will limit ourselves to one HPC benchmark.
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP.
To be fair, NAMD is mostly single precision. And, as you probably know, the Titan RTX was designed to excel at single precision workloads; so the NAMD benchmark is a good match for the Titan RTX. Especially now that the NAMD authors reveal that:
Performance is markedly improved when running on Pascal (P100) or newer CUDA-capable GPUs.
Still, it is an interesting benchmark as the NAMD binary is compiled with Intel ICC and optimized for AVX. For our testing, we used the "NAMD_2.13_Linux-x86_64-multicore" binary. This binary supports AVX instructions, but only the "special” AVX-512 instructions for the Intel Xeon Phi. Therefore, we also compiled an AVX-512 ICC optimized binary. This way we can really measure how well the AVX-512 crunching power of the Xeon compares to NVIDIA’s GPU acceleration.
We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
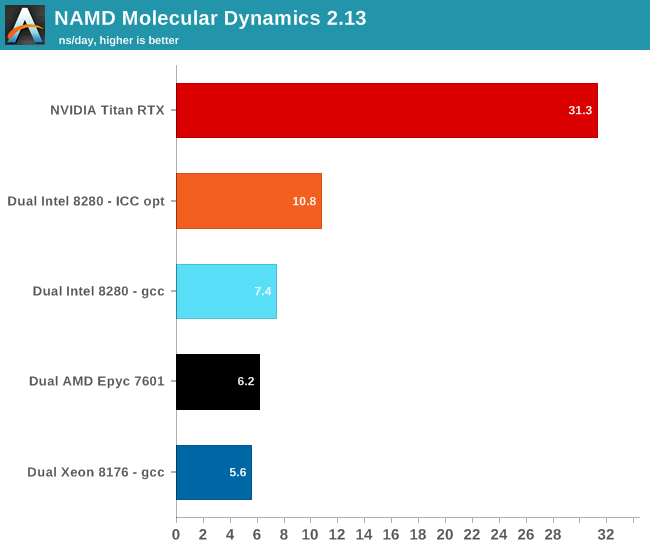
Using AVX-512 boosts performance in this benchmark by 46%. But again, this software runs so much faster on a GPU, which is of course understandable. At best, the Xeon has 28 cores running at 2.3 GHz. Each cycle 32 single precision floating operations can be done. All in all, the Xeon can do 2 TFLOPs (2.3 G*28*32). So a dual Xeon setup can do 4 TFLOPs at the most. The Titan RTX, on the other hand, can do 16 TFLOPs, or 4 times as much. The end result is that NAMD runs 3 times faster on the Titan than on the dual Intel Xeon.








56 Comments
View All Comments
C-4 - Monday, July 29, 2019 - link
It's interesting that optimizations did so much for the Intel processors (but relatively less for the AMD ones). Who made these optimizations? How much time was devoted to doing this? How close are the algorithms to being "fully optimized" for the AMD and nVidia chips?quorm - Monday, July 29, 2019 - link
I believe these optimizations largely take advantage of AVX512, and are therefore intel specific, as amd processors do not incorporate this feature.RSAUser - Monday, July 29, 2019 - link
As quorm said, I'd assume it's due to AVX512 optimizations, the next generation of AMD Epyc CPU's should support it, and I am hoping closer to 3GHz clock speeds on the 64 core chips, since it seems the new ceiling is around the 4GHz mark for 16 all-core.It will be an interesting Q3/Q4 for Intel in the server market this year.
SarahKerrigan - Monday, July 29, 2019 - link
Next generation? You mean Rome? Zen2 doesn't have any AVX512.HStewart - Tuesday, July 30, 2019 - link
I believe AMD AVX 2 is dual-128 bit instead of 256bit - so AVX 512 would probably be quad 128bit .jospoortvliet - Tuesday, July 30, 2019 - link
That’s not really how it works, in the sense that you explicitly need to support the new instructions... and amd doesn’t (plan to, as far as we know).Qasar - Tuesday, July 30, 2019 - link
from wikipedia :" AVX2 is now fully supported, with an increase in execution unit width from 128-bit to 256-bit. "
" AMD has increased the execution unit width from 128-bit to 256-bit, allowing for single-cycle AVX2 calculations, rather than cracking the calculation into two instructions and two cycles."
which is from here : https://www.anandtech.com/show/14525/amd-zen-2-mic...
looks like AVX2 is single 256 bit :-)
name99 - Monday, July 29, 2019 - link
Regarding the limits of large batches: while this is true in principle, the maximum size of those batches can be very large, is hard to predict (at leas right now) and there is on-going work to increase the sizes, This link describes some of the issue and what’s known:http://ai.googleblog.com/2019/03/measuring-limits-...
I think Intel would be foolish to pin many hopes on the assumption that batch scaling will soon end the superior performance of GPUs and even more specialized hardware...
brunohassuna - Monday, July 29, 2019 - link
Some information about energy consumption would very useful in comparisons like thatozzuneoj86 - Monday, July 29, 2019 - link
My first thought when clicking this article was how much more visibly-complex CPUs have gotten in the past ~35 years.Compare the bottom of that Xeon to the bottom of a CLCC package 286:
https://en.wikipedia.org/wiki/Intel_80286#/media/F...
And that doesn't even touch the difference internally... 134,000 transistors to 8 million and from 16Mhz to 4,000Mhz. The mind boggles.