Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTRecurrent Neural Networks: LSTM
Our loyal readers know that we love real-world enterprise benchmarks. So in our quest for better benchmarks and better data, Pieter Bovijn, the head of research at the MCT IT Bachelor (dutch), turned a real-world AI model into a benchmark.
The input of the model is time series data, which is used to make predictions on how the time series will behave in the future. As this is a typical sequence prediction problem, we used a Long Short-Term Memory (LSTM) network as neural network. A type of RNN, LSTM selectively "remembers" patterns over a certain duration of time.
LSTM however come with the disadvantage that they are a lot more bandwidth intensive. We quote a recent paper on the topic:
LSTMs exhibit quite inefficient memory access pattern when executed on mobile GPUs due to the redundant data movements and limited off-chip bandwidth.
So we were very curious about how the LSTM network would behave. After all, our server Xeons have ample bandwidth, with a massive 38.5 MB of L3 and six channels of DDR4-2666/2933 (128-141 GB/s per socket). We run this test with 50 GB of data, and train the model for 5 epochs.
Of course, you have the make the most of the available AVX/AVX2/AVX512 SIMD power. That is why we tested with 3 different setups
- We used out of the box TensorFlow with conda
- We tested with the Intel optimized TensorFlow from PyPi repo
- We optimized from source using Bazel. This allowed us to use the very latest version of TensorFlow.
The results are very interesting.
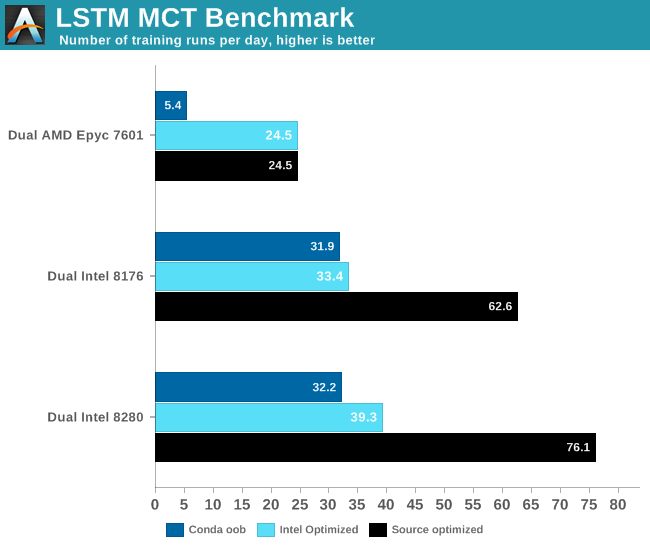
The most intensive TensorFlow applications are typically run on GPUs, so extra care must be taken when you test on a CPU. AMD's Zen core only has two 128-bit FMACs, and is limited to (256-bit) AVX2. Intel's high-end Xeons have two 256-bit FMACs and one 512-bit FMAC. In other words, on paper Intel's Xeon can deliver four times more FLOPs per clock cycle than AMD. But only if the software is right. Intel has been working intensively with Google to optimize TensorFlow for Intel new Xeons out of necessity: it has to offer a credible alternative in those situations where an NVIDIA Tesla is simply too expensive. Meanwhile, AMD hopes that ROCm catches on and that in the future software engineers run TensorFlow on a Radeon Pro.
Of course, the big question is how this compares to a GPU. Let us see how our NVIDIA Titan RTX deals with this workload.
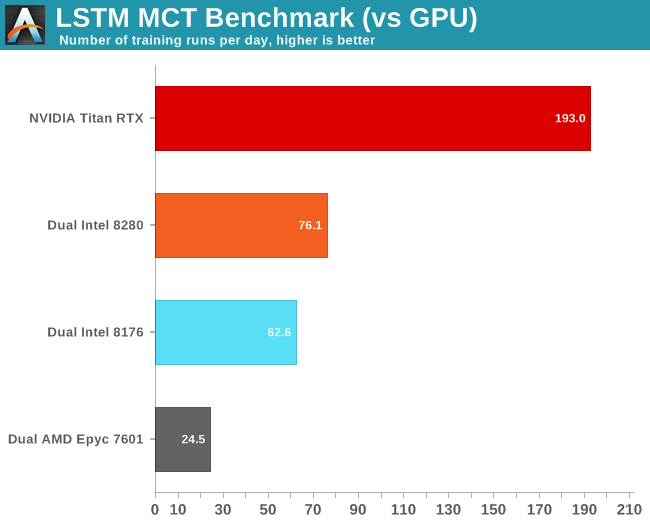
First of all, we noticed that FP16 did not make much of a difference. Secondly, we were quite amazed that our Titan RTX was less than 3 times faster than our dual Xeon setup.
Investigating further with NVIDIA's System Management Interface (SMI), we found out that GPU did run at a its highest turbo speed: 1.9 GHz, which is higher than the expected 1.775 GHz. Meanwhile utilization dropped to 40% from time to time.
Ultimately this is another example of how real-world applications behave differently from benchmarks, and how important software optimization is. If we would have just used conda, the results above would be very different. Using the right optimized software made the application run 2 to 6 times faster. Also, this another data point that proves that CNNs might be one of the best use cases for GPUs. You should use a GPU to decrease training times of complex LSTMs of course. Still, this kind of neural network is a bit more tricky - you cannot simply add more GPUs to further decrease training time.








56 Comments
View All Comments
tipoo - Monday, July 29, 2019 - link
Fyi, when on page 2 and clicking "convolutional, etc" for page 3, it brings me back to the homepageRyan Smith - Monday, July 29, 2019 - link
Fixed. Sorry about that.Eris_Floralia - Monday, July 29, 2019 - link
Johan's new piece in 14 months! Looking forward to your Rome review :)JohanAnandtech - Monday, July 29, 2019 - link
Just when you think nobody noticed you were gone. Great to come home again. :-)Eris_Floralia - Tuesday, July 30, 2019 - link
Your coverage on server processors are great!Can still well remember Nehalem, Barcelona, and especially Bulldozer aftermath articles
djayjp - Monday, July 29, 2019 - link
Not having a Tesla for such an article seems like a glaring omission.warreo - Monday, July 29, 2019 - link
Doubt Nvidia is sourcing AT these cards, so it's likely an issue of cost and availability. Titan is much cheaper than a Tesla, and I'm not even sure you can get V100's unless you're an enterprise customer ordering some (presumably large) minimum quantity.olafgarten - Monday, July 29, 2019 - link
It is available https://www.scan.co.uk/products/32gb-pny-nvidia-te...abufrejoval - Tuesday, July 30, 2019 - link
Those bottlenecks are over now and P100, V100 can be bought pretty freely, as well as RTX6000/8000 (Turings). Actually the "T100" is still missing and the closest siblings (RTX 6000/8000) might never get certified for rackmount servers, because they have active fans while the P100/V100 are designed to be cooled by server fans. I operate a handful of each and getting budget is typically the bigger hurdle than purchasing.SSNSeawolf - Monday, July 29, 2019 - link
I've been trying to find more information on Cascade Lake's AI/VNNI performance, but came up dry. Thanks, Johan. Eagerly putting this aside for my lunch reading today.