Linux and L2 Cache; Sempron vs. Athlon
by Kristopher Kubicki on August 18, 2004 2:29 AM EST- Posted in
- Linux
John The Ripper
We used John the Ripper (JTR) 1.6.37 as a loose benchmark of encryption/hashing. The 1.6 "stable" branch for JTR is actually very dated, so we used the much more updated 1.6.37 tree instead. There are fewer hand coded ASM routines in the 1.6.37 release which allows us to better directly compare our processors.
Just like the chess benchmarks from before, we used four different configurations to compile JTR. The first configuration is identical to "make linux-x86-any-elf" target.
- Configuration 1.) -O2
- Configuration 2.) -O3
- Configuration 3.) -O2 -march
- Configuration 4.) -O3 -march
Obviously, we used the athlon arch flag for the Athlon XP processor and k8 for the Athlon 64.
![John The Ripper 1.6.37 - DES [24/32 4K]](https://images.anandtech.com/graphs/linux and l2 cache sempron vs _081704110838/3577.png)
![John The Ripper 1.6.37 - Blowfish (x32) [32/64]](https://images.anandtech.com/graphs/linux and l2 cache sempron vs _081704110838/3578.png)
![John The Ripper 1.6.37 - MD5 [32/64 X2]](https://images.anandtech.com/graphs/linux and l2 cache sempron vs _081704110838/3579.png)
It is likely that JTR uses some optimized ASM code for the Athlon XP, which is why we see such good marks for a two year old CPU.
OpenSSL
The most comprehensive OpenSSL "speed" benchmarks can be downloaded as separate text files (Athlon 2200+, Athlon 64 3000+, Sempron 3100+) but we also provided some graphical mappings below.
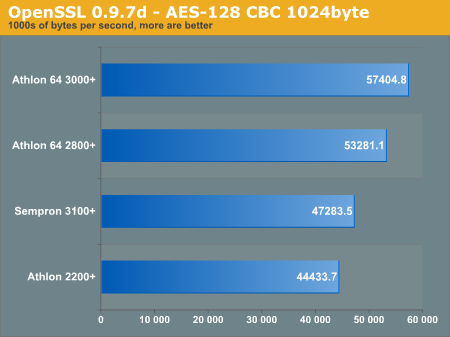
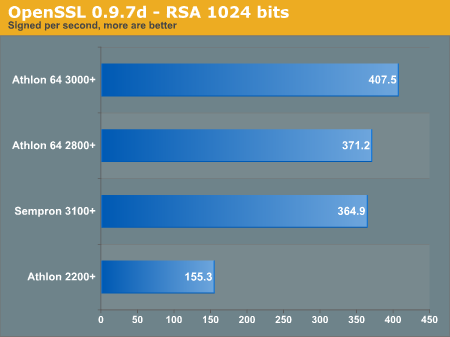
The AES speed test scales very well across AMD's budget computing line, and we really see the additional L2 cache increasing thoroughput. However, we go down one graph to see that signing RSA keys had very little performance increase with the 512KB L2 cache.








59 Comments
View All Comments
Matthew Daws - Friday, August 20, 2004 - link
Kris: Oh, okay, sorry, yes, that makes sense. Have you tried the Windows executable yet? I've verified that with TSCP 1.7.3 I'm getting reasonable results, so it seems likely that my results with v1.8.1 are not too far off base...--Matt
KristopherKubicki - Friday, August 20, 2004 - link
Rys:Correct, but that doesnt mean it still does not lack 64-bit addressing ;) And in reality, how critical would any desktop CPU today need to address more than 48bits ? Isnt that something like 1TB?
Kristopher
KristopherKubicki - Friday, August 20, 2004 - link
Matthew: I read this:>You shouldn't see any difference with linux:
>indeed, only a linux box I have access to, with GCC
>3.2.2 (I *think* it's a P4 2.8GHz, but I'm not 100%
>sure: I'm doing a remote-login right now, so cannot
>check!) I get 365K with (-O3 -march=pentium4).
So your 2.8C is getting the same marks as my 3.6 nocona -- is what i meant.
Kristopher
Rys - Friday, August 20, 2004 - link
You repeatedly mention the Sempron's 'lack of 64-bit addressing'. None of the CPU's on test, including the Athlon 64, can address a 64-bit memory space. All current AMD64 implementations can only address a 40-bit physical address space and a 48-bit virtual address space.Rys
Matthew Daws - Friday, August 20, 2004 - link
Kris,I am confused: in the link you gave me, the Xeon is getting circa 350K, which is way better than I getting, as expected... Okay, so it's low clock for clock, but you said: "Youre getting higher numbers than i got with my Xeon 3.6GHz chip."
--Matt
Matthew Daws - Friday, August 20, 2004 - link
Kris,I've downloaded TSCP 1.7.3 which Tom Kerrigan has collected a lot of benchmarking data about. It also gives a MIPS rating: I get 2136 MIPS (with GCC -O3 -march=pentium4) and 2174 (with the included windows benchmark) These compare well with the data on his website (http://home.comcast.net/~tckerrigan/bench.html) where this puts my 2GHZ Celeron at about the same level an a P4 1800, which seems reasonable for a heavy CPU benchmark.
I suggested that on your test system you run the precompiled Windows executable which Tom gives: this should give an approximate value, as Visual C++ and GCC produce roughly the same performance of code, and with this benchmark, switching between Windows and Linux really shouldn't make a difference. You might also try the earlier code, as I have just done, and then you'll have a 3rd party (namely Tom's list) to compare against...
--Matt
Wesley Fink - Friday, August 20, 2004 - link
#32 - I would think the CPU scaling charts in Doom 3 at http://www.anandtech.com/cpuchipsets/showdoc.aspx?... would be all the proof you need to see the 3100+ is the better value. The 3100+ is 75.3FPS, the XP 3200+ is 68FPS, and the 2500+ is 55.6FPS.If DX9 game performance is not convincing, then you might refresh your memory in pages and pages of benchmarks comparing the 3100+ 754 and 2500+ Socket A in http://www.anandtech.com/cpuchipsets/showdoc.aspx?...
thornc - Friday, August 20, 2004 - link
My main problem with the article is that the Athlon XP 2500+ with Barton core was not included!I am thinking of getting a new system and I intend to use a Barton XP, but if I might change my mind if I see prove that the Sempron is a better deal.
TauCeti - Friday, August 20, 2004 - link
Hi Matthew, Kris and also hello to dougSF30 from siliconinvestor ;)Nice discussion here!
I think there is a way to _really_ understand e.g. the TSCP benchmark scores on all AMD CPUs.
AMD offers (for free) the "AMD CodeAnalyst™ Performance Analyzer for Linux 2.2" and the "AMD Simulation Utilities 2.1"
afaik it is possible with those tools to profile any target code (in this case the TSCP bench) and then even simulate the execution of that code for different CPUs down to assembler code/cache state and even deeper into CPU execution unit usage.
quote from AMD: "The data presented is at the assembly instruction level and is not intended to assist a programmer working in a high-level language. The detailed data on the execution of each instruction takes into account the previous instructions executed and the state of the processor caches. The data is obtained by running the target block of code, then using the debug capabilities of the processor to single step through each opcode to obtain an execution trace. This execution trace is then fed into a Processor Simulation that analyzes the execution."
I think getting used to this tool and knowing how to interpret the results would be very fruitful for any reviewer (and programmer). Dresdenboy at mersenneforum.org used it to dissect the low SSE2 Performance of the AMD64s in the prime95 code.
The downside is that this does not look like an easy task even for a 'normal' experienced programmer. I even don't know if such large code-blocks like TSCPs bench can be used with the tool or if it is only suitable for inner-loop optimization.
Tau
balzi - Friday, August 20, 2004 - link
So I take it by the ignorance that no one really cares if the graphs are readable -- oh well.. I'll still read Anandtech but maybe I won't enjoy it as much in the future.