Arm's New Mali-G77 & Valhall GPU Architecture: A Major Leap
by Andrei Frumusanu on May 27, 2019 12:00 AM ESTIntroducing Valhall: A new ISA for Modern Workloads
At the heart of the new Valhall architecture is Arm’s new execution core that differs significantly from its predecessor. It’s still a scalar design, however unlike Bifrost’s unusually narrow 4 and 8-wide design, the new execution core is more akin to what we see from desktop GPU vendors such as AMD and Nvidia.
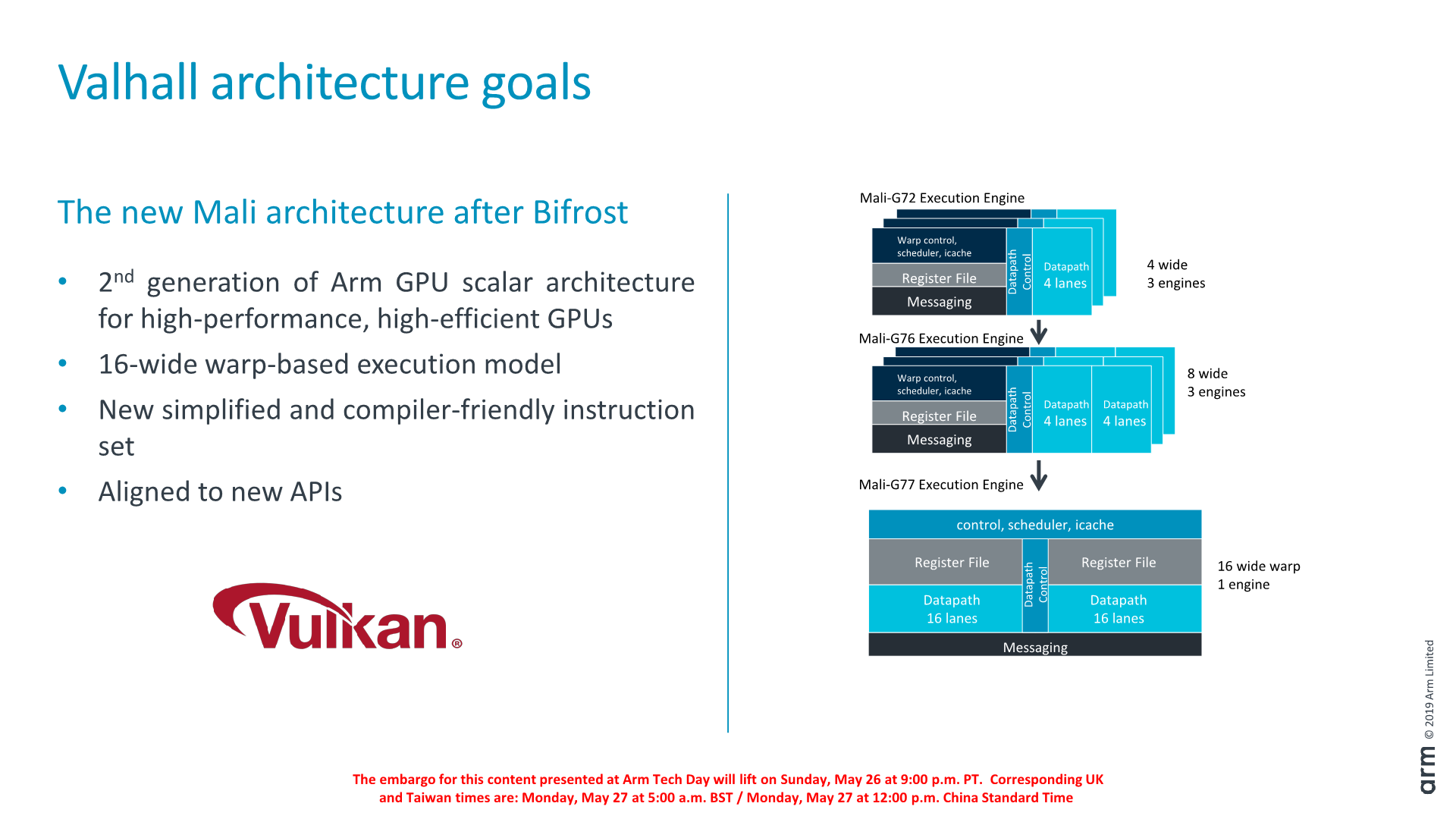
Bifrost’s in its initial iterations on the Mali-G71 and G72 the execution block in the core consisted of a 4-wide scalar SIMD units and with a warp/wavefront size of also 4. On the G76 last year this was increased to two 4-wide units with a warp size of 8. Initially during the design of Bifrost, Arm’s rationale for going with such narrow units and warp sizes was to reduce the amount of idle cycles on the ALUs. Workloads back then weren’t able to efficiently fill enough threads to justify for going for larger warp design. The benefit here is that in theory Arm would have achieved better ALU utilisation at a cost of more control logic.
As new generation workloads over the years have evolved though, this approach suddenly didn’t make much sense anymore. Today’s games are quickly advancing towards more compute complexity, and in particular in the last year or two we’ve seen games ported to mobile that originated on the PC.
With shader compute complexity going up, it is much easier to issue more threads and justify for going to a wider warp design. In this case, the new Valhall architecture supports a 16-wide warp-based execution model. It’s still not quite as wide as Nvidia’s 32-wide or AMD’s 64-wide designs, but it’s a big leap considering that before last year Mali GPUs were working with a 4-wide warp execution model.
Arm has also changed the ISA itself and simplified a lot of the instructions. While we don’t have more details, the new ISA is said to be more compiler friendly and adapted and designed to be better aligned with modern APIs such as Vulkan.
Previous Bifrost GPUs and even Midgard GPUs before that we saw a single GPU core employ multiple execution engines. These 3 engines would have their own dedicated datapath control logic, their own scheduler and instruction caches and register file and messaging blocks, which naturally creates quite a lot of overhead transistors. Particularly on the high-end this didn’t make sense anymore as we hadn’t seen the GPU IP vary the number of execution engines since the T860/880 series 4+ years ago.
The new G77 consolidates the previous generations “small” execution engines into a single larger IP block with shared control logic. There’s still some duplication in the IP design of the new engine: the actual ALU pipelines are organised into two “clusters”, each with their own 16-wide FMA units as well as accompanying execution units.
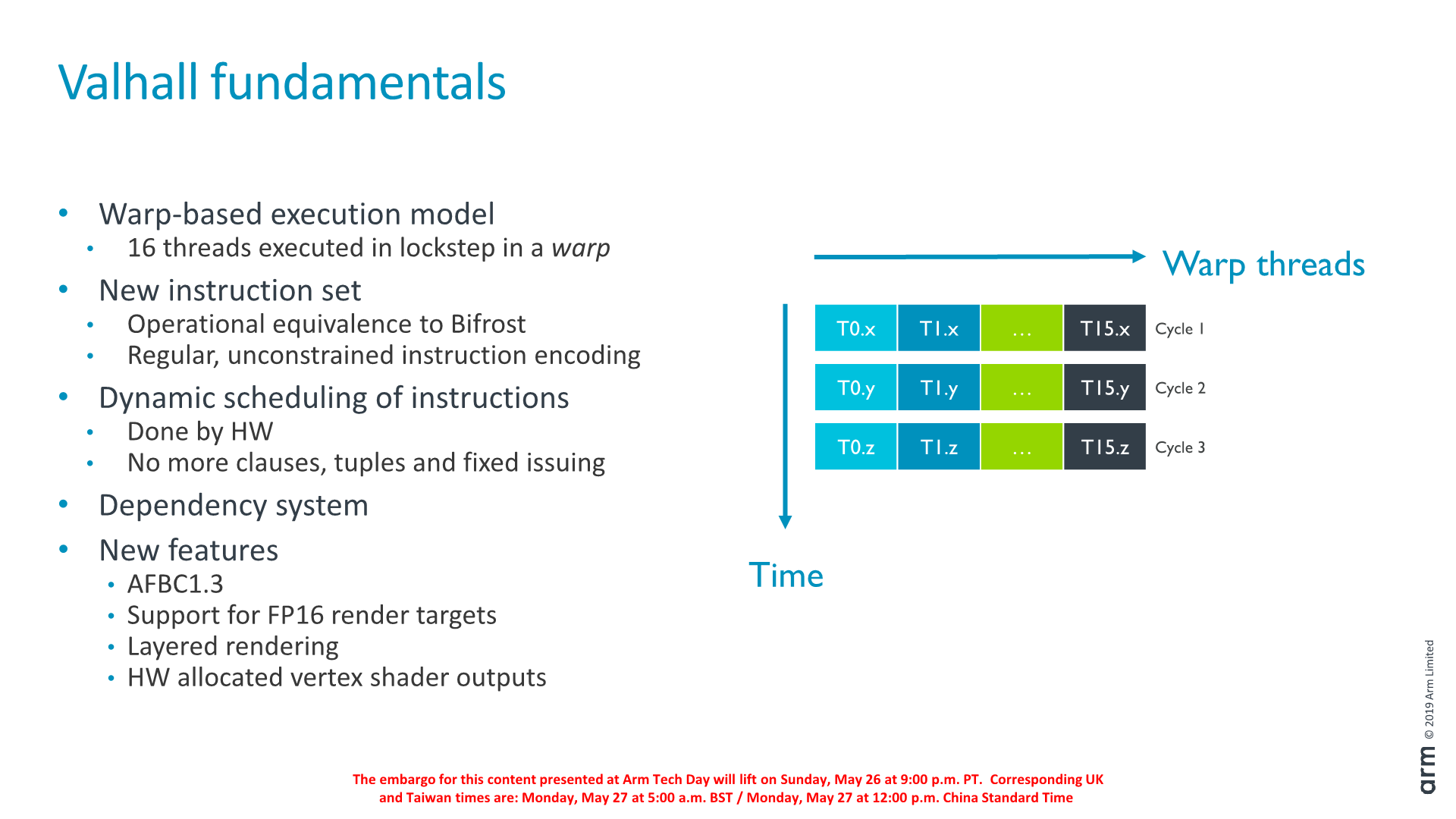
Part of the new ISA is a new encoding which is more regular in comparison to what we saw in Bifrost. An important new feature of the Valhall architecture is that the new ISA gets rid of fixed issue scheduling, clauses and tuples. In Bifrost, Arm delegated scheduling of instructions to the compiler, grouping them in so called clauses. This worked in practice, although it put a lot of work onto the compiler to get the best results in attempting to hide latency between instructions and data accesses.
In Valhall, the scheduling is completely done by hardware, which is essentially more akin to how an out-of-order CPU works. This new design also means that the actual ISA is more disconnected from the implemented microarchitecture, a more forward-thinking design choice.
The new ISA also put a focus on optimising texturing instructions, which is linked to the new architecture’s much increased texturing capability.
Other changes include incremental updates to existing technologies and evolution of the data structures, which includes optimisations to the geometry flow and optimisations to AFBC (Arm frame-buffer compression).
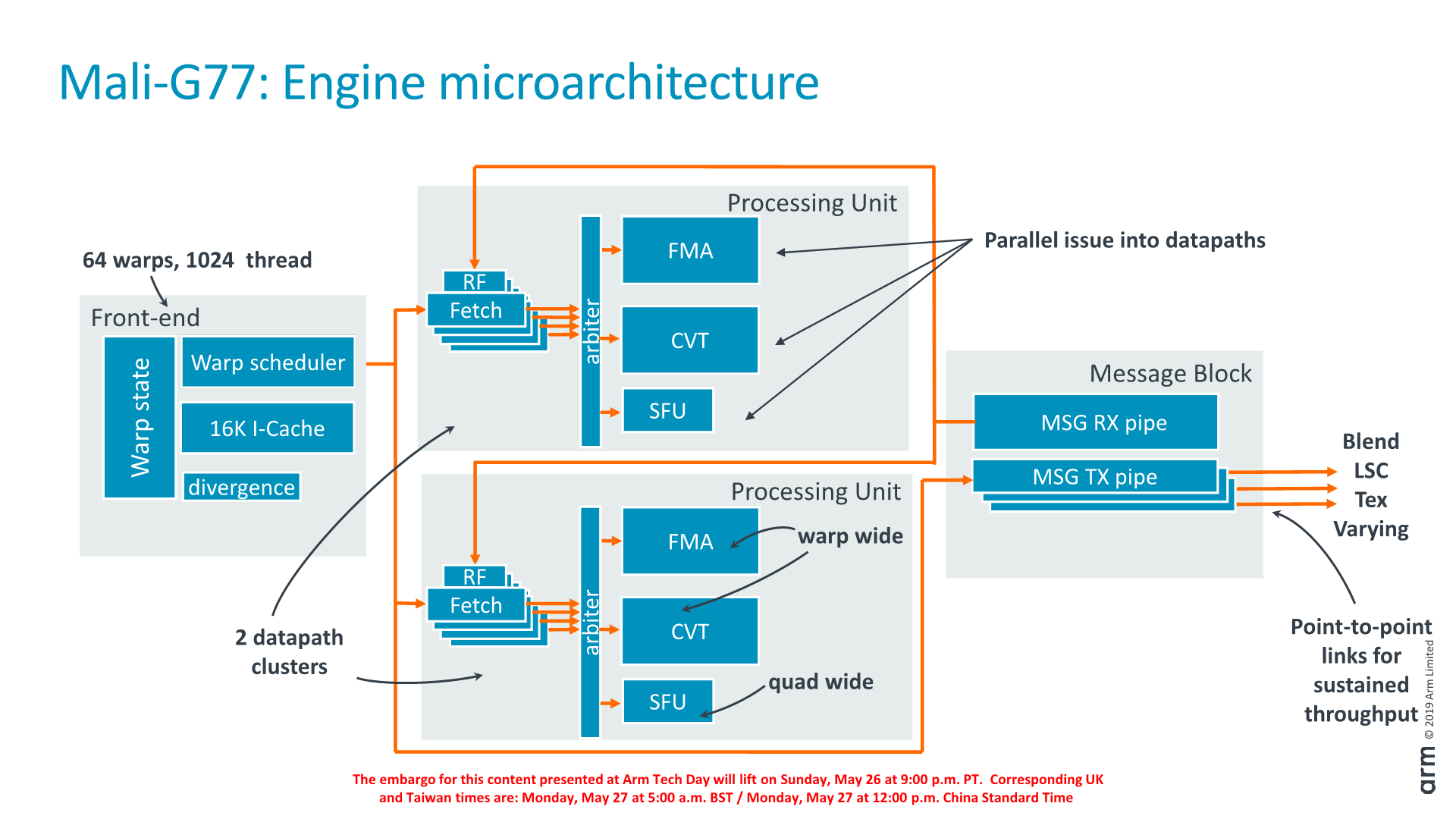
Delving deeper into the structure of the execution engine, we see that the structure can generally be grouped into four blocks: the front-end which includes the warp scheduler and I-cache, two identical datapath clusters (processing units), and the message block which connects to the load/store unit as well as the fixed-function blocks.
The front-end supports up to 64 warps or 1024 threads. The processing units each have three ALUs: the FMA and CVT (convert) units are 16-wide as the warp while the SFU (Special function unit) is 4-wide.
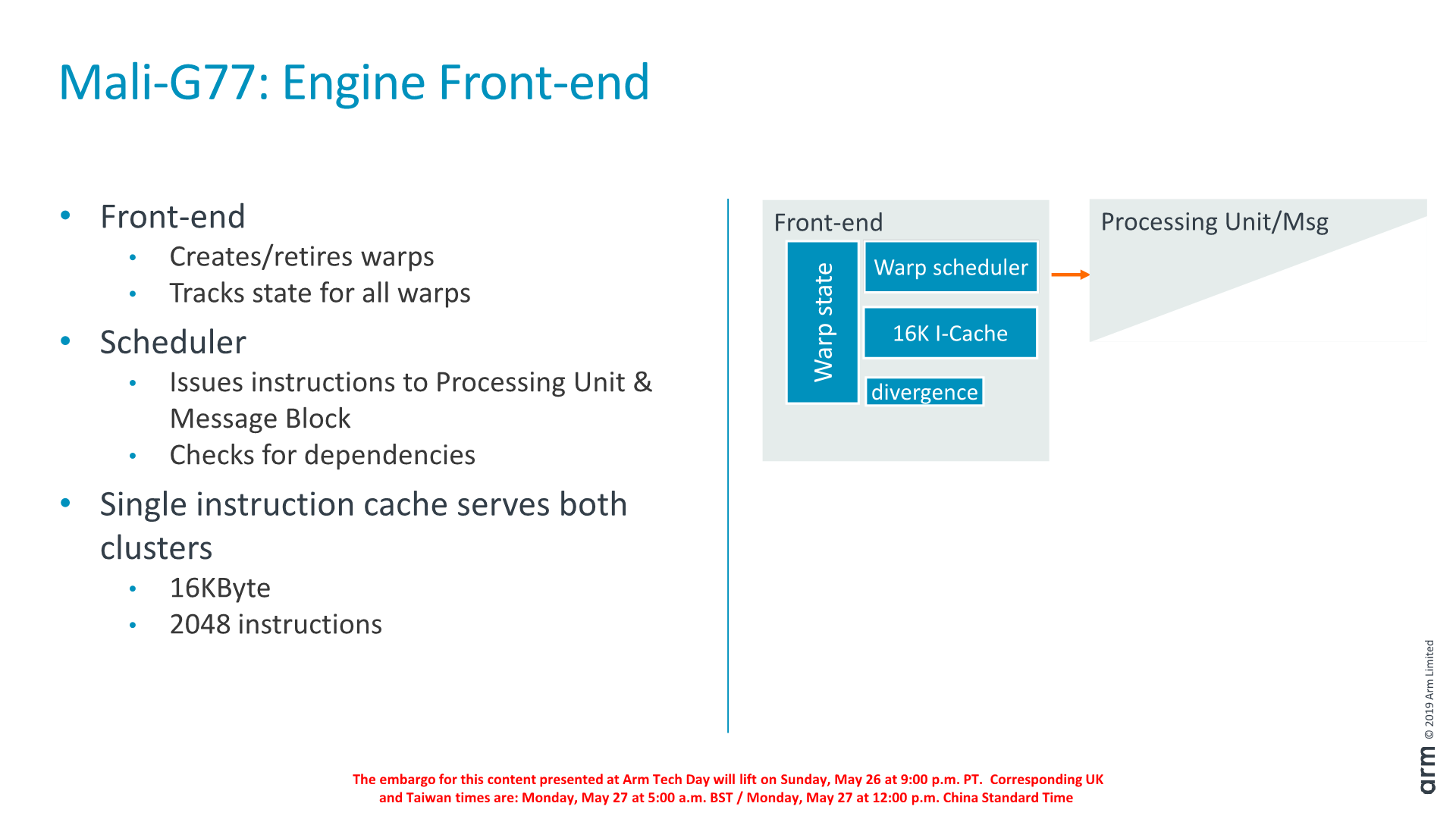
The front-end creates and retires warps and maintains the necessary state. Within the front-end there’s a dynamic scheduler which decides which instructions from each warp to execute. Warps that are waiting on a dependency are replaced with ones that are ready to execute.
The I-cache is shared among the processing and is 16KB (2048 instructions) 4-way set-associative and is able to issue 4 instructions per cycle in terms of bandwidth.
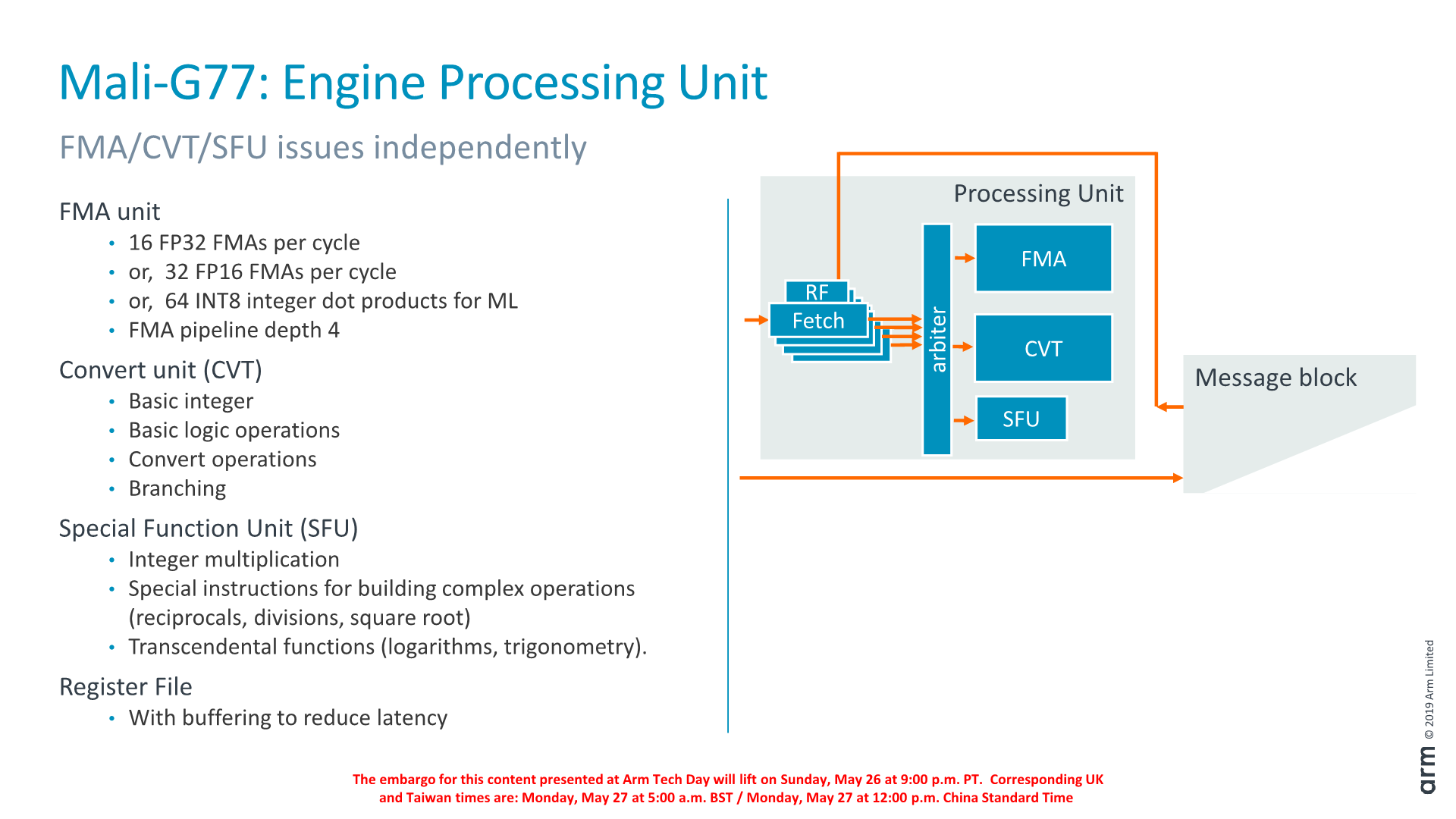
Within the actual processing units (clusters) we have four fetch units that are issuing into the arithmetic units. Each of the fetch units has a tightly coupled register file, as well as a forwarding buffer that reduces latency to access the register file.
The FMA ALU supports 16 FP32 FMA per cycle, double that for FP16 and again double that for INT8 dot-products. The convert unit handles basic integer operations and naturally type conversion operations, as well as serves as the branch port.
The SFU is 4-wide as opposed to 16-wide because it handles less frequently used instructions that don’t need quite as large throughput.

Overall in a higher-level comparison between the execution engines of the Mali-G77 versus the Mali-G76, we’re seeing one single engine versus three engines. One single engine has more instances on the primary datapath, and less instances of the control and I-cache, improving the area efficiency of the overall block.
An important change in the latency of the ALUs is that the datapath is now 4-cycles deep as opposed to 8-cycles previously which improves performance whenever one doesn’t chain operations.
Again, the new core has a superscalar-like issuing as opposed to the barrel pipeline design of the past where the pipeline had to make due with the aforementioned latency compromises. This change is also part of why the new compiler is much simplified as it no longer has to find matching instructions to issue simultaneously, as previously on the old pipeline design.








42 Comments
View All Comments
benazer - Monday, June 10, 2019 - link
Best Blogs writer good informative website.<a href="https://tasty-dinner-recipes.com/the-easy-black-fo... Dinner Recipes</a>
benazer - Monday, June 10, 2019 - link
informative website.