Arm's New Cortex-A77 CPU Micro-architecture: Evolving Performance
by Andrei Frumusanu on May 27, 2019 12:01 AM ESTPerformance Targets: 20-35% Better IPC
The Cortex-A77 saw some interesting microarchitectural changes that promise to increase performance. The question now remains where exactly the targeted performance gains will end up at?
In terms of published performance improvements, Arm opted to stay with SPEC2006, 2017, GeekBench4 and LMBench memory bandwidth. Our focus here will be on SPEC2006 as it’s still the most relevant benchmark among the set for mobile.
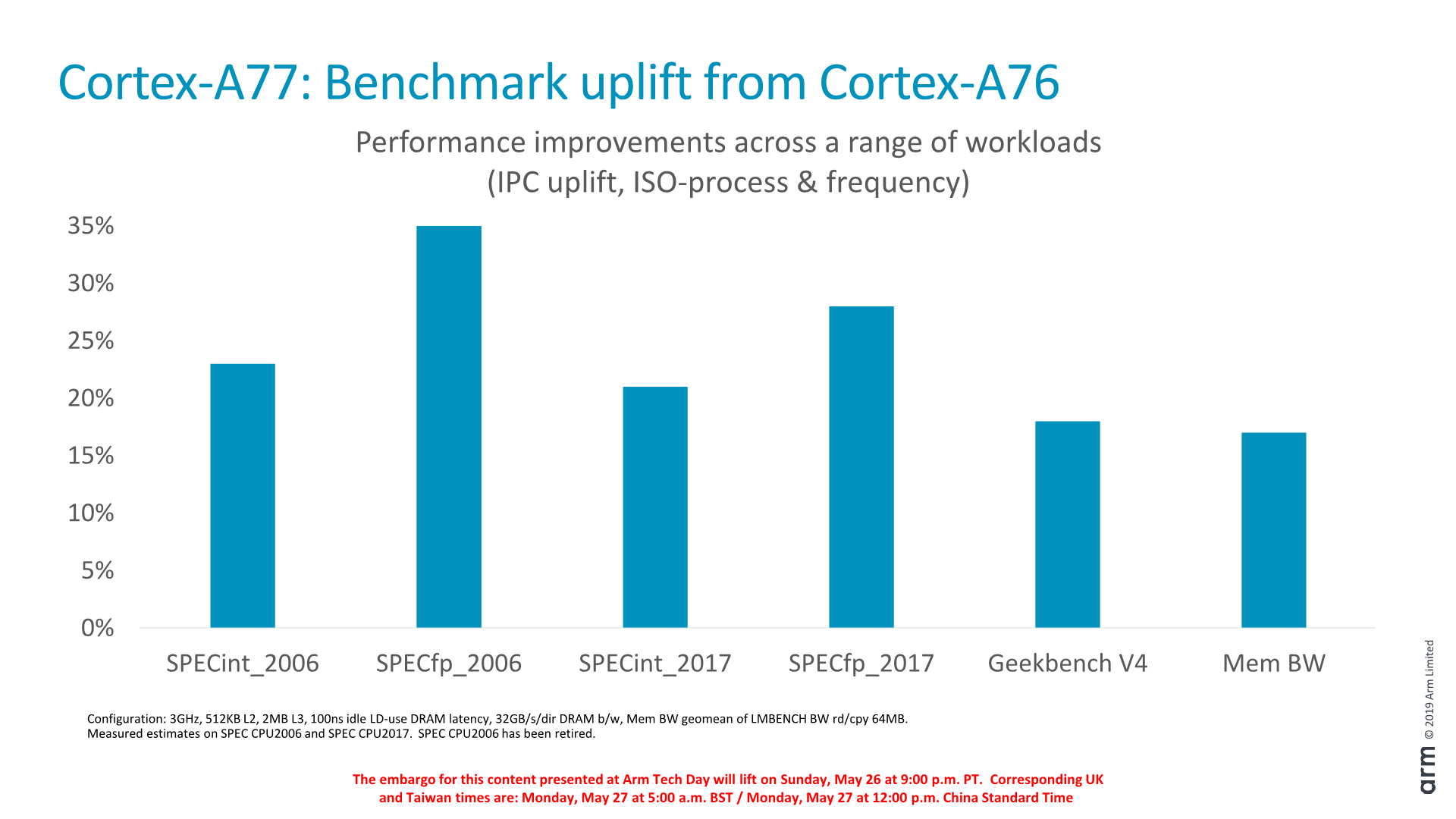
On SPECint2006, the A77 promises around a 23% IPC increase, while SPECfp2006 claims a more staggering 35% boost. The 23% increase for integer workloads was more or less in line with what we expected of the CPU core, however the 30-35% increase for FP workloads I must admit came as quite a surprise, particularly since we haven’t seen any significant changes on the FP execution units of the core. An explanation here would be that SPEC’s FP test suite is more memory intensive than the integer suite, and the Cortex-A77’s various microarchitectural improvements would be more visible in these workloads.
Last year I had made performance and efficiency projections for the A76 at two frequency points, and I ended up being quite close to where the Kirin 980 and Snapdragon 855 ended up landing. For the Cortex-A77, things should be a lot more straightforward to project as we won’t see major process node changes in the next generation 7nm SoCs.
Baselining on the current results of the Kirin 980, I simply extrapolated performance based on the published IPC increases for a theoretical 2.6GHz Cortex-A77 SoC. It’s to be noted that although Arm this year again talks about 3GHz target frequencies for the A77, I’m not expecting vendors to quite reach this frequency in upcoming SoCs, thus the 2.6GHz projection.
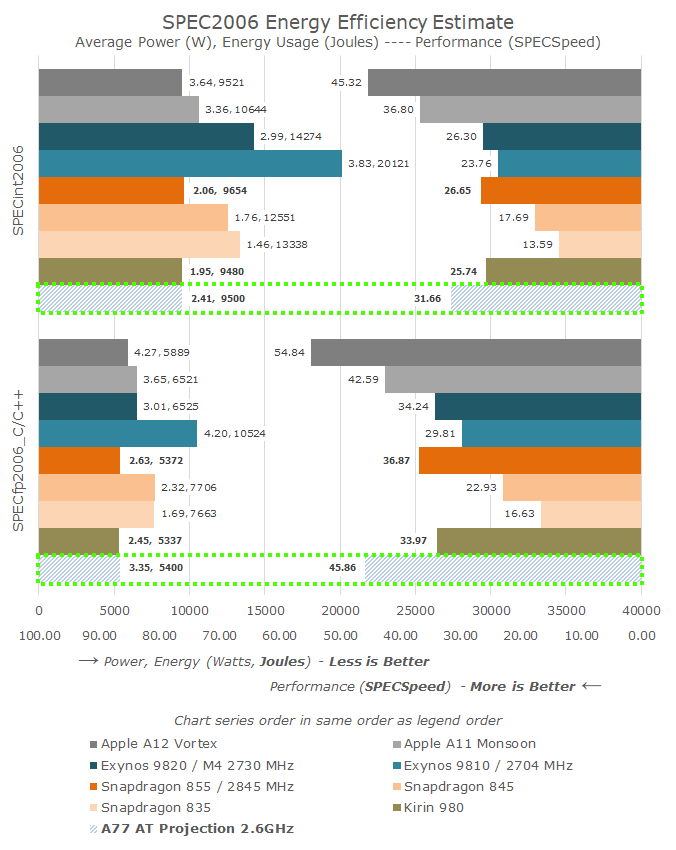
In terms of performance, the integer suite would see some solid improvement, however the floating-point results are a lot more interesting. If correct, the A77 would exceed the FP performance of Apple’s A11 and make for quite a big generational push even though we’re not expecting big process node improvements. It’s to be noted though that the A77 will have to compete with Apple’s A13 later this year as well as next-gen M5 cores from Samsung.
Arm promises energy efficiency of the A77 will remain the same as current-gen A76 SoCs. Thus at peak performance, both CPU cores would use the same amount of energy to complete a set workload. The increased performance of the A77 would however have one drawback: Increased power usage, linear with the increased performance figures. This latter increased power usage would seemingly reach levels where running more than two cores at peak frequency would be more problematic in a mobile SoC. Luckily, most vendors have moved on from 4 full-speed big cores to 2+2 or 3+1 designs where there’s only one or two high-power big cores.
It’s to be noted although we’re talking about big cores here, the A77 is said to be only 17% bigger than the A76 – still significantly smaller than the next best microarchitecture from the competition.
End Remarks
Overall the Cortex-A77 announcement today isn’t quite as big of a change as what we saw last year with the A76, nor is it as big a change as today’s new announcement of Arm’s new Valhall GPU architecture and G77 GPU IP.
However what Arm managed to achieve with the A77 is a continued execution of their roadmap, which is extremely important in the competitive landscape. The A76 delivered on all of Arm’s promises and ended up being an extremely performant core, all while remaining astonishingly efficient as well as having a clear density lead over the competition. In this regard, Arm’s major clients are still heavily focusing on having the best PPA in their products, and Arm delivers in this regard.
The one big surprise about the A77 is that its floating point performance boost of 30-35% is quite a lot higher than I had expected of the core, and in the mobile space, web-browsing is the killer-app that happens to be floating point heavy, so I’m looking forward how future SoCs with the A77 will be able to perform.
But even in the integer workloads a 20-25% IPC gain is absolutely marvellous improvement, and we do trust Arm to be able to maintain energy efficiency of the A76. Power will go up slightly, but I think the industry has shown that mobile devices today handle at least two higher power cores properly, so future SoCs should continue with big+middle+little CPU configurations.
Coming A77 SoCs from vendors are expected to still be 7nm – Qualcomm and HiSilicon are the two obvious leading customers that would adopt the core and I’m expecting similar timeframes as last generation’s chipsets. For now- Arm’s delivering on their promised 20-25% yearly CAGR and we believe this to continue for the foreseeable next few generations.








108 Comments
View All Comments
Santoval - Monday, May 27, 2019 - link
Quite frankly, moving from a 4-wide to a 6-wide(!) design in the front end doesn't sound as an "evolutionary" design to me. That's an incredibly wide front end, wider even than when the A76 moved from 3-wide to 4-wide. I never expected ARM to go that wide, not so fast anyway. I wonder if the thermals will be affected, while the clocks should normally be lower.The addition of a macro-op L0 cache and the reworking of the backend are also quite significant.
frenchy_2001 - Monday, May 27, 2019 - link
I think Andrei referred to it as an evolution compared to the huge jump from A75 to A76.But you are right, each generation since A72 has been fairly different from the previous one.
The changes you pointed out also make more sense if you look at them for server/portable computers instead of phones.
Andrei Frumusanu - Tuesday, May 28, 2019 - link
Keep in mind that you can't just throw all those features in a core alone - the A76 was designed with A77 and Hercules in mind and in the pipeline.peevee - Tuesday, May 28, 2019 - link
"I wonder if the thermals will be affected, while the clocks should normally be lower."L0 MOP-cache eliminates 85% of the work here, so the new wide decoders will mostly sit idle, but quickly filling in the queue when a branch jumps out of L0 window.
Main Sandy Bridge enhancement, finally. And makes total sense given that A8.2 became just about as huge as Sandy Bridge with its AVX1, necessitating huge power-hungry decoders. RISC my a$$...
Wardrive86 - Monday, May 27, 2019 - link
Has Arm ever stated why they went back to an Architectural register file after using a physical register file for the A73 and A75? Its interesting that they get the performance they do with such a small one... relatively speakingWardrive86 - Monday, May 27, 2019 - link
Not to double post but I wonder if it is just differing design philosophies between the Austin and Sophia teams.Andrei Frumusanu - Tuesday, May 28, 2019 - link
Yes, it's an implementation/electrical engineering question between both teams.blu42 - Tuesday, May 28, 2019 - link
Perhaps it could be more due to different design philosophies between Austin and Sophia design centres?jcc5169 - Monday, May 27, 2019 - link
It's so funny to me that Anandtech now goes out of its way to talk about everyone but AMDRyan Smith - Tuesday, May 28, 2019 - link
Beg your pardon?https://www.anandtech.com/show/14407/amd-ryzen-300...
https://www.anandtech.com/show/14412/amd-teases-fi...
And that's just in the last 36 hours.