Arm's New Cortex-A77 CPU Micro-architecture: Evolving Performance
by Andrei Frumusanu on May 27, 2019 12:01 AM ESTThe Cortex-A77 µarch: Added ALUs & Better Load/Stores
Having covered the front-end and middle-core, we move onto the back-end of the Cortex-A77 and investigate what kind of changes Arm has made to the execution units and data pipelines.
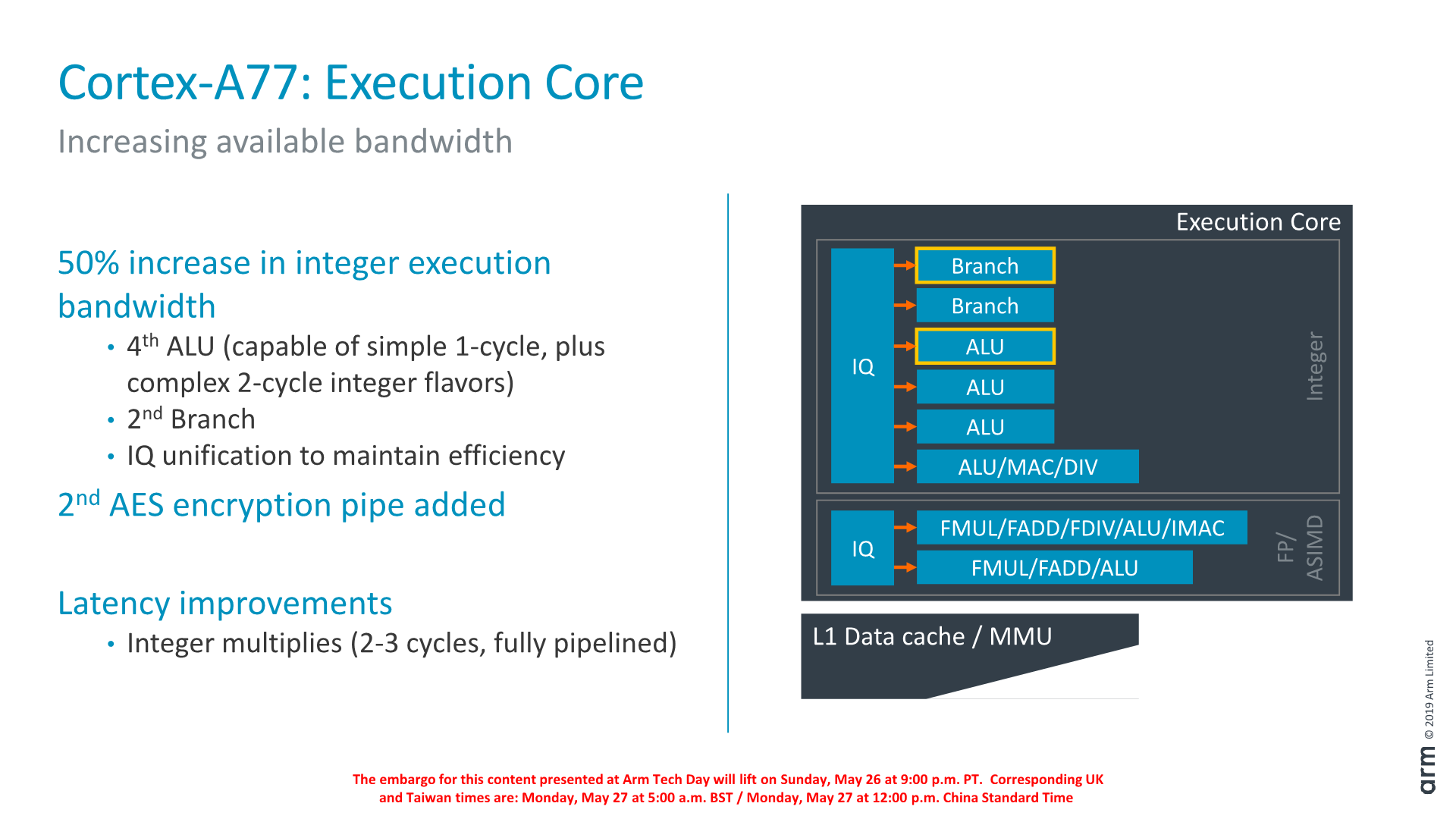
On the integer execution side of the core we’ve seen the addition of a second branch port, which goes along with the doubling of the branch-predictor bandwidth of the front-end.
We also see the addition on an additional integer ALU. This new unit goes half-way between a simple single-cycle ALU and the existing complex ALU pipeline: It naturally still has the ability of single-cycle ALU operations but also is able to support the more complex 2-cycle operations (Some shift combination instructions, logical instructions, move instructions, test/compare instructions). Arm says that the addition of this new pipeline saw a surprising amount of performance uplift: As the core gets wider, the back-end can become a bottleneck and this was a case of the execution units needing to grow along with the rest of the core.
A larger change in the execution core was the unification of the issue queues. Arm explains that this was done in order to maintain efficiency of the core with the added execution ports.
Finally, existing execution pipelines haven’t seen much changes. One latency improvement was the pipelining of the integer multiply unit on the complex ALU which allows it to achieve 2-3 cycle multiplications as opposed to 4.
Oddly enough, Arm didn’t make much mention of the floating-point / ASIMD pipelines for the Cortex-A77. Here it seems the A76’s “state-of-the-art” design was good enough for them to focus the efforts elsewhere on the core for this generation.

On the part of the load/store units, we still find two units, however Arm has added two additional dedicated store ports to the units, which in effect doubles the issue bandwidth. In effect this means the L/S units are 4-wide with 2 address generation µOps and 2 store data µOps.
The issue queues themselves again have been unified and Arm has increased the capacity by 25% in order to expose more memory-level parallelism.

Data prefetching is incredibly important in order to hide memory latency of a system: Shaving off cycles by avoiding to having to wait for data can be a big performance boost. I tried to cover the Cortex-A76’s new prefetchers and contrast it against other CPUs in the industry in our review of the Galaxy S10. What stood out for Arm is that the A76’s new prefetchers were outstandingly performant and were able to deal with some very complex patterns. In fact the A76 did far better than any other tested microarchitecture, which is quite a feat.
For the A77, Arm improved the prefetchers and added in even new additional prefetching engines to improve this even further. Arm is quite tight-lipped about the details here, but we’re promised increased pattern coverages and better prefetching accuracy. One such change is claimed to be “increased maximum distance”, which means the prefetchers will recognize repeated access patterns over larger virtual memory distances.
One new functional addition in the A77 is so called “system-aware prefetching”. Here Arm is trying to solve the issue of having to use a single IP in loads of different systems; some systems might have better or worse memory characteristics such as latency than others. In order to deal with this variance between memory subsystems, the new prefetchers will change the behaviour and aggressiveness based on how the current system is behaving.
A thought of mine would be that this could signify some interesting performance improvements under some DVFS conditions – where the prefetchers will alter their behaviour based on the current memory frequency.
Another aspect of this new system-awareness is more knowledge of the cache pressure of the DSU’s L3 cache. In case that other CPU cores would be highly active, the core’s prefetchers would see this and scale down its aggressiveness in order to possibly avoid thrashing the shared cache needlessly, increasing overall system performance.








108 Comments
View All Comments
Lodix - Monday, May 27, 2019 - link
Andrei, are you still expecting HiSilicon to launch a Kirin SOC using ARM IP later this year with all that is happening ? It is very sad the current situation.Andrei Frumusanu - Monday, May 27, 2019 - link
The SoC certainly is ready to go to manufacturing. What happens with devices is another question.Violet Giraffe - Tuesday, May 28, 2019 - link
You find it said that a certain company finally has to pay for its practice of stealing and selling IP they do not own? I don't.a94 - Wednesday, May 29, 2019 - link
You know that Huawei always pay the royalty for licensing ARM IP to make their Kirin right? If not, how did they announce that a version of Kirin was based on Cortex something without ARM suing them? Maybe, Huawei did steal some IP from another company, but to be banned of access to a product they always pay(ARM) is ridiculouscolinisation - Monday, May 27, 2019 - link
Hi Andrei,Can you comment at all on the possibility of an A55 refresh? I realise A55 recently replaced A53, but I wonder where ARM go from here. It seemed with the Neoverse E1/A65 out there, we would see a relatively quick replacement. In your opinion is this on the cards or does the move to out of order execution mean too high a power penalty currently with that design.
Thanks
Santoval - Monday, May 27, 2019 - link
On average a new "small" ARM core is launched with every third "big" ARM core. A55 was not launched very recently, it launched along with the A75 core in 2017. Since the A77 cores are also intended to be paired with the A55 cores, the successor of A55 should be launched along with the A78 core -assuming it is called that way- which currently has the codename Hercules.Andrei Frumusanu - Tuesday, May 28, 2019 - link
The A65 won't be seen in mobile because SMT doesn't make sense in mobile, it's not energy efficient.We should expect a new small core along with the next major refresh from the Sophia team after A78/Hercules in 2 years.
name99 - Tuesday, May 28, 2019 - link
The slow cadence for small cores is REALLY delaying the pickup of ARM extensions. How long till ARM proper is shipping PAE and the SPECTRE-instructions in 8.5?They’ve got to see that this is no longer a sensible strategy!
peevee - Tuesday, May 28, 2019 - link
Given that even A76 has about the same perf/W as A55, do A55s even make any sense now?And SMT is a much cheaper way to take advantage of large back-end than a very complex OoO we have now.
Meteor2 - Monday, June 3, 2019 - link
Maybe at the top-end, but does A76 match A55 at lower power levels? Which is what A55 is optimised for?