The Samsung Galaxy S10+ Snapdragon & Exynos Review: Almost Perfect, Yet So Flawed
by Andrei Frumusanu on March 29, 2019 9:00 AM ESTInference Performance: APIs, Where Art Thou?
Having covered the new CPU complexes of both new Exynos and Snapdragon SoCs, up next is the new generation neural processing engines in each chip.
The Snapdragon 855 brings big performance improvements to the table thanks to a doubling of the HVX units inside the Hexagon 690 DSP. The HVX units in the last two generations of Snapdragon chips were the IP blocks who took the brunt of new integer neural network inferencing work, an area the IP is specifically adept at.
The new tensor accelerator inside of the Hexagon 690 was shown off by Qualcomm at the preview event back in January. Unfortunately one of the issues with the new block is that currently it’s only accessible through Qualcomm’s own SDK tools, and currently doesn’t offer acceleration for NNAPI workloads until later in the year with Android Q.
Looking at a compatibility matrix between what kind of different workloads are able to be accelerated by various hardware block in NNAPI reveals are quite sad state of things:
| NNAPI SoC Block Usage Estimates | |||
| SoC \ Model Type | INT8 | FP16 | FP32 |
| Exynos 9820 | GPU | GPU | GPU |
| Exynos 9810 | GPU? | GPU | CPU |
| Snapdragon 855 | DSP | GPU | GPU |
| Snapdragon 845 | DSP | GPU | GPU |
| Kirin 980 | GPU? | NPU | CPU |
What stands out in particular is Samsung’s new Exynos 9820 chipset. Even though the SoC promises to come with an NPU that on paper is extremely powerful, the software side of things make it as if the block wouldn’t exist. Currently Samsung doesn’t publicly offer even a proprietary SDK for the new NPU, much less NNAPI drivers. I’ve been told that Samsung looks to address this later in the year, but how exactly the Galaxy S10 will profit from new functionality in the future is quite unclear.
For Qualcomm, as the HVX units are integer only, this means only quantised INT8 inference models are able to be accelerated by the block, with FP16 and FP32 acceleration falling back what should be GPU acceleration. It’s to be noted my matrix here could be wrong as we’re dealing with abstraction layers and depending on the model features required the drivers could run models on different IP blocks.
Finally, HiSilicon’s Kirin 980 currently only offers NNAPI acceleration for FP16 models for the NPU, with INT8 and FP32 models falling back to the CPU as the device are seemingly not using Arm’s NNAPI drivers for the Mali GPU, or at least not taking advantage of INT8 acceleration ine the same way Samsung's GPU drivers.
Before we even get to the benchmark figures, it’s clear that the results will be a mess with various SoCs performing quite differently depending on the workload.
For the benchmark, we’re using a brand-new version of Andrey Ignatov’s AI-Benchmark, namely the just released version 3.0. The new version tunes the models as well as introducing a new Pro-Mode that most interestingly now is able to measure sustained throughput inference performance. This latter point is important as we can have very different performance figures between one-shot inferences and back-to-back inferences. In the former case, software and DVFS can vastly overshadow the actual performance capability of the hardware as in many cases we’re dealing with timings in the 10’s or 100’s of milliseconds.
Going forward we’ll be taking advantage of the new benchmark’s flexibility and posting both instantaneous single inference times as well sequential throughput inference times; better showcasing and separating the impact of software and hardware capabilities.
There’s a lot of data here, so for the sake of brevity I’ll simply put up all the results up and we’ll go over the general analysis at the end:
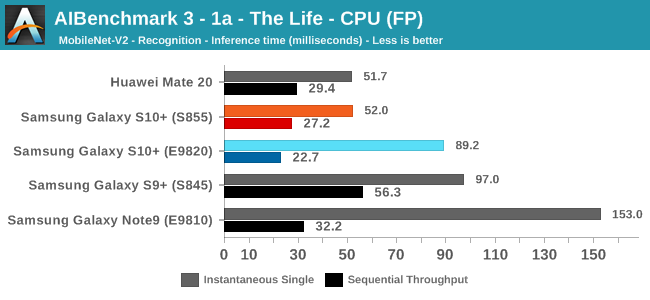
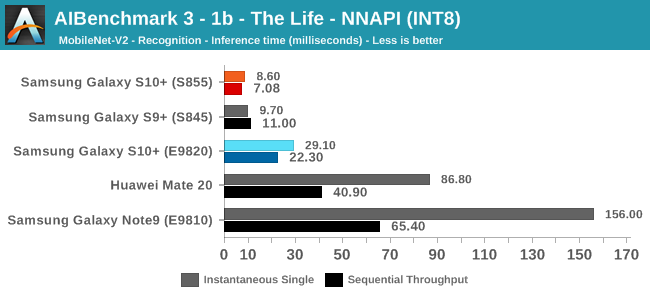
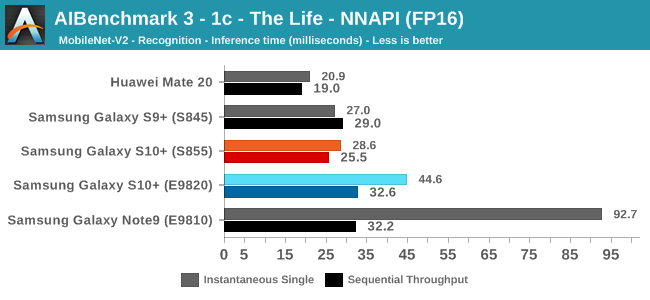
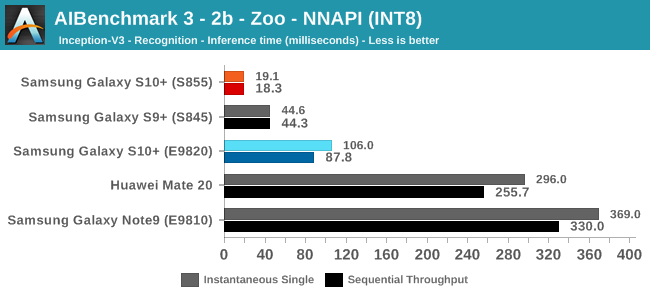
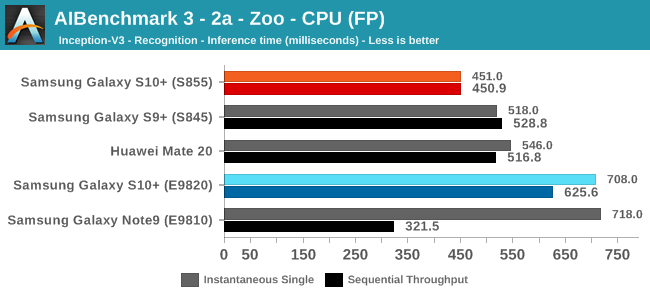
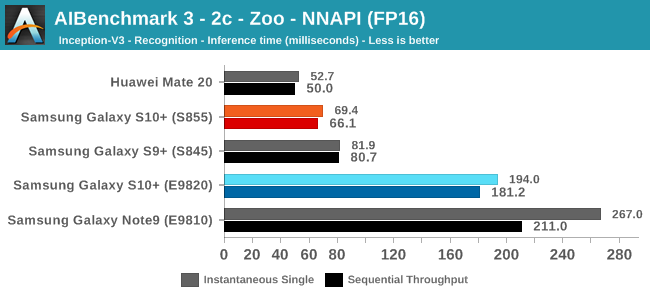
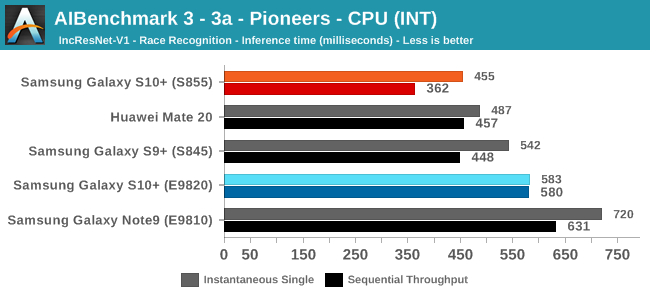
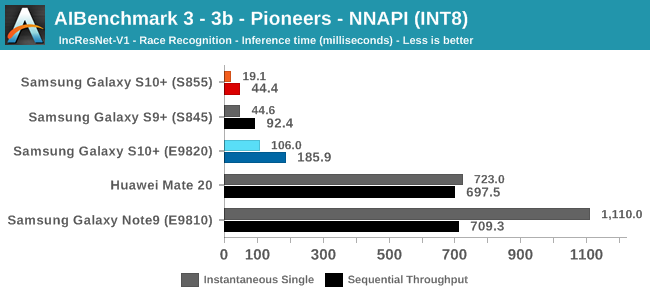
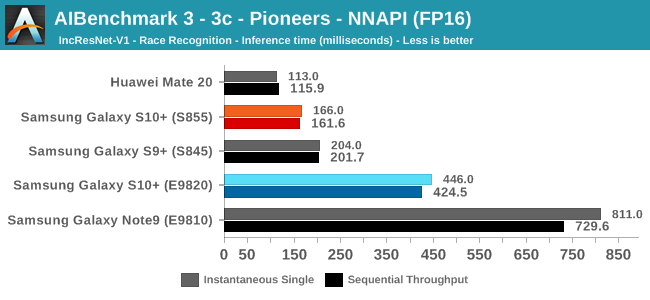
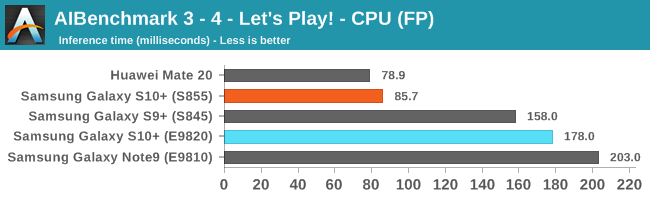
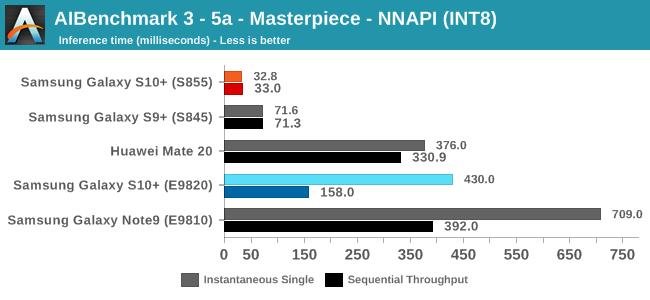
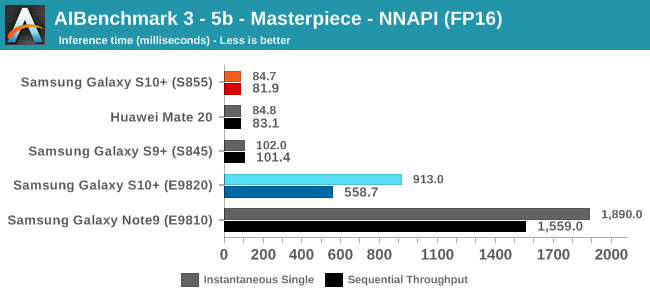
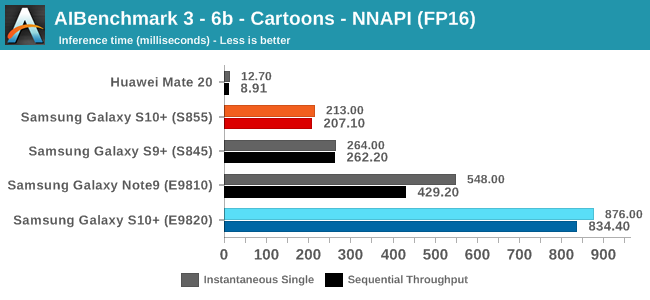
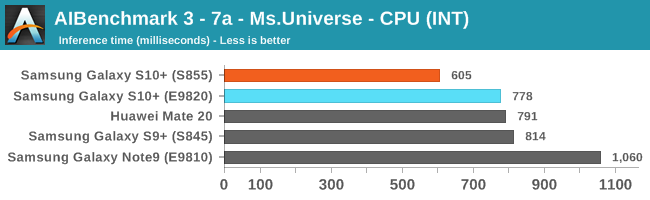
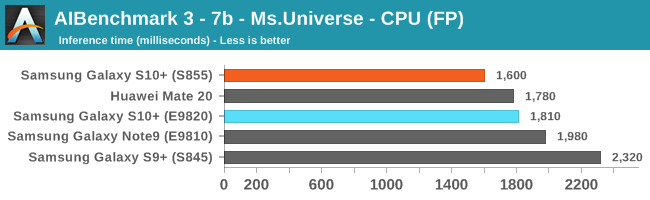
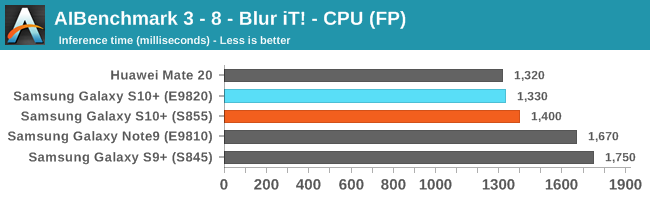
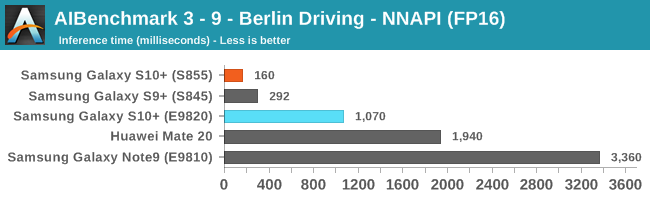
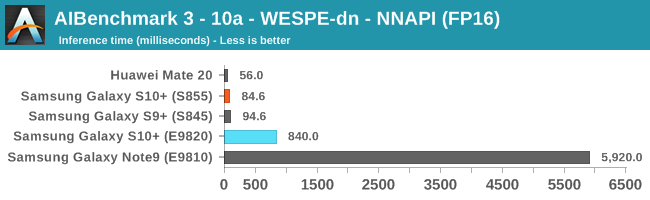
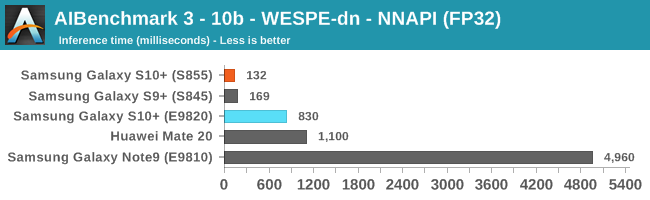
As initially predicted, the results are extremely spread across all the SoCs.
The new tests also include workloads that are solely using TensorFlow libraries on the CPU, so the results not only showcase NNAPI accelerator offloading but can also serve as a CPU benchmark.
In the CPU-only tests, we see the Snapdragon 855 and Exynos 9820 being in the lead, however there’s a notable difference between the two when it comes to their instantaneous vs sequential performance. The Snapdragon 855 is able to post significantly better single inference figures than the Exynos, although the latter catches up in longer duration workloads. Inherently this is a software characteristic difference between the two chips as although Samsung has improved scheduler responsiveness in the new chip, it still lags behind the Qualcomm variant.
In INT8 workloads there is no contest as Qualcomm is far ahead of the competition in NNAPI benchmarks simply due to the fact that they’re the only vendor being able to offload this to an actual accelerator. Samsung’s Exynos 9820 performance here actually has also drastically improved thanks to the new Mali G76’s new INT8 dot-product instructions. It’s odd that the same GPU in the Kirin 980 doesn’t show the same improvements, which could be due to not up-to-date Arm GPU NNAPI drives on the Mate 20.
The FP16 performance crown many times goes to the Kirin 980 NPU, but in some workloads it seems as if they fall back to the GPU, and in those cases Qualcomm’s GPU clearly has the lead.
Finally for FP32 workloads it’s again the Qualcomm GPU which takes an undisputed lead in performance.
Overall, machine inferencing performance today is an absolute mess. In all the chaos though Qualcomm seems to be the only SoC supplier that is able to deliver consistently good performance, and its software stack is clearly the best. Things will evolve over the coming months, and it will be interesting to see what Samsung will be able to achieve in regards to their custom SDK and NNAPI for the Exynos NPU, but much like Huawei’s Kirin NPU it’s all just marketing until we actually see the software deliver on the hardware capabilities, something which may take longer than the actual first year active lifespan of the new hardware.








229 Comments
View All Comments
xian333c - Wednesday, April 17, 2019 - link
How to buy that unicorn on table in ur shout?Brightontech - Sunday, April 21, 2019 - link
it is an awesome phone<a href="https://www.brightontech.net/2019/04/audiovideo-ed... Editor and Video Converter</a>
Video Editor and Video Converter
Jhereck - Tuesday, April 23, 2019 - link
Hi Andrei another question regarding the patch designed to increase PELT resonsiveness : is there any way a third party kernel can include it, therefore making s9 and s10 the devices they should be ?You know like last year when you tried to play with s9 exynos kernel in order to match snapdragon power and power efficency ?
Thanks in advance
Rixos - Thursday, May 2, 2019 - link
It's kind of sad, I was actualy looking at the s10e as a replacement device for my galaxy S7 but as I live in Europe I would be getting the Exynos variant. Worse audio quality, less processing power and worse camera results. Basically seeing this kind of ruined the purchase for me. In some sense I wish I would not have seen it, the S10e is likely still a great upgrade for my S7 but knowing that there is a better version out there just ruins it for me. I guess ignorance sometimes really is bliss.theblitz707 - Thursday, May 23, 2019 - link
I see this is in every review. I actually went to stores and used my phones ambient light sensor and an another phones flashlight to measure display brightnesses. Although slightly inaccurate lg g7 gave a 1050lux reading with boost on.(all test on apl100) Taking that as a base s9 plus did 1020 s10 plus did 1123 and p20 pro did around 900 when i shone my flashlight to each sensor. So why everyone makes it seem like they are less bright than they actually are? Does using a flashlight to trigger high brightness impossible to imagine? Let me tell you those oled screens get very bright with high ambient light like outside on a sunny day.ballsystemlord - Monday, June 3, 2019 - link
Spelling and grammar corrections. I did not read the whole thing, so there maybe more.Samsung new L3 cache consists of two different structures
Possesive:
Samsung's new L3 cache consists of two different structures
Similarly, the A75's should be a ton more efficient the A55 cores at the upper performance points of the A55's.
Missing "than":
Similarly, the A75's should be a ton more efficient than the A55 cores at the upper performance points of the A55's.
Arm states that the new Cortex A76 has new state-of-the-art prefetchers and looking at what the CPU is able to do one my patterns I'd very much agree with this claim.
Missing "to":
Arm states that the new Cortex A76 has new state-of-the-art prefetchers and looking at what the CPU is able to do to one my patterns I'd very much agree with this claim.
The nature of region-based prefetchers means that fundamentally any patterns which has some sort of higher-level repeatability will get caught and predicted, which unfortunately means designing a structured test other than a full random pattern is a bit complicated to achieve.
"have" not "has" and a missing y:
The nature of region-based prefetchers means that fundamentally any patterns which have some sort of higher-level repeatability will get caught and predicted, which unfortunately means designing a structured test other than a fully random pattern is a bit complicated to achieve.
Switching over from linear graphs to logarithmic graphs this makes transitions in the cache hierarchies easier to analyse.
Excess "this" and analyze is with a "z":
Switching over from linear graphs to logarithmic graphs makes transitions in the cache hierarchies easier to analyze.
Indeed one of the bigger microarchitectural changes of the core was the addition of a second data store unit.
Missing comma:
Indeed, one of the bigger microarchitectural changes of the core was the addition of a second data store unit.
...we see that in the L3 memory region store curve is actually offset by 1MB compared to the flip/load curves, which ending only after 3MB.
"ed" not "ing":
...we see that in the L3 memory region store curve is actually offset by 1MB compared to the flip/load curves, which ended only after 3MB.
"Traditionally such misses are tracked by miss status holding registers (MSHRs), however I haven't seen Arm CPUs actually use this nomenclature."
This is almost certainly a run on sentence with missing punctuation. Try:
"Traditionally, such misses are tracked by miss status holding registers (MSHRs). However, I haven't seen Arm CPUs actually use this nomenclature."
"Again to have a wider range of performance comparison across ARMv8 cores in mobile here's a grand overview of the most relevant SoCs we've tested:"
Missing comma:
"Again, to have a wider range of performance comparison across ARMv8 cores in mobile here's a grand overview of the most relevant SoCs we've tested:"
giallo - Monday, June 17, 2019 - link
how much did they pay you to write this bullshit? you must be true downstheblitz707 - Monday, August 19, 2019 - link
i discovered something about display brightness on oleds recently. I did a test with a7 with auto brightness on.Lets assume, on a slightly dark room you set your brightness to 25nits(whites), so when you go out to the sun phone boosts around 750-800 nits.
Now lets assume on a slightly dark room you set your brightness to 250 nits, now when you go out to the sun phone boosts to 900nits. (what i actually did was not go in a dark room but while i was outside i covered the sensor with my hand so it thought i was in a dim place)
I used to assume everytime you go out to sun it would get maxed but apparently it still depends on what you set your phone before.(dumb a bit if you ask me, cuz you know, its THE sun, brightest thing..) I believe this might be the reason why you didnt reach to 100APL 1200nits.
P.s. I know every brightness sensor is different but i had tested lg on full white and i had gotten 1050 lux, i also tested s10 or plus, all white and i had gotten 1120lux on white,100APL.(It was painfully hard to find the sensor to shine the flashlight, its somewhere around upper part of the phone under the display).
It would be cool if you retested the brightness in this way:
1- After you put auto brightness on, Go in a very dark room or cover the sensor, so phone put itself to a dark brightness, after that happens, set the brigthness to max while you are still in the dark room.(auto is still on).
2- Now go under sun or shine a phone flashlight to sensor and test the brightness on white APL100. That would be really nice.
theblitz707 - Monday, August 19, 2019 - link
lg is g7 on boosted, forgot to mention