The Samsung Galaxy S10+ Snapdragon & Exynos Review: Almost Perfect, Yet So Flawed
by Andrei Frumusanu on March 29, 2019 9:00 AM ESTMemory Subsystems Compared - Latency
Memory is an integral part of a CPU’s performance. We all know that fundamentally memory performance can be summarised into two metrics: The delay it takes to actually access a certain piece of memory, meaning the memory latency, and how much of this memory you can transfer in a given amount of time, meaning the memory throughput, or memory bandwidth. Traditionally, things have been relatively straightforward in terms quantising these metrics, in recent years however, and in particular with this new generation of CPUs, we see things get quite complicated as components such as a CPU’s memory prefetchers can blur the lines between what the physical capabilities of the hardware are and what is actually happening in the real-world.
To better investigate these topics over the last few weeks I’ve invested a bit of time into rewriting our memory test tools from scratch and to attempt to better divulge characteristics of today’s modern CPUs. Unfortunately nowadays publishing a single figure for memory latency isn’t sufficient to properly characterise the memory performance of a platform, and in particular it might not be a valid comparison figure when comparing things between different platforms.
In terms of memory latency tests, the main tools at use are still a variety of pointer-chasing patterns, designed to target different parts of the microarchitectures and bring to light hardware characteristics. In the following page, I can summarize the followings data-points and what they do:
- TLB Trash: This is a simple pattern designed to randomly touch a single cache line per memory page. The goal here is to determine the TLB miss penalty at different TLB levels, and it also exposes the page capacity for each TLB level. Because we’re only touching a single cache line, the actual cache pressure is at an absolute minimum which means for the majority of platforms the actual used memory should fit into L2 caches.
- Full Random: This is a worst case scenario in terms of memory latency. We’re traversing a fully random chain of cache lines throughout the full buffer region. The latency exposed here not only will contain the hardware access latencies, but if the buffer size exceeds the TLB capacity, it will also contain a great amount of TLB miss penalties.
- R per R page: Randomly traverse a random page in the buffer. We also fully randomly access the cache lines within a page, making sure we touch all cache lines before we move on to the next random page.
- R Disjointed, R Spread: Variations of the previous test, but with some permutations in order to attempt to fool some prefetchers.
- R in Range nP/n*pagesizeKB: The memory buffer is dissected into regions of a given size and the regions are randomly traversed. Same principle as R in R page, however at different region sizes.
- R in RV prange: Same as previous, however with non-constant page regions varying from 1 to 32 times page size.
In general, the patterns that matter the most are the TLB Trash, Full Random and for some chipsets the R Disjointed pattern. The latter I mention because I found it to generally be able to fool some of the classical prefetchers. The range patterns are generally caught by most prefetchers nowadays as well, however it’s still interesting to see the results just to have an idea of how aggressive the prefetchers are, and latency curve itself can also reveal different cache latency levels or when one reaches DRAM for certain.
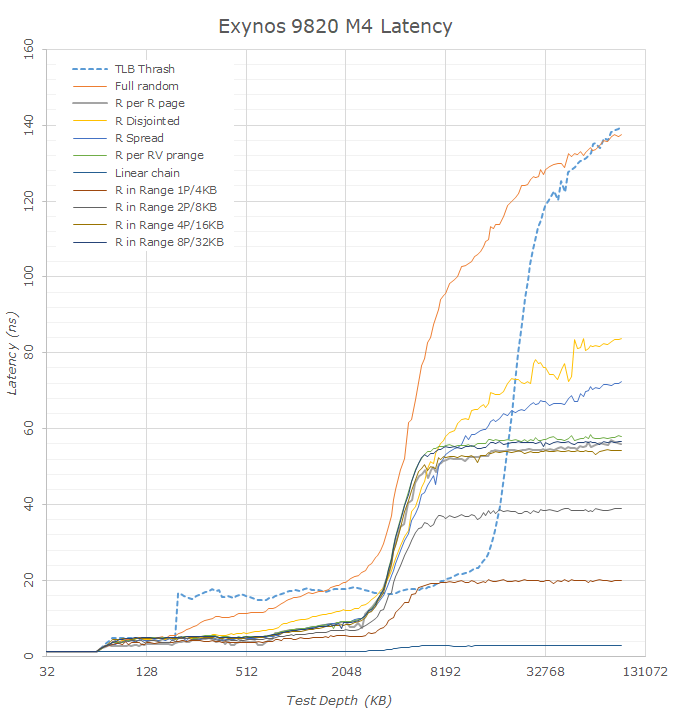
Starting off with the Exynos 9820 on the new M4 cores, we already see a huge difference in the latency behaviour, with the chip showing very different figures than those of the Exynos 9810. To analyse the M4/M3 cores against other microarchitectures we have to keep in mind Samsung’s more unusual TLB hierarchy. The M3 and M4 cores besides the A12’s Vortex cores are the only CPUs whose TLB capacity actually exceeds the equivalent cache hierarchy capacity by a noticeable margin.
Looking at the TLB Trash curve in particular we can see one improvement of the new M4 core is that it upped the size of the microTLB from 32 pages up to 48 pages. Samsung still has an extremely weird behaviour here where if one accesses just a single page more than the capacity of the microTLB then the latency suddenly jumps in a cliff-edge fashion as if the microTLB would no longer be used at all. This is contrasting to the all other CPU cores which have a more gradual transition until the accessed page count is more than double the lowest level TLB capacity, meaning the latency we’re seeing is a gradually raising mix of the lowest level TLB latency plus the next level TLB lookup latency.
As just mentioned, because of the 4096 entry main TLB of the M3/M4, we’re seeing the TLB latency curve go beyond what we actually have in terms of total cache capacity. This has an interesting effect in the full random latency figures of the Exynos 9810 and Exynos 9820 as we have a window between 4MB and ~16MB which in theory contains little to no TLB misses. Looking at the linear and prefetched patterns we see that things flatten out after 7-8MB which signals the end of the effects the cache hierarchy has on the test. Taking this window as an apples-to-apples comparison between the SoCs we see that latencies have gone down from ~124ns on the Exynos 9810 to ~95ns on the Exynos 9820. In theory this latency decrease should be structural to the design of the SoC and its memory controllers, which matches Samsung’s PR about the chip in saying they have made big upgrades in this regard.
Another interesting characteristic we can see is that many of the remaining patterns show drastically lower latency. Instead of showing some kind of structural improvements of the SoC, the actual cause here is the introduction of a new prefetcher on the M4. Here we see the usage of a new spatial memory stream prefetcher which is able to identify higher-level region and depth information in access patterns. Unfortunately for our test tools this means that many of the patterns become useless in terms of determining actual hardware latencies as we can no longer fool the prefetchers.
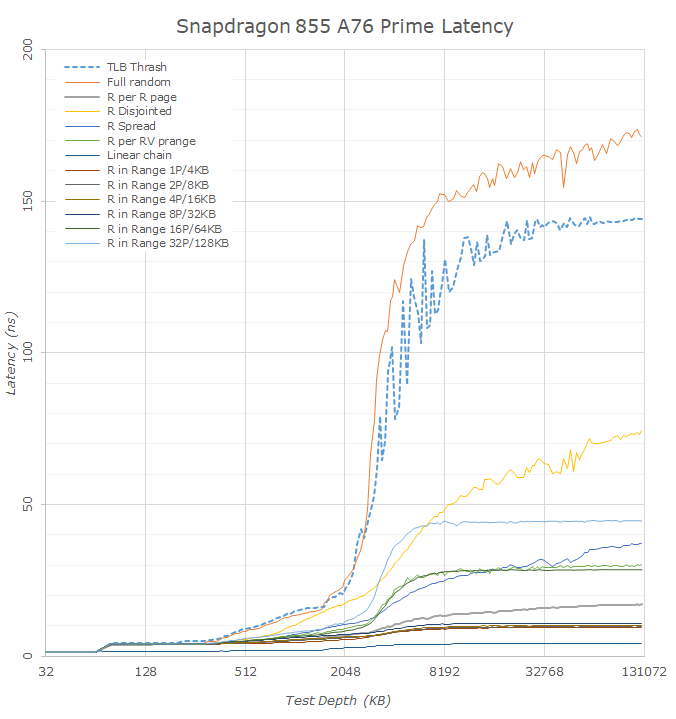
Switching over to the Snapdragon SoCs, we can use a similar methodology to compare the Snapdragon 855 to the Snapdragon 845. It’s to be noted that in terms of the figures here it’s not an apples-to-apples to the Exynos SoC, and the Cortex A75 and A76’s L2 TLB has only 1024 4K page entries, meaning page-table-walk free latency figures are only available till 4MB for the full-random data. Keeping this in mind we can see that the estimated latency from CPU to an active DRAM page is about the same at around 140ns for both SoCs. It’s actually hard to determine the exact figure here as the things vary quite a lot depending what point on the curve we’re measuring. Again, this figure would include page-walk latencies; Qualcomm’s actual structural latency would indeed be much better, around the 90ns figure as shown by some of the patterns on the Snapdragon 845.
What has actually improved drastically in the Snapdragon 855 is the deeper DRAM latency. I didn’t actually go ahead and measure larger test depths, but we can already see there’s a massive difference between the S845 and S855. The former started exceeding 200ns at 128MB while the S855 falls in at 170ns at the same point. Fundamentally this is a structural change in how Qualcomm configures its DRAM architecture in terms of banks and ranks, and greatly improves on some of the bigger latency issues of the Snapdragon 845.
One other thing to note about the new Snapdragon 855 and which also applies to the Kirin 980 is the way the other patterns behave. Arm states that the new Cortex A76 has new state-of-the-art prefetchers and looking at what the CPU is able to do one my patterns I’d very much agree with this claim. Compared to other microarchitectures including Apple’s and Intel’s latest, the Cortex A76 prefetchers are making mince-meat out of my patterns showing the lowest latencies of any platform on the market right now. I tried for a bit trying to design something that would fool the prefetchers but this is something I’ll have to continue working on. The nature of region-based prefetchers means that fundamentally any patterns which has some sort of higher-level repeatability will get caught and predicted, which unfortunately means designing a structured test other than a full random pattern is a bit complicated to achieve.
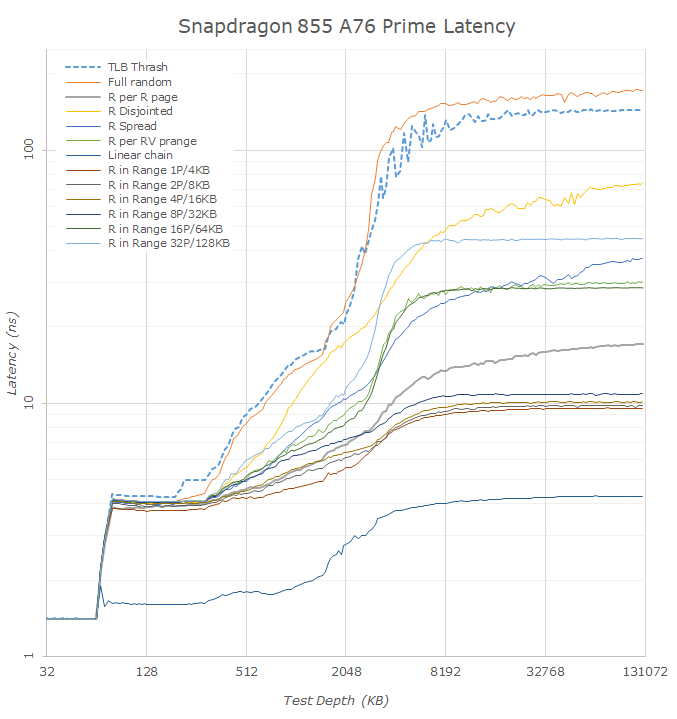
Switching over from linear graphs to logarithmic graphs this makes transitions in the cache hierarchies easier to analyse.
In the Exynos 9820 M4 results we again see the odd microTLB to mid-TLB behaviour. Interestingly the data would suggest the M4 cores only have access to 3MB of the L3. This would possibly make sense for the Exynos 9820 if the 1MB slice wound be reserved for the A55 and A75 cores. Looking back at the Exynos 9810 data however we see a similar result where the latencies jump at exactly 3MB. That chip didn’t share the L3 with the A55 cores as far as I’m aware, and if Samsung hadn’t confirmed there’s 4MB of L3 on the chip I would have said there was 3MB. I’m not too certain what’s going on here and what happened to that 1MB on the Exynos 9810.
The new A75 cores on the Exynos 9820 very much look like having 256KB L2 caches, and the L3 results points out to being 1MB. What I do find weird is the very long and gradual latency increase the deeper we go into DRAM, as opposed to a more sudden jump. I would attribute this again to how the DRAM banks and ranks are configured on the new chip.
On the Snapdragon 855 we see the 512KB vs 256KB L2 cache difference between Prime and Gold cores. A weird behaviour for which I have no explanation is the latency behaviour between the two cores in the 2-5MB region. Looking at the data, it looks as if the middle cores would have more cache available to them, with the curves being positioned more akin to the behaviour of the Kirin 980 than the Snapdragon 855’s Prime cores. I would have guessed that the Prime cores are bypassing the system level cache/SLC while the Gold cores have access to it, however after having reached out to Qualcomm on the matter they said this was not the case. Thus I remain a bit baffled on what is going on, it's possible this is just measurement noise and there was some activity on the LLC while I testing the Gold cores.
Comparing the L3 curves between the Snapdragon 855 and the Kirin 980 we see the former have better latencies. We don’t know what frequency HiSilicon is running their L3 at, but this lower latency on the part of the Snapdragon could also be due to Qualcomm’s choice of a smaller 2MB cache versus 4MB on the Kirin.
This is also a good opportunity to put Apple’s A12 Vortex core in context. One advantage Apple has in terms of memory architecture is that iOS uses 16KB pages versus 4KB on Android and Windows. While this is a negative for memory allocation space, it’s a positive for performance as there’s less TLB work to be done. Here Apple’s memory hierarchy is quite absurd as it’s just outright flat at excellent latencies till about 3MB, after which some complex TLB behaviour comes into effect.








229 Comments
View All Comments
TechieSandy - Tuesday, April 2, 2019 - link
The difference in the Dynamic Range between the Snapdragon and the Exynos variant may have less to do with processing than the triggering by the camera. In one of the pics the Exynos proxessor has better details in the shadows and more dynamic range.In this photo:
https://images.anandtech.com/galleries/6981/S10PS_...
It may be something triggering the HDR algorithm. It may have to do with it.
Andrei Frumusanu - Friday, April 5, 2019 - link
That image you linked is the Snapdragon - check the difference in detail in the marble for example.urbanman2004 - Tuesday, April 2, 2019 - link
No wonder people are holding onto their phones at the most for 4 years as indicated by this article after seeing those prices. After selling my Galaxy S7, never again will I find myself being held captive from the ever tightening stranglehold made by SamsungKishoreshack - Tuesday, April 2, 2019 - link
Excellent review by Andreithis is even better than what Brian Klug used to do
your analysis is good & conclusion are spot on
I think you missed to test the GPS on both phones
which would make it a complete review
Andrei Frumusanu - Friday, April 5, 2019 - link
GPS part taken note of, I'll see what can be done in the future.nyonya - Wednesday, April 3, 2019 - link
Will the test results be added to Bench soon? Also, any guesses as to the battery life of the (Snapdragon) S10e? There's finally a small flagship phone and I'll probably upgrade to it. And agreed on the power button location, it's stupidly high on all the S10 variants.ElFenix - Wednesday, April 3, 2019 - link
45° FoV corresponds with a 52 mm lens on a 35 mm camera, which most people would consider 'normal' rather than 'telephoto.' 77° FoV corresponds with a 27 mm lens on a 35 mm camera, which most people would consider 'wide angle.' 123° FoV corresponds with a 12 mm lens on a 35 mm camera, which most people would consider 'super wide angle.'so this phone doens't have a telephoto camera in the traditional sense. only normal, wide, and super-wide.
s.yu - Friday, April 5, 2019 - link
Indeed it is and is what many have been complaining about, the terminology issue of phone cameras.US3R13 - Sunday, April 7, 2019 - link
I have a question in regard to the camera output of the Exynos model.Does the different we saw in the review only occur in the JPG or even if we shoot raw the difference still exists?
Thanks
zoamster - Wednesday, April 10, 2019 - link
This review was a real real treat.I have been waiting for this review ever since the devices launched and have checked the website more than 20 times. No review can be better than this and I hope the authors keep doing the excellent work.
I wish samsung starts selling snapdragon Soc phones in India(which i know they won't) and stop making those shitty ass exynos processors and start including hifi dac as lg does. Maybe improve the camera software department as pixel's or apple's.
It seriously feels bad that you spend a fortune to buy trash.
One question- Will the unlocked SD variant work fine in India?
PS- Thank you for make this excellent review and I hope to see more in future.