Upgrading from an Intel Core i7-2600K: Testing Sandy Bridge in 2019
by Ian Cutress on May 10, 2019 10:30 AM EST- Posted in
- CPUs
- Intel
- Sandy Bridge
- Overclocking
- 7700K
- Coffee Lake
- i7-2600K
- 9700K
Sandy Bridge: Inside the Core Microarchitecture
In the modern era, we are talking about chips roughly the size of 100-200mm2 having up to eight high performance cores on the latest variants of Intel’s 14nm process or AMD’s use of GlobalFoundries / upcoming with TSMC. Back with Sandy Bridge, 32nm was a different beast. The manufacturing process was still planar without FinFETs, implementing Intel’s second generation High-K Metal Gate, and achieving 0.7x scaling compared to the larger 45nm previous. The Core i7-2600K was the largest quad core die, running at 216 mm2 and 1.16 billion transistors, which compared to the latest Coffee Lake processors on 14nm offer eight cores at ~170 mm2 and over 2 billion transistors.
The big leap of the era was in the microarchitecture. Sandy Bridge promised (and delivered) a significant uplift in raw clock-for-clock performance over the previous generation Westmere processors, and forms the base schema for Intel’s latest chips almost a decade later. A number of key innovations were first made available at retail through Sandy Bridge, which have been built upon and iterated over many times to get to the high performance we have today.
Through this page, I have largely used Anand’s initial report into the microarchitecture back in 2010 as a base, with additions based on the modern look on this processor design.
A Quick Recap: A Basic Out-of-Order CPU Core
For those new to CPU design, here’s a quick run through of how an out-of-order CPU works. Broadly speaking, a core is divided into the front end and back end, and data first comes into the front end.

In the front end, we have the prefetchers and branch predictors that will predict and pull in instructions from the main memory. The idea here is that if you can predict what data and instructions are needed next before they are needed, then you can save time by having that data close to the core when needed. The instructions are then placed into a decoder, which transforms the byte code instruction into a number of ‘micro-operations’ that the core can then use. There are different types of decoders for simple and complex instructions – simple x86 instructions map easily to one micro-op, whereas more complex instructions can decode to more – the ideal situation is a decode ratio as low as possible, although sometimes instructions can be split into more micro-ops if they can be run in parallel together (instruction level parallelism, or ILP).
If the core has a ‘micro-operation cache’, or uOp cache, then the results from each decoded instruction ends up there. The core can detect before an instruction is decoded if that particular instruction has been decoded recently, and use the result from the previous decode rather than doing a full decode which wastes power.
Now the uOps are now in an allocation queue, which for modern cores usually means that the core can detect if the instructions are part of a simple loop, or if it can fuse uOps together to make the whole thing go quicker, it can. The uOps are then fed into the re-order buffer, which forms the ‘back end’ of the core.
In the back end, starting with the re-order buffer, uOps can be rearranged depending on where the data each micro-op needs is. This buffer can rename and allocate uOps depending on where they need to go (integer vs FP), and depending on the core, it can also act as a retire station for complete instructions. After the re-order buffer, uOps are fed into the scheduler in a desired order to ensure data is ready and the uOp throughput is as high as possible.
In the scheduler, it passes the uOps into the execution ports (what does the compute) as required. Some cores have a unified scheduler between all the ports, however some split the scheduler depending on integer operations or vector style operations. Most out-of-order cores can have anywhere from 4 to 10 ports (or more), and these execution ports will do the math required on the data given the instruction passed through the core. Execution ports can take the form of a load unit (load from cache), a store unit (store into cache), an integer math unit, a floating point math unit, vector math units, special division units, and a few others for special operations. After the execution port is complete, the data can then be held for reuse in a cache, be pushed to main memory, while the instruction feeds into the retire queue, and finally retired.
This brief overview doesn’t touch on some of the mechanisms that modern cores use to help caching and data look up, such as transaction buffers, stream buffers, tagging, etc., some of which get iterative improvements every generation, but usually when we talk about ‘instructions per clock’ as a measure of performance, we aim to get as many instructions through the core (through the front end and back end) as many as possible – this relies on the decode strength of the front end, the prefetchers, the reorder buffers, and maximising the execution port use, along with retiring as many completed instructions as possible every clock cycle.
With this in mind, hopefully it will give context to some of Anand’s analysis back when Sandy Bridge was launched.
Sandy Bridge: The Front End
Sandy Bridge’s CPU architecture is evolutionary from a high level viewpoint but far more revolutionary in terms of the number of transistors that have been changed since Nehalem/Westmere. The biggest change for Sandy Bridge (and all microarchitectures since) is the micro-op cache (uOp cache).
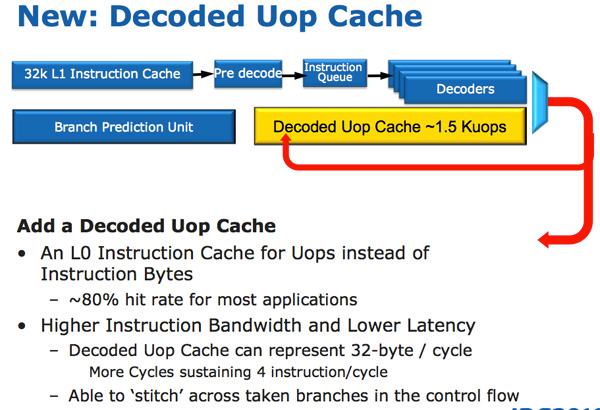
In Sandy Bridge, there’s now a micro-op cache that caches instructions as they’re decoded. There’s no sophisticated algorithm here, the cache simply grabs instructions as they’re decoded. When SB’s fetch hardware grabs a new instruction it first checks to see if the instruction is in the micro-op cache, if it is then the cache services the rest of the pipeline and the front end is powered down. The decode hardware is a very complex part of the x86 pipeline, turning it off saves a significant amount of power.
The cache is direct mapped and can store approximately 1.5K micro-ops, which is effectively the equivalent of a 6KB instruction cache. The micro-op cache is fully included in the L1 instructioncache and enjoys approximately an 80% hit rate for most applications. You get slightly higher and more consistent bandwidth from the micro-op cache vs. the instruction cache. The actual L1 instruction and data caches haven’t changed, they’re still 32KB each (for total of 64KB L1).
All instructions that are fed out of the decoder can be cached by this engine and as I mentioned before, it’s a blind cache - all instructions are cached. Least recently used data is evicted as it runs out of space. This may sound a lot like Pentium 4’s trace cache but with one major difference: it doesn’t cache traces. It really looks like an instruction cache that stores micro-ops instead of macro-ops (x86 instructions).
Along with the new micro-op cache, Intel also introduced a completely redesigned branch prediction unit. The new BPU is roughly the same footprint as its predecessor, but is much more accurate. The increase in accuracy is the result of three major innovations.
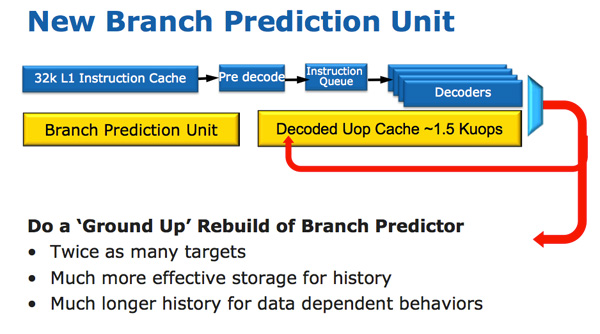
The standard branch predictor is a 2-bit predictor. Each branch is marked in a table as taken/not taken with an associated confidence (strong/weak). Intel found that nearly all of the branches predicted by this bimodal predictor have a strong confidence. In Sandy Bridge, the bimodal branch predictor uses a single confidence bit for multiple branches rather than using one confidence bit per branch. As a result, you have the same number of bits in your branch history table representing many more branches, which can lead to more accurate predictions in the future.
Branch targets also got an efficiency makeover. In previous architectures there was a single size for branch targets, however it turns out that most targets are relatively close. Rather than storing all branch targets in large structures capable of addressing far away targets, SNB now includes support for multiple branch target sizes. With smaller target sizes there’s less wasted space and now the CPU can keep track of more targets, improving prediction speed.
Finally we have the conventional method of increasing the accuracy of a branch predictor: using more history bits. Unfortunately this only works well for certain types of branches that require looking at long patterns of instructions, and not well for shorter more common branches (e.g. loops, if/else). Sandy Bridge’s BPU partitions branches into those that need a short vs. long history for accurate prediction.
A Physical Register File
Compared to Westmere, Sandy Bridge moves to a physical register file. In Core 2 and Nehalem, every micro-op had a copy of every operand that it needed. This meant the out-of-order execution hardware (scheduler/reorder buffer/associated queues) had to be much larger as it needed to accommodate the micro-ops as well as their associated data. Back in the Core Duo days that was 80-bits of data. When Intel implemented SSE, the burden grew to 128-bits. With AVX however we now have potentially 256-bit operands associated with each instruction, and the amount that the scheduling/reordering hardware would have to grow to support the AVX execution hardware Intel wanted to enable was too much.

A physical register file stores micro-op operands in the register file; as the micro-op travels down the OoO engine it only carries pointers to its operands and not the data itself. This significantly reduces the power of the out of order execution hardware (moving large amounts of data around a chip eats tons of power), and it also reduces die area further down the pipe. The die savings are translated into a larger out of order window.
The die area savings are key as they enable one of Sandy Bridge’s major innovations: AVX performance.
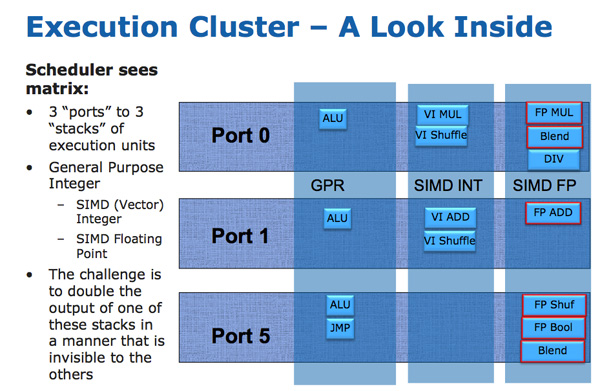
AVX
The AVX instructions support 256-bit operands, which as you can guess can eat up quite a bit of die area. The move to a physical register file enabled Intel to increase the OoO buffers to properly feed a higher throughput floating point engine. Intel clearly believes in AVX as it extended all of its SIMD units to 256-bit wide. The extension is done at minimal die expense. Nehalem has three execution ports and three stacks of execution units:
Sandy Bridge allows 256-bit AVX instructions to borrow 128-bits of the integer SIMD datapath. This minimizes the impact of AVX on the execution die area while enabling twice the FP throughput, you get two 256-bit AVX operations per clock (+ one 256-bit AVX load).
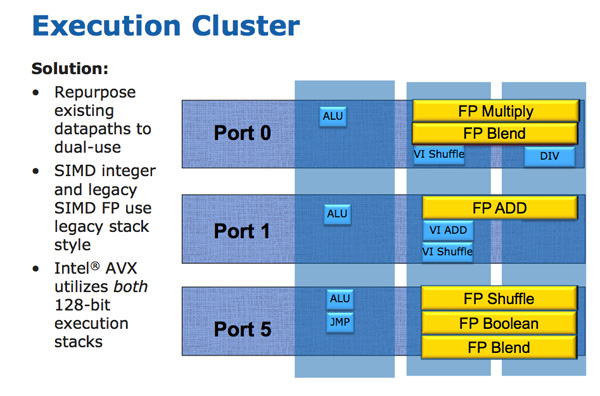
Granted you can’t mix 256-bit AVX and 128-bit integer SSE ops, however remember SNB now has larger buffers to help extract more instruction level parallelism (ILP).
Load and Store
The improvements to Sandy Bridge’s FP performance increase the demands on the load/store units. In Nehalem/Westmere you had three LS ports: load, store address and store data.
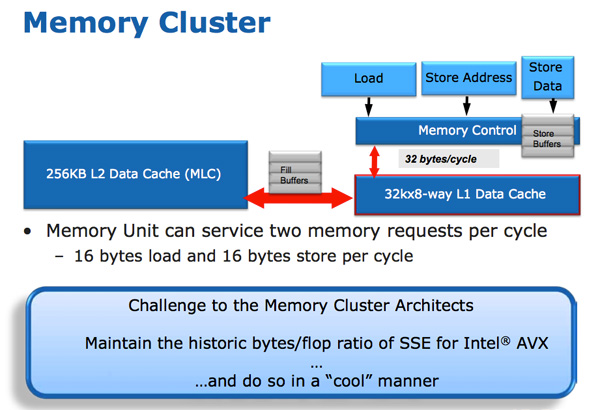
In SNB, the load and store address ports are now symmetric so each port can service a load or store address. This doubles the load bandwidth compared to Westmere, which is important as Intel doubled the peak floating point performance in Sandy Bridge.
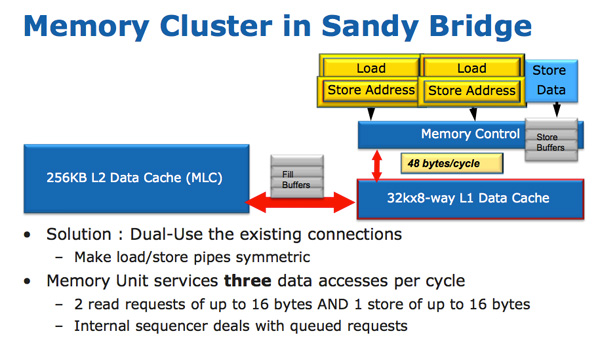
There are some integer execution improvements in Sandy Bridge, although they are more limited. Add with carry (ADC) instruction throughput is doubled, while large scale multiplies (64 * 64) see a ~25% speedup.









213 Comments
View All Comments
Death666Angel - Sunday, May 12, 2019 - link
I've done some horrendous posts when I used my phone to make a comment somewhere. Mostly because my phone is trained to my German texting habits and not my English commenting habits. And trying to mix them leads to sub par results in both areas, so I mostly stick to using my phone for texting and my PC and laptop for commenting. But sometimes I have to write something via my phone and it makes a beautiful mess if I'm not careful.Death666Angel - Sunday, May 12, 2019 - link
Well, laptops and desktops (with monitors) are in a different category anyway, at least that's how I see it. :-)I work with a 13.3" laptop with a 1440p resolution and 150% scaling. It's not fun, but it does the job. The advantage of the larger screen real estate with a 15" or 17" laptop is outweight by the size and weight increase. I've also done work on 1024x768 monitors and it does the job in a pinch. But I've tried to upgrade as soon as the new technology was established, cheap and good enough to make it worth it without having to pay the early adopter fee or fiddle around to get it to work. Even before Win7 made it a breeze to have multiple windows in an orderly grid, I took full advantage of a multi window and multi program workflow for research, paper/presentation writing, editing and media consumption. So it is a bit surprising to see someone like Ian, a tech enthusiast with a university doctorate be so late to great tech that can really make life easier. :D
Showtime - Saturday, May 11, 2019 - link
Great article. Was hoping to see all the CPU's tested (my 4770k), but I think it shows enough. This isn't the 1st article showing that lesser CPU's can run close to the best CPU's when it come to 4k gaming. Does that look to change any time soon? I was thinking I should upgrade this year, but would like to know if I should be shooting for an 8 core, or if a 6 will be a decent enough upgrade.Consoles run slower 8 core proc's that are utilized more efficiently. At some point won't pc games do the same?
Targon - Tuesday, May 14, 2019 - link
There is always the question about what you do on your computer, but I wouldn't go less than 8 cores(since 4-core has become the base on the desktop, and even laptops should never be sold with only 2 cores IMO). If you look at the history, when AMD wasn't competitive and Intel stopped trying to actually innovate, quad-core was all you saw on the desktop, so game developers didn't see a reason to support more threads(even though it would have made sense). Once Ryzen came out with 8 cores, and Intel finally responded, you have to expect that every game developer will design with the potential that players will have 8+ core processors, so why not design with that in mind?Remember, a program that is properly multi-threaded in design will work on lower-core processors, but will scale up well when processors with more cores are being used. So going forward, quad-core would work, but 8 or more threads WILL feel a lot better, even for overall use.
CaedenV - Saturday, May 11, 2019 - link
This was a fascinating article! And what I am seeing in the real world seems to reflect this.For the most part, the IPC for general use has improved, but not by a whole lot. But if doing anything that hits the on-chip GPU, or requiring any kind of decrypt/encrypt, then the dedicated hardware in newer chips really makes a big difference.
But at the end of the day, in real-world scenarios, the CPU is simply not the bottle neck for most people. I do a lot of video ripping (all legally purchased, and only for personal use), and the bottleneck is squarely on the Blu-Ray drive. I recently upgraded from a 4x to a 10x drive, and the performance bump was exactly what was expected. Getting a faster CPU or GPU will not help there.
I do a bit of video editing, and the bottle-neck there is still almost always in storage. The 1gbps connection to the NAS, and the 1GBps connection to my RAID0 of SSDs.
I do a bit of gaming at 4k, and again the bottleneck there is squarely on the GPU (GTX1080), and as your tests show, at lower resolution my chip will be slower than a new chip... but still faster than the 60-120fps refresh of the monitor.
The real reason for an upgrade simply isn't the CPU for most people. The upgrade is the chipset. Faster/more RAM, M.2 SSDs, more available throughput for expansion cards, faster USB/USB-C ports, and soon(ish) 10gig Ethernet. These are the things that make life better for the enthusiast and the normal user; and the newer CPUs are simply more capable of taking advantage of all the extra throughput, where Sandy Bridge would perhaps choke when dealing with these newer and faster interfaces that are not available to it.
All that said; I am still not convinced to upgrade. Every previous computer was simply broken, or could not do something after 2-3 years, so an upgrade was literally necessary. But now... my computer is some 8 years old now, and I am amazed at the fact that it still does it all, and does it relatively quickly. Without it being 'broken' it is hard to justify dropping $1000+ into a new build. I mean... I want to upgrade. But I also want to do some house projects, and replace a car, and do stuff with the kids... *sigh* priorities. Part of me wishes that it would break to give me proper motivation to replace it.
webdoctors - Saturday, May 11, 2019 - link
Great timing, I've been using the same chip for 7 or 8 years now and never felt the need to upgrade until this year, but I will upgrade end of this year. DDR4 finally dropped in price and my GTX1070TI I think is getting throttled when the CPU ain't overclocked.atomicWAR - Saturday, May 11, 2019 - link
Gaming at 4K with a i7 3930K @ 4.2ghz (4.6ghz capable when needed) with 2 GTX 1080s...I was planning a new build this year but after reading this I may hold off even longer.wrkingclass_hero - Sunday, May 12, 2019 - link
I've got a 3930K as well. I was planning on upgrading to Threadripper 3 when that comes out, but if it gets delayed I may wait a bit longer for a 5mm Threadripper.mofongo7481 - Saturday, May 11, 2019 - link
I'm still using a sandy bridge i5 2400 overclocked to 3.6Ghz. Still playing modern stuff @ 1080p and pretty enjoyable.Danvelopment - Sunday, May 12, 2019 - link
I think the conclusion is slightly off for gaming, from what I could see it's not that the newer processors were only better higher resolutions, it's that the newer systems were better able to keep the GPU fed with data, resulting in a higher maximum frame rate.So at lower resolutions/quality settings, when the GPUs could let loose they could achieve much higher FPS.
My conclusion from the results wouldn't be to keep it for higher res gaming, but to keep it for gaming if you're still using a 60Hz display (which I am). I bet if you tuned quality settings for all of the GPUs to run at 60 FPS your results would sit pretty close at any resolution.
I'm currently running an E5-2670 for my gaming machine with quad channel DDR3 (4x8GB) and a 1070. That's the budget upgrade path I'd probably recommend at 60Hz.