The NVIDIA GeForce GTX 1660 Ti Review, Feat. EVGA XC GAMING: Turing Sheds RTX for the Mainstream Market
by Ryan Smith & Nate Oh on February 22, 2019 9:00 AM ESTCompute & Synthetics
Shifting gears, we'll look at the compute and synthetic aspects of the GTX 1660 Ti.
Beginning with CompuBench 2.0, the latest iteration of Kishonti's GPU compute benchmark suite offers a wide array of different practical compute workloads, and we’ve decided to focus on level set segmentation, optical flow modeling, and N-Body physics simulations.


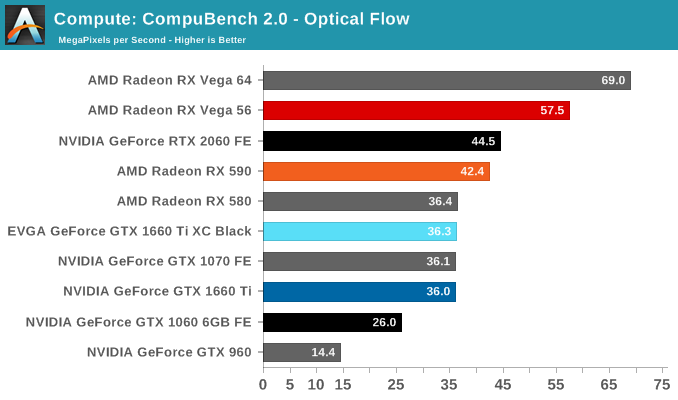
On paper, the GTX 1660 Ti looks to provide around 85% of the RTX 2060's compute and shading throughput; for Compubench, we see it achieving around 82% of the latter's performance.
Moving on, we'll also look at single precision floating point performance with FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance.
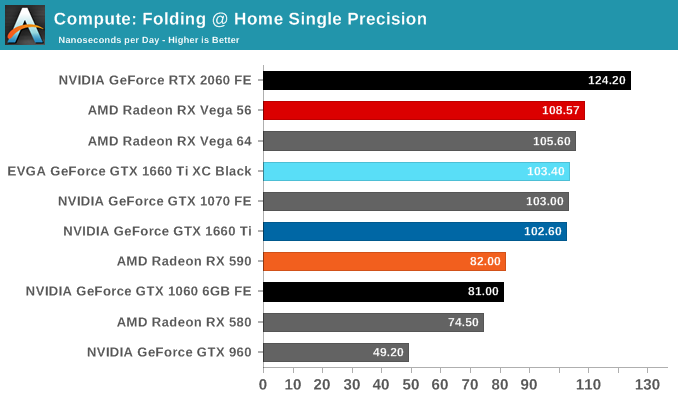
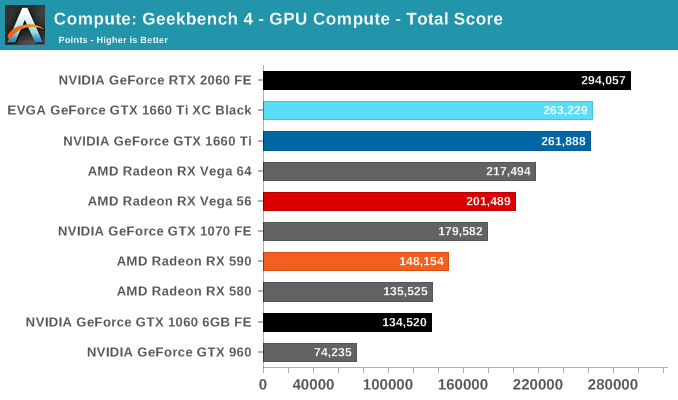
Next is Geekbench 4's GPU compute suite. A multi-faceted test suite, Geekbench 4 runs seven different GPU sub-tests, ranging from face detection to FFTs, and then averages out their scores via their geometric mean. As a result Geekbench 4 isn't testing any one workload, but rather is an average of many different basic workloads.
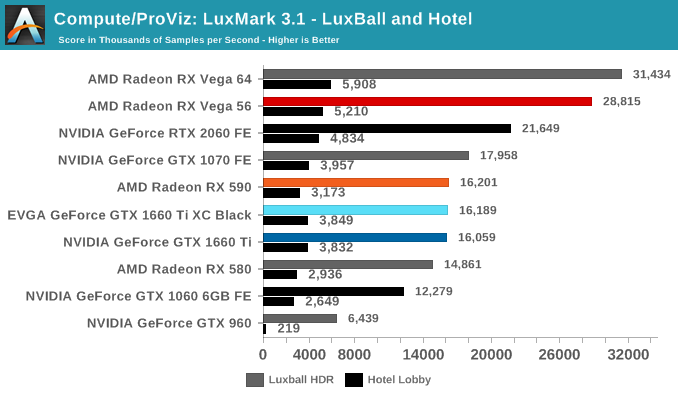
In lieu of Blender, which has yet to officially release a stable version with CUDA 10 support, we have the LuxRender-based LuxMark (OpenCL) and V-Ray (OpenCL and CUDA).
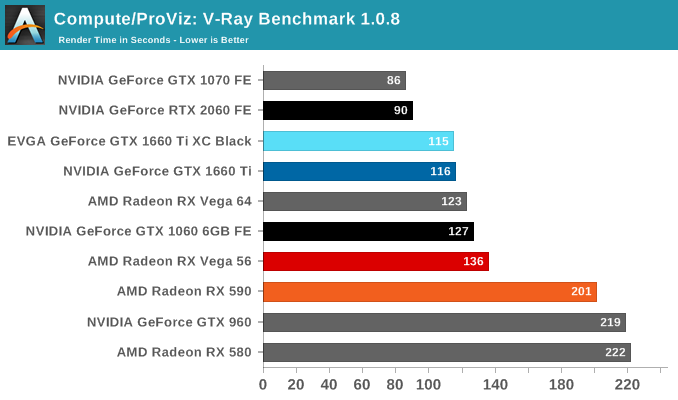
We'll also take a quick look at tessellation performance.
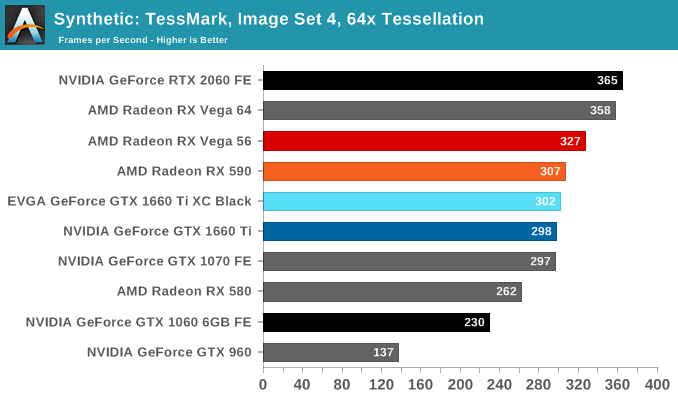
Finally, for looking at texel and pixel fillrate, we have the Beyond3D Test Suite. This test offers a slew of additional tests – many of which we use behind the scenes or in our earlier architectural analysis – but for now we’ll stick to simple pixel and texel fillrates.
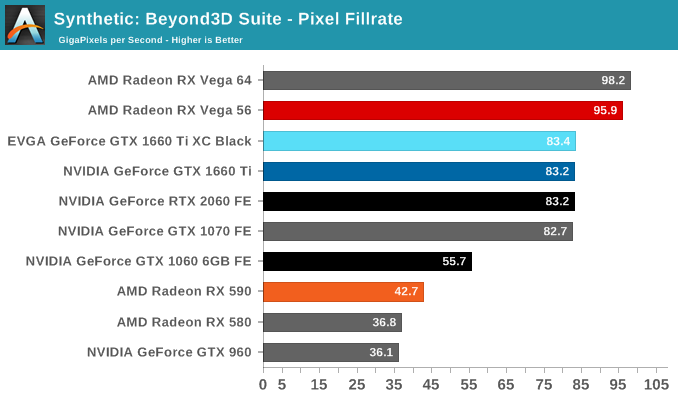
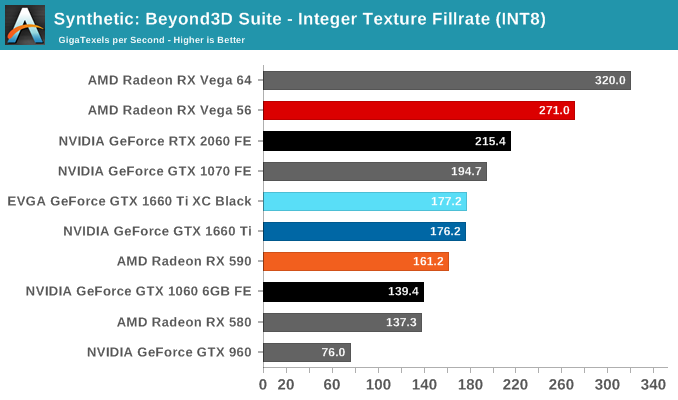
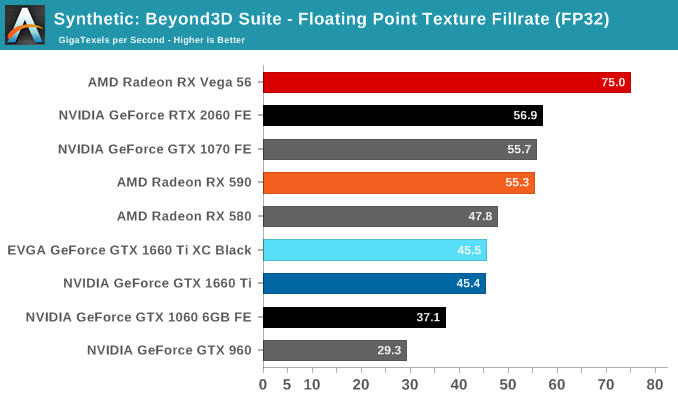
The practically identical pixel fill rates for the GTX 1660 Ti and RTX 2060 might seem odd at first blush, but it is an entirely expected result as both GPUs have the same number of ROPs, similar clockspeeds, same GPC/TPC setup, and similar memory configurations. And being the same generation/architecture, there aren't any changes or improvements to DCC. In the same vein, the RTX 2060 puts up a 25% higher texture fillrate over the GTX 1660 Ti as a consequence of having 25% more TMUs (96 vs 120).








157 Comments
View All Comments
Retycint - Tuesday, February 26, 2019 - link
AMD selling overpriced cards does not subtract from the point that Nvidia is also attempting to raise the price as well. Both companies have put out underwhelming products this genRocket321 - Friday, February 22, 2019 - link
"finally puts a Turing card in competition with their Pascal cards" should say Polaris.Ryan Smith - Friday, February 22, 2019 - link
Boy I can't wait for Navi, since it sounds nothing like Turing...Thanks!
Kogan - Friday, February 22, 2019 - link
Aww, I was hoping this release would lower the price on those used 1070's. Oh well. I'll still probably go for a used 1070 over this one. Nearly identical in every way and can be found for as low as $200.Hamm Burger - Friday, February 22, 2019 - link
Reading "Turing Sheds" in the headline makes me wonder what he could have done with a couple of these at Bletchley Park (which, for anybody passing, is well worth the steep entry fee — see bletchleypark.org.uk).Sorry for the interruption. I'll return you to the normal service.
Colin1497 - Friday, February 22, 2019 - link
"Now the bigger question in my mind: why is it so important to NVIDIA to be able to dual-issue FP32 and FP16 operations, such that they’re willing to dedicate die space to fixed FP16 cores? Are they expecting these operations to be frequently used together within a thread? Or is it just a matter of execution ports and routing?"It seems pretty likely that they added the FP16 cores because it simplified design, drivers, etc. It was easier to just drop in a few (as you mentioned) tiny FP16 cores than it was to change behavior of the architecture.
CiccioB - Friday, February 22, 2019 - link
FP16 is a way to simplify shading computing over the common used FP32.They allow for higher bandwidth (x2) and higher speed (x2, so half the energy for the same work) with the same HW space occupation. It was a feature used in HPC where bandwidth, power consumption and of course computation time are quite critical. They then ended in game class architecture just because they have find a way to exploit it there too.
Some games have started using FP16 for their shading. On AMD fence, only Vega class cards support packed FP16 math.
The use of a INT ALU that executes integer instructions together with the FP ones is instead an exclusive feature that can really improve shading performance much more than any other complex feature like high threaded (constantly interrupted) mechanism that is needed on architectures that cannot keep the ALUs feed.
In fact we see that with less CUDA cores Turing can do the same work of Pascal even using less energy. And no magic ACE is present.
Yojimbo - Friday, February 22, 2019 - link
They didn't just drop in a few. It seems they have enough for 2x FP32 performance. Why are they dual issue? My guess is it is because that is what's necessary for Tensor Core operation. I think NVIDIA is being a bit secretive about the Tensor Cores. It's clear they took the RT Core circuitry out of the Turing minor die. As far as the Tensor Cores, I'm not so sure. Think about it this way: suppose Tensor Cores really are specialized separate cores. Then they also happen to have the capability of non tensor FP16 operation in dual issue with FP32 CUDA cores? Because if they don't then whatever functionality NVIDIA has planned for the FP16 cores on Turing minor would be incompatible with Turing major and Volta. I don't see how that can be the case, however, because, according to this review, Turing major is listed as the same CUDA compute generation as Turing minor. Now if the Tensor Cores can double as general purpose FP16 CUDA cores, then what's to say that FP16 and FP32 CUDA cores can't double as Tensor Cores? That is, if the Tensor Core can be made with two data flow paths, one following general purpose FP16 operations and one following Tensor Core instruction operations, then commutatively a general purpose CUDA core can be made with two data flow paths, one following general purpose operations and one following Tensor Core instruction operations.When Turing came out with Tensor Core operations but with FP64 cores cut from the die and no increase in FP32 CUDA cores per SM over Volta I was surprised. But with this new information from the Turing Minor launch it makes more sense to me. I don't know if they have the dedicated FP16 cores on Volta. If they do then the FP64 cores don't need to play the following role, but if they are able to use the FP64 cores as FP16 cores then hypothetically they have enough cores to account for the 64 FMA operations per clock per SM of the 8 Tensor Cores per SM. But on Turing major they just didn't have the cores to account for the Tensor Core performance. These FP16 cores on Turing minor seem to be exactly what would be necessary to make up for the shortfall. So, my guess is that Turing major also has these same cores. The difference is either entirely one of firmware/drivers that allows the Tensor Core data path to be operated on Turing major but not Turing minor or Turing major has some extra circuitry that allows the CUDA cores to be lashed together with an alternate data flow path that doesn't exist in Turing minor.
GreenReaper - Friday, February 22, 2019 - link
Agreed. It seems likely that most of the hardware is present, just not active.Frankly, it's not clear why these couldn't be binned versions of the higher-level chips that haven't met the QA requirements, which would be one reason it took this long to release - you need enough stock to be able to distribute it. If it's planned out in advance, they just need X good CUDA cores and Y ROPs that run at Z Mhz, combined with at least [n] MB of cache. Fuse off the bad or unwanted portions to save on power and you're good.
Of course it *could* be like Intel, which truly make smaller derivatives. If so that suggests they'll be selling a lot of these cards. Even then, though, Yojimbo's supposition about the core design being essentially the same is likely to be true.
Yojimbo - Saturday, February 23, 2019 - link
Yeah the die size and transistor count is still large for the number of CUDA cores, being that this review claims the 1660Ti has all SMs on the TU116 enabled. I said it was clear they took RT circuitry out. But I was wrong, that's not clear. It seems the die area per CUDA core and transistors per CUDA core of the TU116 are extremely close to the TU106, which is fully-enabled in RTX 2070. If this is the result of the INT32 and FP16 cores of the TU116 then where exactly do any cost savings of removing the Tensor Cores and RT Cores come from? Definitely the cost of completely re-architecting another GPU would outweigh the slight reduction in die size they seem to have achieved.On the other hand, I'd imagine TU116 will be such a high volume part that unless yields are really lousy, binning alone won't provide enough chips (and where are the fully enabled versions of the 284 mm^2 RTX dies going, anywhere? No such product has thus far been announced.) Perhaps such a small number of RT cores was judged to be insufficient for RTX gaming. Even if not impossible to create some useful effects including that many RT cores, if developers were incentivized to target such few RT cores with their RTX efforts because the volume of such RT-enabled cards was significant then they may reduce the scope and scale of RTX enhancements they undertake, putting a drag on the adoption of the technology. So NVIDIA opted to disable the RT cores, and perhaps the Tensor Cores, present on the dies even when they are actually fully functioning. Perhaps it was simply cheaper to eat the wasted die space per chip than to design an entirely new GPU with the RT cores and Tensor Cores removed.