AMD Comments on Threadripper 2 Performance and Windows Scheduler
by Ian Cutress on January 14, 2019 9:00 AM EST- Posted in
- CPUs
- AMD
- Trade Shows
- EPYC
- Threadripper 2
- CES 2019

Users may have been following Wendell from Level1Tech’s battle with researching the reasons behind why some benchmarks have regressed performance on quad-die Threadripper 2 compared to dual-die configurations. Through his research, he found that this problem was limited to Windows, as cross-platform software on Linux did not have this issue, and that the problem was not limited just to Threadripper 2, but quad-die EPYCs were also affected.
At the time, most journalists and analysts noted that the performance was lower, and that the Linux/Windows differences existed, but pointed the finger at the reduced memory performance of the large Threadripper 2 CPUs. At the time, Wendell discovered that removing CPU 0 from the thread pool, after the program starts running, it actually regained all of the performance loss on Windows.
After some discussions about what the issue was exactly, I helped Wendell with some additional testing, by running our CPU suite through an affinity mask at runtime to remove CPU 0 from the options at runtime. The results were negative, suggesting that the key to CPU 0 was actually changing it at run time.
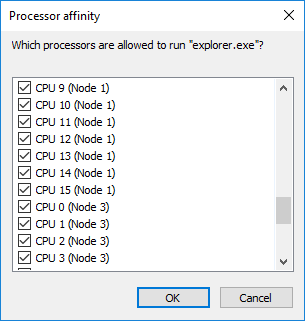
After this, Wendell did his testing on an EPYC 7551 processor, one of the big four-die parts, and confirmed this was not limited to just Threadripper – the problem wasn’t memory, it was almost certainly the Windows Scheduler.
'Best NUMA Node' and Windows Hotfix for 2-NUMA
The conclusion was made that in a NUMA environment, Windows’ scheduler actually assigns a ‘best NUMA node’ for each bit of software and the scheduler is programmed to move those threads to that node as often as possible, and will actually kick out threads that also have the same ‘best NUMA node’ settings with abandon. When running a single binary that spawns 32/64 threads, every thread from that binary is assigned the same ‘best NUMA node’, and these threads will continually be pushed onto that node, kicking out threads that already want to be there. This leads to core contention, and a fully multi-threaded program could spend half of its time shuffling around threads to comply with this ‘best NUMA node’ situation.
The point of this ‘best NUMA node’ environment was originally meant to be for running VMs, such that each VM would run in its own runtime and be assigned different ‘best NUMA nodes’ depending on what else was currently on the system.
One would expect this issue to come up in any NUMA environment, such as dual processors or dual-die AMD processors. It turns out that Microsoft has a hotfix in place in Windows for dual-NUMA environments that disables this ‘best NUMA node’ situation. Ultimately at some point there were enough dual-socket workstation platforms on the market that this made sense, pushing the ‘best NUMA node’ implementation down the road to 3+ NUMA environments. This is why we see it in quad-die Threadripper and EPYC, and not dual-die Threadripper.
Wendell has been working with Jeremy from BitSum, creator of the CorePrio software, in developing a way of soft-fixing this issue. The CorePrio software now has an option called ‘NUMA Disassociator’ which probes which software is active every few seconds and adjusts the thread affinity while the software is running (rather than running an affinity mask which has no affect).
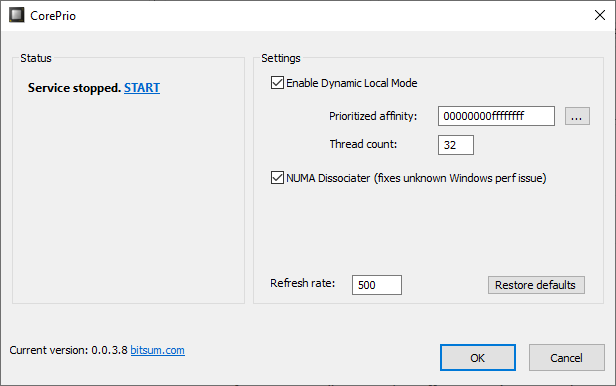
This is a good temporary solution for sure, however it needs to be fixed in the Windows scheduler.
AMD Comments On The Findings
There have been questions about how much AMD/Microsoft know about this issue, who they are in contact with, and what is being done. AMD was happy to make some comments on the record.
AMD stated that they have support and update tickets open with Microsoft’s Windows team on the issue. They believe they know what the issue is, and commends Wendell for being very close to what the actual issue is (they declined to go into detail). They are currently comparing notes with Bitsum, and actually helped Bitsum to develop the original tool for affinity masking, however the ‘NUMA Disassociator’ is obviously new.
The timeline for a fix will depend on a number of factors between AMD and Microsoft, however there will be announcements when the fix is ready and what exactly that fix will affect performance. Other improvements to help optimize performance will also be included. AMD is still very pleased with the Threadripper 2 performance, and is keen to stress that for the most popular performance related tests the company points to reviews that show that the performance in rendering is still well above the competition, and is working with software vendors to push that performance even further.








39 Comments
View All Comments
Xajel - Monday, January 14, 2019 - link
Zen2 Epyc doesn't have NUMA in a single socket platform, so the OS will not bother.NUMA stands for Non Uniform Memory Access which is when Core 6 for example have different latency to access specific part of the memory than Core 2. It started with multi socket platform after the memory controller was moved to the CPU where a core in any socket will have higher latency when it tries to access the memory connected to other socket, so the OS schedualer and even the software must be aware of this (NUMA aware scheduling). But 1st gen EPYC have this topology in the socket it self where each 8 cores have their own IMC and when a die needs access to a memory connected to another die it will have higher latency.
Zen2 Epyc doesn't have NUMA in the same socket as the IMC is in the IO die and all cores in the same socket have the same latency accessing the memory. Thought multi socket Zen2 Epyc will have NUMA.
lightningz71 - Tuesday, January 15, 2019 - link
While you've got the layout right and the general idea correct, you are missing one key point, NUMA isn't just about access to MAIN memory, it's about access to memory in general. Each chiplet is expected to have 32MB of L3 cache (16 per CCX is they keep a pair of quads). Access to the local L3 will be cheap. Access to a remote L3 will be expensive, likely quite expensive. You need to tell the scheduler to make its best effort to keep related threads together on each chiplet. How would you do that? Using the NUMA architecture. You define each group of cores on a chiplet as a single NUMA node. ROME will likely have 8 NUMA nodes at max, one for each chiplet. If they kept the CCX units as quads, you could realize some performance gains in some corner cases by defining each CCX as a NUMA node. Threadripper 3 should have just as many nodes as it will likely share the same package topology.Looking at the I/O chiplet of the Matisse sample, if we compare the area of that chip with the area of a Ryzen 1xxx chip, we see that it roughly matches the area of the uncore from Ryzen 1. This doesn't leave any area at 14nm for an L3 cache. I don't expect Matisse to have an L4 cache on the IO chiplet. For ROME and TR3, we can see that the IO die is roughly 4X the Matisse one. Again, that has to account for 4X the uncore of each Ryzen 1 chip, leaving very little room for an L4 cache. There might be some substantial buffering for the memory controllers, but I don't see where it would have a big L4 cache in this generation.
Going forward, once 7nm production scales out, I could see a day where the IO die is moved to an older 7nm process while the chiplets are moved to a newer, higher performance node like 7nm+ or even 5nm. In that case, if they keep the chips the same relative size, there will be plenty of room on the chip for a massive L4 cache. Just, keep in mind that, for it to be effective, it not only needs to be at least as large as the combined total of the L3 caches on all eight core chiplets, so, that's 256MB in the current generation (8 X 32MB), but it needs to be roughly 4X the size to provide a useful amount of memory bandwidth reduction to perform its main job of being a cache. That would mean that each EPYC and TR3 processor should have an L4 of 1GB in size on package. Now, while that's not impossible using 7nm, that is absolutely massive for an on chip cache in general. Its also not likely to make a huge increase in performance in general use cases. Where it would make the biggest improvement is if the sum of all the active processes current work sets is able to stay comfortably on that I/O die's L4 cache AND there's a lot of cross chiplet data snooping.
Dodozoid - Thursday, January 17, 2019 - link
Are you sure that different distances to L3 neccesitate NUMA mode? Even Zeppelin has two CCXs with cache in each and accessing other CCX's L3 meant trip through IF. And I don't think that it is transparent to the OS rather than being managed by the chip itself (or does it have special setting in windows scheduler?). Heck even intel CPUs with older multi-ring buses had 3 different latencies to different core's L3 (own, same ring, other ring) and thats before they started with the mesh... I am by no means programer or IC engineer or whatever so I might be completely wrong here...peevee - Thursday, May 30, 2019 - link
Keeping threads on the same core is good anyway, regardless memory and L3 architecture. Simply because of very expensive L1 and L2 thrashing. All properly written software performance-critical sets thread affinities itself (or at least Ideal Processor on Windows), not relying on scheduler. And it must be done before memory allocation, done by each thread for itself - and that relies on a good memory manager allocating memory on the same NUMA node as the thread. Scheduler has no idea which memory each thread uses, and without completely unrealistic interpretation of the code, there is no way for it to learn.IGTrading - Monday, January 14, 2019 - link
@FreckledTrout well it was Microsoft generated issue from the beginning.Microsoft is accountable and I guess that discussing this and making it a popular topic will prompt and quick and effective move from Microsoft.
I'm confident the move will be both to fix this and to investigate those responsible (from within the company) no matter if it was intentional or not, because Microsoft cannot afford such blunders, especially on their core products such as Windows OS.
FreckledTrout - Monday, January 14, 2019 - link
That was what I meant. Just keep this in the news cycle every now and then.jimjamjamie - Monday, January 14, 2019 - link
Obligatory "just use Linux" commentIGTrading - Monday, January 14, 2019 - link
@jimjamjamie : You kinda got a point there, mate :) Linux FTW.FunBunny2 - Monday, January 14, 2019 - link
"Wormer, he's a dead man! Marmalard, dead! NEIDERMEYER......!!!!!!!!!"-- D-Day
Lord of the Bored - Monday, January 14, 2019 - link
But I like computers that work in the general sense over computers that properly support high-end hardware but stumble over wifi and bluetooth.