AMD Comments on Threadripper 2 Performance and Windows Scheduler
by Ian Cutress on January 14, 2019 9:00 AM EST- Posted in
- CPUs
- AMD
- Trade Shows
- EPYC
- Threadripper 2
- CES 2019

Users may have been following Wendell from Level1Tech’s battle with researching the reasons behind why some benchmarks have regressed performance on quad-die Threadripper 2 compared to dual-die configurations. Through his research, he found that this problem was limited to Windows, as cross-platform software on Linux did not have this issue, and that the problem was not limited just to Threadripper 2, but quad-die EPYCs were also affected.
At the time, most journalists and analysts noted that the performance was lower, and that the Linux/Windows differences existed, but pointed the finger at the reduced memory performance of the large Threadripper 2 CPUs. At the time, Wendell discovered that removing CPU 0 from the thread pool, after the program starts running, it actually regained all of the performance loss on Windows.
After some discussions about what the issue was exactly, I helped Wendell with some additional testing, by running our CPU suite through an affinity mask at runtime to remove CPU 0 from the options at runtime. The results were negative, suggesting that the key to CPU 0 was actually changing it at run time.
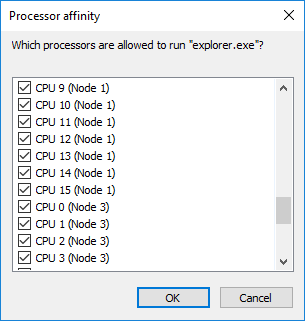
After this, Wendell did his testing on an EPYC 7551 processor, one of the big four-die parts, and confirmed this was not limited to just Threadripper – the problem wasn’t memory, it was almost certainly the Windows Scheduler.
'Best NUMA Node' and Windows Hotfix for 2-NUMA
The conclusion was made that in a NUMA environment, Windows’ scheduler actually assigns a ‘best NUMA node’ for each bit of software and the scheduler is programmed to move those threads to that node as often as possible, and will actually kick out threads that also have the same ‘best NUMA node’ settings with abandon. When running a single binary that spawns 32/64 threads, every thread from that binary is assigned the same ‘best NUMA node’, and these threads will continually be pushed onto that node, kicking out threads that already want to be there. This leads to core contention, and a fully multi-threaded program could spend half of its time shuffling around threads to comply with this ‘best NUMA node’ situation.
The point of this ‘best NUMA node’ environment was originally meant to be for running VMs, such that each VM would run in its own runtime and be assigned different ‘best NUMA nodes’ depending on what else was currently on the system.
One would expect this issue to come up in any NUMA environment, such as dual processors or dual-die AMD processors. It turns out that Microsoft has a hotfix in place in Windows for dual-NUMA environments that disables this ‘best NUMA node’ situation. Ultimately at some point there were enough dual-socket workstation platforms on the market that this made sense, pushing the ‘best NUMA node’ implementation down the road to 3+ NUMA environments. This is why we see it in quad-die Threadripper and EPYC, and not dual-die Threadripper.
Wendell has been working with Jeremy from BitSum, creator of the CorePrio software, in developing a way of soft-fixing this issue. The CorePrio software now has an option called ‘NUMA Disassociator’ which probes which software is active every few seconds and adjusts the thread affinity while the software is running (rather than running an affinity mask which has no affect).
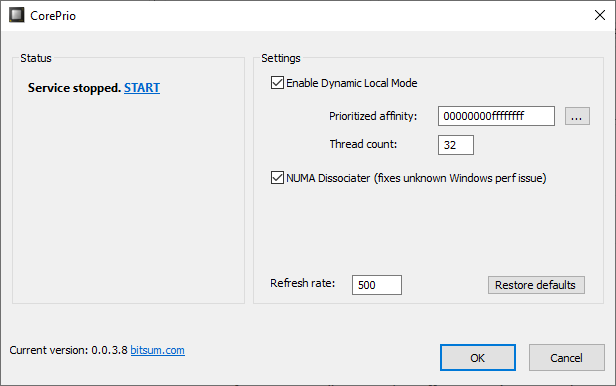
This is a good temporary solution for sure, however it needs to be fixed in the Windows scheduler.
AMD Comments On The Findings
There have been questions about how much AMD/Microsoft know about this issue, who they are in contact with, and what is being done. AMD was happy to make some comments on the record.
AMD stated that they have support and update tickets open with Microsoft’s Windows team on the issue. They believe they know what the issue is, and commends Wendell for being very close to what the actual issue is (they declined to go into detail). They are currently comparing notes with Bitsum, and actually helped Bitsum to develop the original tool for affinity masking, however the ‘NUMA Disassociator’ is obviously new.
The timeline for a fix will depend on a number of factors between AMD and Microsoft, however there will be announcements when the fix is ready and what exactly that fix will affect performance. Other improvements to help optimize performance will also be included. AMD is still very pleased with the Threadripper 2 performance, and is keen to stress that for the most popular performance related tests the company points to reviews that show that the performance in rendering is still well above the competition, and is working with software vendors to push that performance even further.








39 Comments
View All Comments
FreckledTrout - Monday, January 14, 2019 - link
Or MS just messed up and Linux driver developers did not.Alistair - Monday, January 14, 2019 - link
Read the article:It turns out that Microsoft has a hotfix in place in Windows for dual-NUMA environments that disables this ‘best NUMA node’ situation. Ultimately at some point there were enough dual-socket workstation platforms on the market that this made sense, pushing the ‘best NUMA node’ implementation down the road to 3+ NUMA environments. This is why we see it in quad-die Threadripper and EPYC, and not dual-die Threadripper.
So clearly since Intel's 16 core CPU's are not treated as 3 or 4 sockets, it won't affect them. It only affects 4 processor systems, or processors treated as such like the 32 core Threadripper.
KaiserWilly - Tuesday, January 15, 2019 - link
You're not understanding how AMD Threadripper is made compared to Intel.Intel uses a monolithic die approach, where it's architecturally and visually a single CPU. Everything works because there's no NUMA fit at all. There's no NUMA. It just doesn't apply.
AMD uses a multi-die solution that appears to Windows as multiple CPUs (note the graphic in the article showcasing Node0, Node1, etc.), which requires this extra scheduling to operate properly.
The idea that because AMD requires this means they are inferior is also false, it's merely a different implementation that trades occasional bugs like this for an architecture that's highly flexible, not requiring the LCC, HCC, and XCC designs that Intel uses to cope with the extra cores. Microsoft erred in their scheduling, creating a large proportion of the performance decrease when using >2 Nodes. The fact that it can be readily fixed and is not present on Linux lends credence to the suggestion that this is a bug, and not "AMD being terrible."
And god I hope you're relying more than just drivers to run a CPU, that'd be a nightmare...
PeachNCream - Monday, January 14, 2019 - link
Please step away from your keyboard, sir.FullmetalTitan - Wednesday, January 16, 2019 - link
Gonna wait here while you figure out how a Windows scheduler problem is not an option because the company also sells game consoles with AMD chips. As if Playstation consoles don't have nearly identical core designs.Bonus: detail how exactly XBone or PS4 are running into 3+ NUMA environment issues to justify that first point
cheshirster - Wednesday, January 16, 2019 - link
You are so 2007.Windows is not important for MS any more.
W10 is plagued with violent bugs and noone cares.
FreckledTrout - Monday, January 14, 2019 - link
Do we think it will be solved before Zen2 variants get the shelves? Anandtech can we hold Microsoft accountable on this now? It's clearly a MS issue now.oleyska - Monday, January 14, 2019 - link
I do not how Zen2 will handle NUMA.But it will be very different as every core will have common DDR controller rather than distributed so Numa 1 will never go to numa 2 for DDR access.
L3 cache will be interesting to see if they will ever access cache across die's.
rns.sr71 - Monday, January 14, 2019 - link
'L3 cache will be interesting to see if they will ever access cache across die's.'-Very good point.
I haven't read any direct confirmation from AMD (so please anyone that has, please provide links) but apparently, there are two possibilities on this. (1) The 8 core chiplets will will have to hop from the IO die to the other chiplet(s) as AMD has said that there is no direct link between chiplets OR (2) the IO die will have adequate cache of its own to copy all L3 data from all 8 core chiplets on package. The 2nd option would provide the lowest latency but would take up a tremendous amount of die area on the IO hub.
Either way, it sounds like the only NUMA scenario ROME will have is when going from one socket to another.
FreckledTrout - Monday, January 14, 2019 - link
You have a good point. I guess we wait for more details. Having share L3 would be crazy.