The Snapdragon 855 Performance Preview: Setting the Stage for Flagship Android 2019
by Andrei Frumusanu on January 15, 2019 8:00 AM EST- Posted in
- Mobile
- Qualcomm
- Smartphones
- SoCs
- 7nm
- Snapdragon 855

As we get ever closer to the releases of various Android vendor’s newest generation devices, Qualcomm continues its tradition of showcasing the performance of its newest generation SoC ahead of time, giving us a preview and a glimpse of what to expect of the upcoming commercial devices. This year, the company has shuffled the schedule around a bit, and instead of hosting the event at their San Diego headquarters, and we were able to get a hands-on with the Snapdragon 855 at CES before the show had started. Today we’re be looking in quite extensive detail on how exactly the new Snapdragon chipset performs, as well as shedding some light on some important unanswered technical questions on some aspects of the SoC.
It’s been roughly a little over a month now since Qualcomm officially announced the Snapdragon 855 in Hawaii, and we had posted extensive coverage on the event and the various announcements that took place:
Full Coverage
Day One
- Qualcomm Tech Summit, Day 1 Live Blog (Starts at 2pm ET)
- Qualcomm Tech Summit, Day 1: Announcing 5G Partnerships and Snapdragon 855
- The Verizon and AT&T 5G Setups at Qualcomm’s Snapdragon Summit
- 5G Mobile Hotspots: Netgear for AT&T and inseego for Verizon
- A Quick Look at Qualcomm’s 5G Smartphone Reference Design
- Implementing 5G in the UK: EE Trial Sites and First Cities
- Samsung’s 5G Smartphone Prototype: Don’t Mention The Notch
- Moto 5G Mod at Snapdragon Summit: Lots of Antennas, and S855 Inside?
Day Two
- Qualcomm Tech Summit, Day 2 Live Blog (Starts at 2pm ET)
- Qualcomm Tech Summit, Day 2: Snapdragon 855 Mobile Platform
- The Qualcomm Snapdragon 855 Pre-Dive: Going Into Detail on 2019's Flagship Android SoC
- OnePlus: Dual Product Lines, Cost of 5G, and Translation Errors
- Snapdragon 855 Power Consumption Demo, But
- Snapdragon 855: 802.11ax-Ready / Wi-Fi 6 Demonstrations
Day Three
- Qualcomm Tech Summit, Day 3 Live Blog (Starts at 2pm ET)
- Spotted: Qualcomm Snapdragon 8cx Wafer on 7nm
- Qualcomm Tech Summit, Day 3: Snapdragon 8cx, the New ACPC SoC
For anyone who might have missed it, if there’s any one specific article that I would recommend reading before heading in directly to the results of the benchmarking session, then it’s our in-depth piece summarising the disclosed specifications of the new Snapdragon 855.
SoC Overview & CPU Recap
| Qualcomm Snapdragon Flagship SoCs 2018-2019 | |||
| SoC |
Snapdragon 855 |
Snapdragon 845 | |
| CPU | 1x Kryo 485 Gold (A76 derivative) @ 2.84GHz 1x512KB pL2 3x Kryo 485 Gold (A76 derivative) @ 2.42GHz 3x256KB pL2 4x Kryo 485 Silver (A55 derivative) @ 1.80GHz 4x128KB pL2 2MB sL3 |
4x Kryo 385 Gold (A75 derivative) @ 2.8GHz 4x256KB pL2 4x Kryo 385 Silver (A55 derivative) @ 1.80GHz 4x128KB pL2 2MB sL3 |
|
| GPU | Adreno 640 @ ?MHz | Adreno 630 @ 710MHz | |
| Memory | 4x 16-bit CH @ 2133MHz LPDDR4x 34.1GB/s 3MB system level cache |
4x 16-bit CH @ 1866MHz LPDDR4x 29.9GB/s 3MB system level cache |
|
| ISP/Camera | Dual 14-bit Spectra 380 ISP 1x 48MP or 2x 22MP |
Dual 14-bit Spectra 280 ISP 1x 32MP or 2x 16MP |
|
| Encode/ Decode |
2160p60 10-bit H.265 HDR10, HDR10+, HLG 720p480 |
2160p60 10-bit H.265 720p480 |
|
| Integrated Modem | Snapdragon X24 LTE (Category 20) DL = 2000Mbps 7x20MHz CA, 256-QAM, 4x4 UL = 316Mbps 3x20MHz CA, 256-QAM |
Snapdragon X20 LTE (Category 18/13) DL = 1200Mbps 5x20MHz CA, 256-QAM, 4x4 UL = 150Mbps 2x20MHz CA, 64-QAM |
|
| Mfc. Process | 7nm (N7) | 10nm LPP | |
Summarising the Snapdragon 855 quickly, at the heart of the new 7nm chipset we find four new Kryo 485 CPUs based on Arm’s new Cortex A76 cores. The new CPU cores are derivatives of the designs Arm makes available by default: Here Qualcomm takes advantage of the “Built on Arm Cortex Technology” license which allows vendors to demand changes to the IP based on a set of microarchitectural tuneables that Arm makes available. Even though the Snapdragon 855’s Kryo 485 is the third generation of such a derivative core from Qualcomm, it represents the first instance of the company actually talking about what kind of microarchitectural changes have been made to the CPUs. The Kryo 485 Cortex A76 derivatives increase the re-order buffer from Arm’s default 128 entries to a higher, undisclosed figure. Qualcomm has also revealed that the prefetchers have been optimised for better efficiency, although again we don’t have any details on how exactly this has been achieved. Finally, as I’ve understood it, the branch data structures have also seen an improvement over the default A76 configuration.

Although the SoC still comes in a “4+4” big.LITTLE high-level core configuration, the big cores in the S855 aren’t actually all equal: Here Qualcomm has gone for a rather exotic 1+3+4 configuration, in which one of the big cores is implemented with a higher frequency physical design reaching 2857MHz, all while also employing a larger L2 cache of 512KB. The remaining three big cores max out at 2439MHz and are only equipped with 256KB L2 caches. Qualcomm does clock this 1+3 configuration differently with asynchronous clock planes, however the cores still share the same voltage plane. Here the company explains that this is a compromise between power efficiency benefits, and cost of implementation complexity as well as supporting power delivery components (Adding an extra voltage plane adds another PMIC rail with inductors & capacitors).
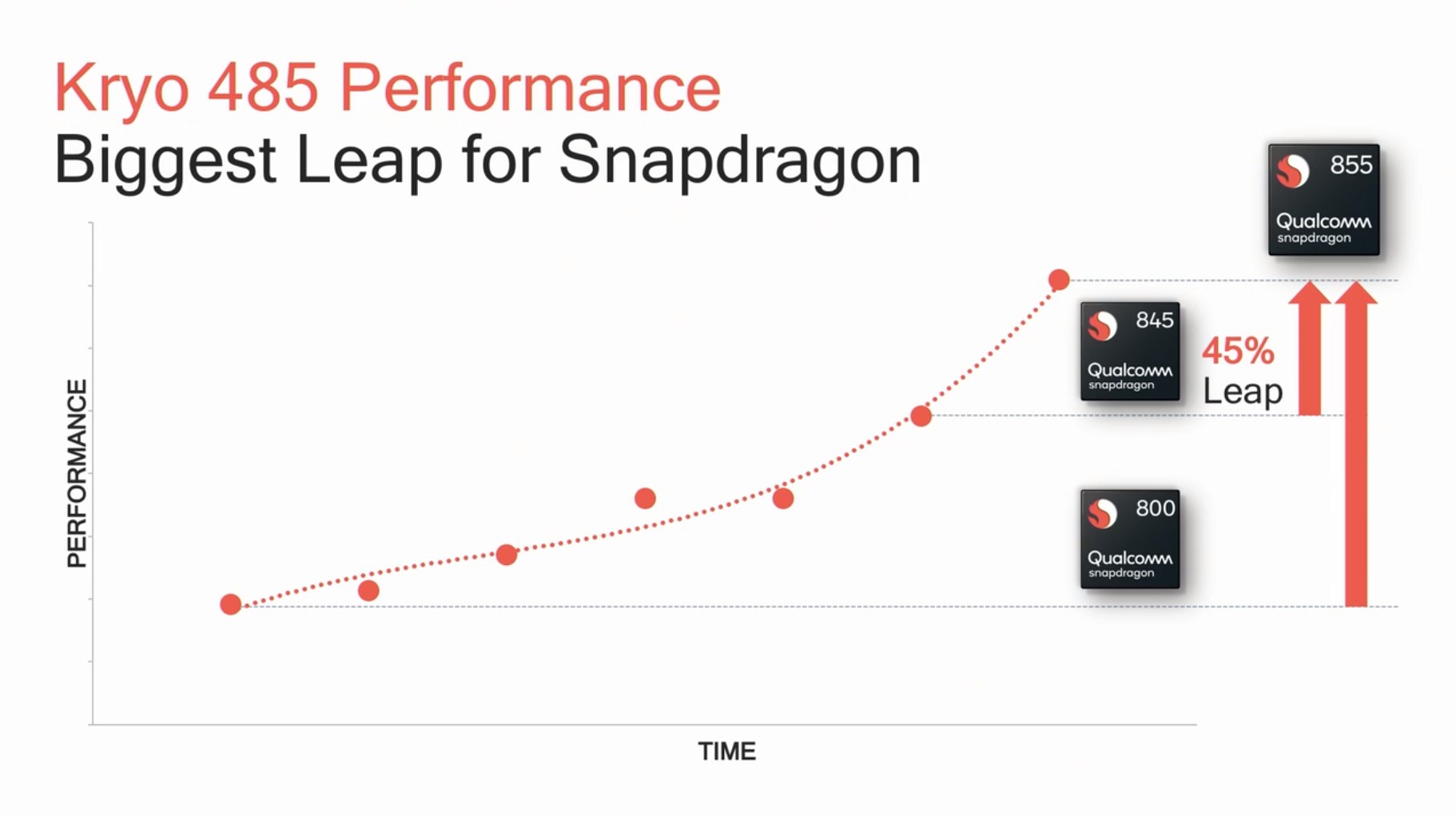
The Kryo 485 in the S855 promises to be Qualcomm’s biggest performance jump ever, advertising a 45% jump in performance compared to the Snapdragon 845. As we had discussed it in our launch article, this figure seems to coincide with the performance jump the Kirin 980 saw over the Snapdragon 845, which makes sense given that the two new SoCs both employ the newest generation A76 CPU at similar clocks.
The Snapdragon 855 QRD

Today’s testing platform is Qualcomm’s new Snapdragon 855 QRD (Qualcomm Reference Design). This year’s QRD design is probably Qualcomm’s most “commercial-device-like” ever as other than the more robustly built bezels, you would have a hard time noticing that this a reference platform – at least on the hardware side. The company stated that the QRD as tested should be a near representation of what to expect of commercial device – but of course vendors might still diverge from this as they may change the underlying software.
We’ve had a limited hands-on time with the devices, and although we managed to do a lot with them, some of the more time-intensive testing such as GPU sustained performance testing were out of the scope of today’s session.
The Big Question For The Snapdragon 855 : Memory Latency
One of the more odd developments that Qualcomm introduced with the Snapdragon 845 last year was the addition of a new 3MB system level cache that sits in front of the memory controllers as a new cache hierarchy. This new block is meant to serve as a SoC-wide buffer for the various IP blocks, reducing the amount of expensive DRAM memory accesses and thus improving power efficiency of the system. As well as improving power efficiency, it could in theory also serve as a booster for performance. The most famous use of such a system cache is Apple’s own A-series chips where we’ve seen this kind of IP block used ever since the A7.
Qualcomm’s introduction of such an IP block in the Snapdragon 845 was exciting to see, however this came as a double-edged sword as it had also introduced a 30% regression (In comparison to the Snapdragon 835) in DRAM memory latency, which may have limited some of the performance aspects of the A75-based CPU last year.
The new Snapdragon 855 unfortunately doesn’t seem to have made any major improvements in this regard as Qualcomm had confirmed that the IP block is the same as the one used in the Snapdragon 845.
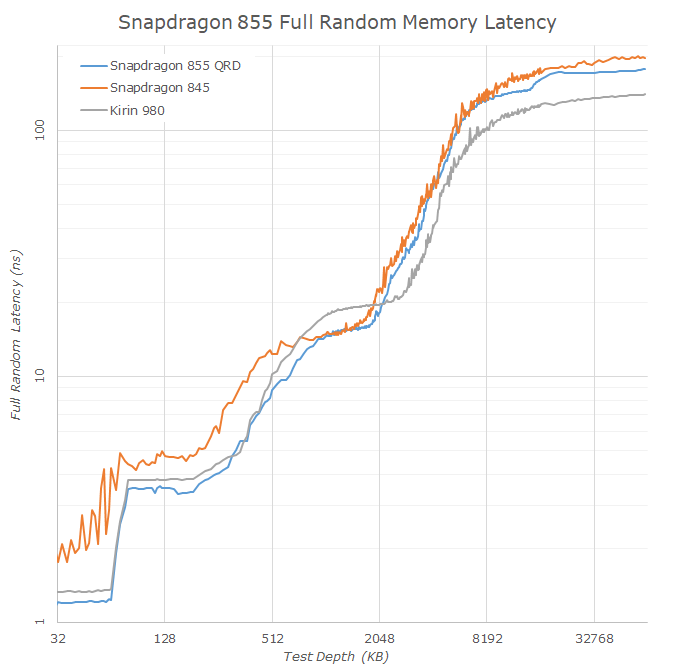
To investigate the differences between the Snapdragon 845, 855 and also the Kirin 980, we make use of latency test. First off, let’s view the memory hierarchy in a logarithmic latency graph, better visualising the various latency jumps between hierarchies:
Between the Snapdragon 845 and the new 855, we now see the increased L2 cache of the Kryo 485 Prime core at 512KB, an increase over the 256KB size on the previous generation performance core. What is also visible is that the L2 latency has improved, even though both chipsets are clocked near to each other at ~2.8GHz.
The DSU L3 cache on both the Snapdragon 845 and 855 are identical at 2MB in size: Again what’s interesting here to see is that the latency on this part of the cache hierarchy seems to be identical between both SoCs. This is in contrast to the 4MB L3 of the Kirin 980 which, albeit bigger, seems to be 20% slower.
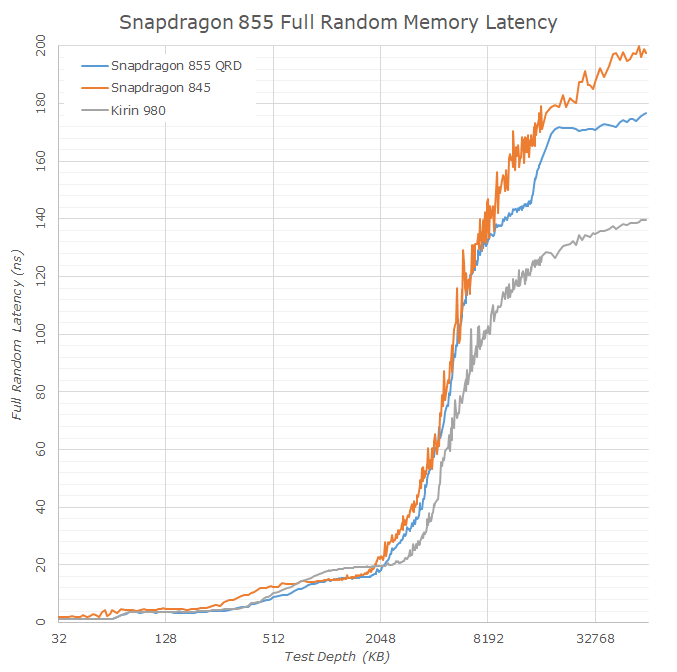
Moving onto the linear graph, here we can see the difference in DRAM latency in a clearer fashion. The Snapdragon 855 does seem to slightly improve memory latency over the 845, however this might just be an effect of the newer 2133MHz LPDDR4X memory that represents a 14% speed boost over the 1866MHz memory of last year’s devices.
Critically though, is the comparison to the Kirin 980 which employs the same CPU microarchitecture, and the same 2133MHz memory as the Snapdragon 855. Here Qualcomm still shows a notable latency regression in memory latency over the competition, whose effects will be interesting to analyse in the following pages.








132 Comments
View All Comments
goatfajitas - Tuesday, January 15, 2019 - link
What makes the Ax series so fast is the tight OS integration. It's a good chip, but not years ahead hardware-wise. What makes the whole thing so fast is the OS and how it's implemented. Either way good for Apple, but it's more SW than HWbji - Tuesday, January 15, 2019 - link
You tried to make this point before and failed. Give it up maybe?goatfajitas - Tuesday, January 15, 2019 - link
You may have failed to grasp it, but that is on you.Graag - Tuesday, January 15, 2019 - link
No, it's just blatantly wrong.tuxRoller - Wednesday, January 16, 2019 - link
Proof?sean8102 - Wednesday, January 16, 2019 - link
I don't buy that either. It's pretty well known Apple has some damn good chip designers in house. I'm no expert but one of the biggest things that stand out to me when comparing Apples designs is how much cache they use. The A12 has 128KB instruction and 128 KB data L1 cache and 8MB of L2 cache. It seems the 855 has basically ~2MB L2 cache (divided among each "cluster") and 2 MB of L3 cache. I haven't seen a Android avalible SOC that comes close the amount of cache that Apple puts on its SOC's which from what I understand is quite expensive to do, and results in a larger die size. But give large performance benefits. Of course that's only one example of something they do differently, considering that with a 2 high power plus 4 low power cores setup they are still so far ahead they must be making significant changes compared to the reference design they get from ARM.Their hardware team deserves serious credit for staying so far ahead for so long.
HStewart - Tuesday, January 15, 2019 - link
One big question I have always had with ARM based device especially in performance. - How does it compared with x86 platform except for power. This can be difficult to actually truly represent - especially with design difference in OS and applications.Application why a good example is running AutoCad - can even latest iPad Pro truly have performance of say latest quad or six core x86 based CPU and high end mobile GPU. I know Apple has iPad Pro version of Photoshop - but this is based on Photoshop CS and I personally like the earlier series - which I own CS 5.0
I think on ARM we long way from having a full version of Autocad, Solidworks, Lightwave 3d, 3dmax and others high end professional applications.
cpkennit83 - Tuesday, January 15, 2019 - link
A12/A12X devices compare very favorably with U series Intel chips, and smack Y series chips. Lack of software is not due to lack of power, but perceived demand.goatfajitas - Tuesday, January 15, 2019 - link
"A12/A12X devices compare very favorably with U series Intel chips" on selective tasks. It's a long way off from it in raw power.Wilco1 - Tuesday, January 15, 2019 - link
Benchmarks clearly show performance is about the same. In fact it looks like A12X is well ahead in terms of raw power, for example by 30% on compilation (LLVM test).