Investigating NVIDIA's Jetson AGX: A Look at Xavier and Its Carmel Cores
by Andrei Frumusanu on January 4, 2019 11:00 AM EST- Posted in
- NVIDIA
- SoCs
- Xavier
- Automotive
- Jetson
- Jetson AGX
Machine Inference Performance
The core aspects of the Xavier platform are its machine inferencing performance characteristics. The Volta GPU alongside the DLA core represent significant processing power in a compact and low-power platform.
To demonstrate the machine learning inference prowess of the system, NVIDIA provides the Jetson boards with a slew of software development kits as well as hand-tuned frameworks. The TensorRT framework in particular does a lot of heavy lifting for developers and represents the main API through which the GPU’s Tensor units as well as the DLA will be taken advantage of.
NVIDIA prepared a set of popular ML models for us to test out, and we’d be able to precisely configure the models in terms of how they were run on the platform. All the models running on the GPU and its Tensor core were able to run at either quantized INT8 forms, or in FP16 or FP32 forms. The batch sizes were also configurable, but we’ve kept it simple at just showcasing the results with a batch size of 32 images as NVIDIA claims this is the more representative use-case for autonomous machines.
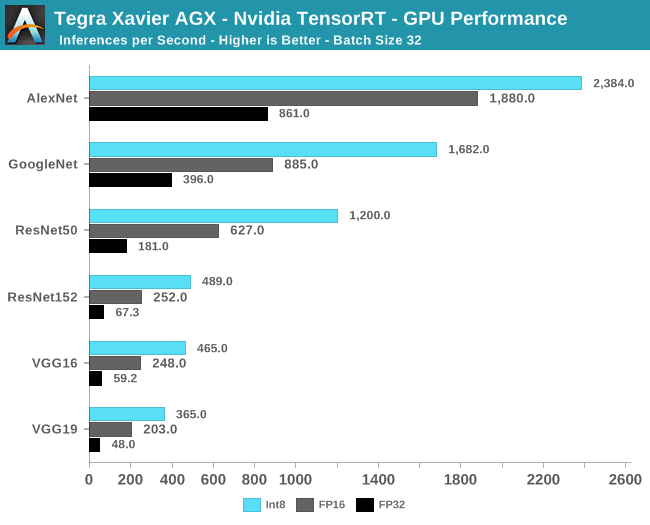
The results of the GPU benchmarks are a bit esoteric because we have few comparison points against which we can evaluate the performance of the AGX. Among the more clear results we see here is that the inferencing performance in absolute terms is reaching rather high rates, particularly in the INT8 and FP16 modes, representing sufficient performance to run a variety of inferencing tasks on a large number of input sets per second. The only real figure we can compare to anything in the mobile market is the VGG16 results compared to the AImark results in our most recent iPhone XS review, where Apple’s new NPU scored a performance of 39 inferences/second.
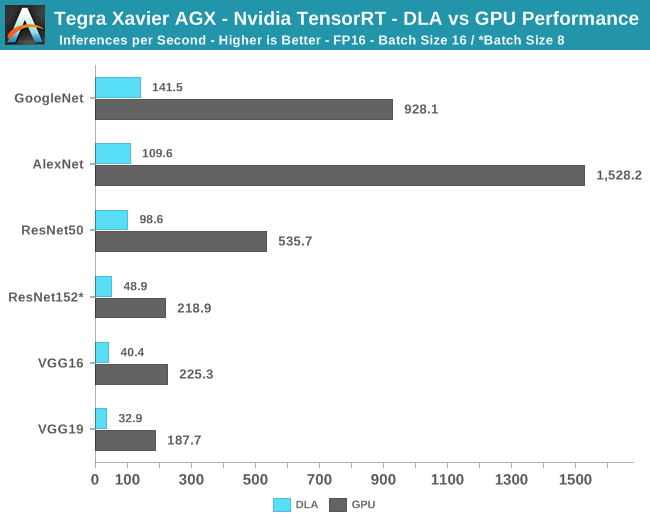
NVIDIA also made it possible to benchmark the DLA blocks, however this came with some caveats: The current version of the TensorRT framework was still a bit immature and thus doesn’t currently allow for running the models in INT8 mode, forcing us to resort to comparisons in FP16 mode. Furthermore I wasn’t able to run the tests with the same large batch size as on the GPU, so I’ve reverted to using smaller sizes of 16 and 8 where appropriate. Smaller batch sizes have more overhead as it takes proportionally longer time on the API side of things and less actual processing time on the hardware.
The performance of the DLA blocks at first glance seems a bit disappointing, as their performance is just a fraction of what the Volta GPU is able to showcase. However raw performance isn’t the main task of the DLA, it serves as a specialized offloading block which is able to operate at higher efficiency points than the GPU. Unfortunately, I wasn’t able to directly measure the power differences between the GPU and the DLA, as introducing my power measurement equipment into the DC power input of the board led to system instabilities, particularly during the current spikes when the benchmarks were launching their workloads. The GPU inference workloads did see the board power reach around ~45W while in its peak performance mode.
NVIDIA's VisionWorks Demos
All the talk about the machine vision and inferencing capabilities of the platform can be something that’s very hard to grasp if you don’t have a more intimate knowledge of the use-cases in the industry. Luckily, NVIDIA’s VisionWorks SDK comes with a slew of example demos and source code projects that one can use as a baseline for one’s commercial applications. Compiling the demos was a breeze as everything was set up for us on the review platform.
Alongside the demo videos, I also opted to showcase the power consumption of the Jetson AGX board. Here we’re measuring the power of the platform at the 19V DC power input with the board at its maximum unlimited performance mode. I had board’s own fan disabled (it can be annoyingly loud) and instead used an externally-powered 120mm bench fan blowing onto the kit. At a baseline power level, the board used ~8.7-9W while sitting idle and actively outputting to a 1080p screen via HDMI while also being connected to Gigabit Ethernet.
The first demo showcases the AGX’s feature tracking capabilities. The input source is a pre-recorded video to facilitate testing. While the video output was limited to 30fps, the algorithm was running in excess of 2-300fps. I did see quite a wide range of jitter in the algorithm fps, although this could be attributed to scheduling noise due to the low duration of the workload while in a limited FPS output mode. In terms of power, we see total system consumption hover around 14W, representing an active power increase of 5W above idle.
The second demo is an application of a Hough transform filter which serves as a feature extraction algorithm for further image analysis. Similarly to the first demo, the algorithm can run at a very high framerate on a single stream, but usually we’d expect a real use-case to use multiple input streams. Power consumption again is in the 14W range for the platform with an average active power of ~4.5W.
The motion estimation demo determines motion vectors of moving objects in a stream, a relatively straightforward use-case in automotive applications.
The fourth VisionWorks demo is the computational implementation of EIS (Electronic image stabilisation), were given an input video stream the system will crop out margins of the frame and use this space as the stabilisation window in which the resulting output stream will be able to elastically bounce against, reducing smaller juddery motions.
Finally, the most impressive demo which NVIDIA provided was the “DeepStream” demo. Here we see a total of 25 720p video input streams played back all simultaneously all while the system is performing basic object detection in every single one of them. This workload represented a much more realistic heavy use-case being able to take advantage of the processing power of the AGX module. As you might expect, power consumption of the board also rose dramatically, averaging around 40W (31W active work).








51 Comments
View All Comments
CheapSushi - Friday, January 4, 2019 - link
This is very minor but I'm surprised the ports/connectors aren't more secure on something meant to be in a car. I would expect cables to be screwed in like classic DVI or twist locked in or some other implementation. I feel like the vibration of the car, or even a minor accident, could loosen the cables. Or maybe I got the wrong impression from the kit.KateH - Friday, January 4, 2019 - link
afaik the generic breakout boards included in dev kits are just for the "dev" part- development and one-offs. a final design would probably use a custom breakout board with just the interfaces needed and in a more rugged form factor thats integrated into the product.mode_13h - Friday, January 4, 2019 - link
Would've loved to see a Denver2 (Tegra TX2) in that comparison. According to this, they're actually faster than Carmel:https://openbenchmarking.org/result/1809258-RA-180...
Note that the benchmark results named "TX2-6cores-enabled-gcc-5.4.0" refer to the fact that TX2 had the Denver2 cores disabled by default! Out of the box, it just ran everything on the quad-A57 cluster.
edatech - Saturday, January 5, 2019 - link
Same results also says TX2 is running with higher frequency (TX2 @ 2.04GHz while Jetson Xavier @ 1.19GHz), so not quite an apple to apple comparison.mode_13h - Saturday, January 5, 2019 - link
I'm not sure how much to read into that number. Would they really run the A57 and Denver2 cores at the same frequency? Is the Xavier figure really the boost, and not just the base clock?There's also this (newer) result:
https://openbenchmarking.org/result/1812170-SK-180...
Again, my point is that I wish the article had looked at Denver2. It sounds like an interesting, if mysterious core.
Jetson TX2 boards are still available - and at much lower prices than Xavier. So, it's still a worthwhile and relevant question how it compares - especially for those not needing Xavier's Volta and Tensor cores.
LinuxDevice - Monday, January 7, 2019 - link
It isn't so much that the cores are "disabled" (which to me would be something not intended to be turned on) as it is offering multiple power consumption profiles. The whole Jetson market started with the intent to offer it as an OEM reference board, but the reference boards were rather good all by themselves and ended up being a new market. The TX2 Denver cores are simple to turn off or on...but default is off.Xavier has something similar with the "nvpmodel" tool for switching around various profiles. To see full performance you need to first run "sudo nvpmodel -m 0", and the max out the clocks with the "~nvidia/jetson_clocks.sh" script.
SanX - Saturday, January 5, 2019 - link
Change the publisher asap. The most stupid and insulting ads you will find only at AT. Smells dirt and cheap. Yuck...I don't have such bad impression from YouTube for example, talk to Google guys.
TheJian - Sunday, January 6, 2019 - link
Double the gpu side at 7nm and throw it in an 100-250w box the size of an xbox/ps and I'm in for a new game console. Was hoping they'd re-enter mobile space with Intel/Qcom/samsung modem at 10 or 7nm since they can be included easily without the same watt issues before. NV doesn't need their own modem today (please come back, mobile gaming is getting great!). We need NV gpus in mobile :)Also, I refuse to buy old tech in your android tv system. Upgrade the soc, or no sale. COMPETE with msft/sony dang it! It's already a great streamer, but you need the gaming side UP and it needs to be a 150w+ box today or just another streamer (sonly msft are going 250w+ in their next versions probably) or why not just buy a $35-50 roku? Sure you can turn off most of it while streaming (or playing bluray), but power needs to be there for the gaming side. The soc is the only thing holding me back from AndroidTV box from NV for years now. I wanted 2 socs in it when it first launched, then they shrunk it and gave no more power. You're turning me off NV, you should be turning me ON...LOL. I have no desire for another msft/sony console, but I'd buy a HIGH WATT android model. None of this 15-25w crap is worth it. Roku take note too, as in add a gaming soc (call NV!) and gamepad support or no more sales to anyone in our family (we're going HTPC, because streamers suck as anything but streaming). We need multi-function at this point or you don't make it to our living room. HTPC fits everything I guess (thus we're building 3...LOL). Streaming, gaming, ripping, well, heck, EVERYTHING in one box with mass storage inside too. ShieldTV units will sell a LOT better (roku too) if you get better gaming in them. Angry birds alone doesn't count Roku!
A 7nm Tegra without all the crap for cars, etc, would be VERY potent. You have the money to make a great gaming box today. Move it into mobile (a single soc one of course) if the tech takes off by adding a modem. Either way, ShieldTV needs an soc upgrade ASAP. Not looking for RTX type stuff here, just a great general android gaming machine that streams. You have to start here to make a gaming PC on ARM stuff at some point. Use cheap machines to make the bigger ones once entrenched. Make sure it can take a discrete NV card at some point as an upgrade (see what I did there, selling more gpu cards, with no wintel needed). At some point it turns into a full PC :)
That said, I can’t wait for my first car that will drive me around while drinking ;) Designated drivers for all Oh and, our tests are completely invalidated by testing a 12nm vs. 10 & 7nm (and outputting with Ethernet hooked up), but but but….Look at our dumb benchmarks. Note also, cars want a MUCH longer cycle than pc’s or worse, mobile devices. These people don’t upgrade their soc yearly (more like 5-7 tops). So a box you plop in with most of the software done, is great for many car models. We are talking ~81-90mil sold yearly globally (depending on who you believe). Even 10mil of those at $100 a box would be a great add to your bottom line and I’m guessing they get far more than that, but you have to make a point at some price here ;) We are talking 1B even if it’s just $100 Net INCOME per box. That would move NV’s stock price for sure. Something tells me it’s 30%+ margins (I’d guess 50%+ really), but I could be wrong. Has anyone else done this job for less than $1500? Also note, as more countries raise incomes, more cars will be sold yearly.
https://www.statista.com/statistics/200002/interna...
Just as you see here, and the world still needs more cars (heck roads in some places still needed…LOL). Growth. There is room for more than one player clearly for years. Until L5 becomes a commodity there is good money to be had by multiple companies in this space IMHO. Oh and 35mil of those are cars are EU/USA (17.5ea for both). Again, much growth to come as more places get roads/cars, and how many of them have driverless so far? Not many.
At $1500 or under anyone can add this on to a car, as that is cheaper than the $7500 subsidy they have to add to an electric car just to even JOKE about making a dime on them right? And this would NOT be a subsidy. Electric cars are for the rich or stupid. I don’t remember voting for $7500 per car giveaways to make green people happy either! Please KILL THIS ASAP TRUMP! That is 1.5B per car maker (200K cars can be subsidized by each maker). I want a freaking WALL NOW not renewable subsidy crap for products that can’t make money on their own and I am UN-interested in completely as long as gas is available cheaper overall! Screw 5B, tell them $25B or the govt shuts down completely (still a joke, most stays open anyway) for your next 2yrs. Let them pound sand in discretionary spending. :) Only NON-ESSENTIAL people even go home. Well heck, why do I need a NON-essential employee anyway in govt? Let private sector take on all their crap, or just leave it state to state, where they are much better able to handle problems they are versed in.
“The one aspect which we can’t quantize NVIDIA’s Carmel cores is its features: This is a shipping CPU with ASIL-C functional safety features that we have in our hands today. The only competition in this regard would be Arm’s new Cortex A76AE, which we won’t see in silicon for at least another year or more.”
“the Carmel cores don’t position themselves too well.”
Er, uh, would you be saying that at 7nm vs. 7nm?? I’m guessing NV could amp the speeds a bit if they simply took the EXACT core and 7nm’d it right (a new verb?)? Can’t see a way forward? Nobody will have its safety features for a year in the segment it targets DIRECTLY, but you can’t see a way forward?...LOL. Never pass up a chance for an AMD portal site to knock NV. Pause for a sec, while I test it with my 2006 tests that well, aren’t even the target market…Jeez. Possibly make sense to go IN-HOUSE? So you’re saying on the one hand that there was NO OTHER CHOICE for a YEAR, but it’s only POSSIBLY a good idea they went in house? I think you mean, it was ONLY POSSIBLE to go in-house, and thus a BRILLIANT decision to go IN HOUSE, and I can see how this chip really goes FORWARD. There, fixed it. Intel keeps offering GPU designs, and they keep failing correct (adopting AMD tech even)? You go in house until someone beats you at your own game, just ask apple. No reason to give a middle man money unless he is soundly beating you, or you are not making profit as is.
So it’s really good at what it was designed to do, and is a plop in component for cars for ~$1000-1500 with software done pretty much for most? But NV has challenges going forward making money on it…LOL. Last I checked NV has most of the car market sewn up (er, signed up? Pays to be early in many things). Cars are kind of like Cuda. It took ~7yrs before that really took off, but look at it now. Owning everything else, and OpenCL isn’t even on the playing field as AMD can’t afford to FORCE it onto the field alone.
“But for companies looking to setup more complex systems requiring heavy vision processing, or actually deploying the AGX module in autonomous applications (no spellchecker before hitting the website?) for robotics or industrial uses, then Xavier looks quite interesting and is definitely a more approachable and open platform than what tends to exist from competing products.”
Translation: When you use it as it was designed, nobody has a competing offering…LOL. You could have just put the last P as the whole article and forgot the rest. Pencils work great as a writing tool, but when we try to run games on them, well, they kind of suck. I’m shocked. Pencils can’t run crysis? WTH?? I want my money back…LOL. Don’t the rest of the guys have the challenge, of trying to be MORE OPEN and APPROACHABLE? Your article is backwards. You have to dethrone the king, not the other way around. Where will NV be in a year when the competition finally gets something right? How entrenched will they be by then? Cars won’t switch on a dime like I will for my next vid card/cpu…LOL. They started this affair mid 2015 or so, and it will pay off 2021+ as everyone wants a autonomous cars on the road by then.
https://www.thestreet.com/investing/stocks/nvidia-...
https://finance.yahoo.com/news/nvidia-soars-ai-mar...
“we believe that the company is well poised to grow in the driverless vehicle technology space”
Arm makes under 500m (under 400 actually), NV makes how much (9x-10x this?)? Good luck. I do not believe off the shelf will beat a chip designed for auto, so someone will have to CUSTOM their way to victory over NV here IMHO.
https://www.forbes.com/sites/moorinsights/2018/09/...
BMW chose Intel, Tesla switches (and crashes, ½ a million sold so far?? Who cares), but I wonder for how long. I guess it depends on how much work they both want to do, or just plop in Nvidia solutions. I’ll also venture to guess Tesla did it merely to NOT be the same as Volvo, Toyota etc who went with NV. Can’t really claim your different using what everyone else uses. MOOR Insights isn’t wrong much. They have covered L2-L4 and even have built the chip to handle L5 (2 socs in Pegasus). How much further forward do you need to go? It seems they’re set for a bit, though I’m sure they won’t sit idle while everyone else catches up (they don’t have a history of that). TL:DR? It's a sunday morning, I had time and can type 60wpm...LOL.
gteichrow - Sunday, January 6, 2019 - link
FWIW and I know this has been discussed internally at your fine operation (no sarc): But pay option? I'd pay $1-$2/mo to be ad-free. I fully realize it's a PITA to manage that model. I already do this on Medium (barely, barely, barely worth it) and Patreon for others. The time is right, me thinks. Let's pick the Winners from the Losers and be done with it. You folks are in the winning camp, IMO.It almost goes without saying, but, you'all do a great job and thanks for all the work you folks do!
gteichrow - Sunday, January 6, 2019 - link
Sorry, but meant this to be in the comments below under the discussion about ads that had started. Oops. But thoughts still apply. Cheers.