Intel's 10nm Cannon Lake and Core i3-8121U Deep Dive Review
by Ian Cutress on January 25, 2019 10:30 AM ESTUncovering the Microarchitecture Secrets
When we approached Intel to see if they would disclose the full microarchitecture, just as usually do in the programming manuals for all the other microarchitectures they’ve released, the response was underwhelming. There is one technical document related to Cannon Lake I can’t access without a corporate NDA, which would be no use for an article like this. These documents usually fall under corporate NDA before the official launch, and eventually become public a short time after. However, when we requested the document, as well as details on the microarchitecture, we received a combination of ‘we’re not disclosing it at this time’ and ‘well tell us what you’ve found and we’ll tell you what is right’. That was less helpful than I anticipated.
As a result I pulled in a few helpful peers around the industry to try and crack this egg. Here’s what we think Cannon Lake looks like.
On the whole, the system is ultimately designed as a mix between the Skylake Desktop core and the Skylake-SP core from the enterprise world. While it has a standard Skylake design using a 4+1 decode and eight execution ports, along with a standard Skylake desktop L1+L2+L3 cache structure, it brings over a single AVX-512 port from the enterprise side as well as support for 2x512B/cycle read from the L1D cache and 1x512B/cycle write.
What we’ve ended up here is with a hybrid of the Skylake designs. To go even further, it’s also part of the way to a Sunny Cove core, Intel’s future second generation 10nm core design which the company disclosed part of in December. This is based on some of the instruction features not present in Skylake but found on both Cannon Lake and Sunny Cove.
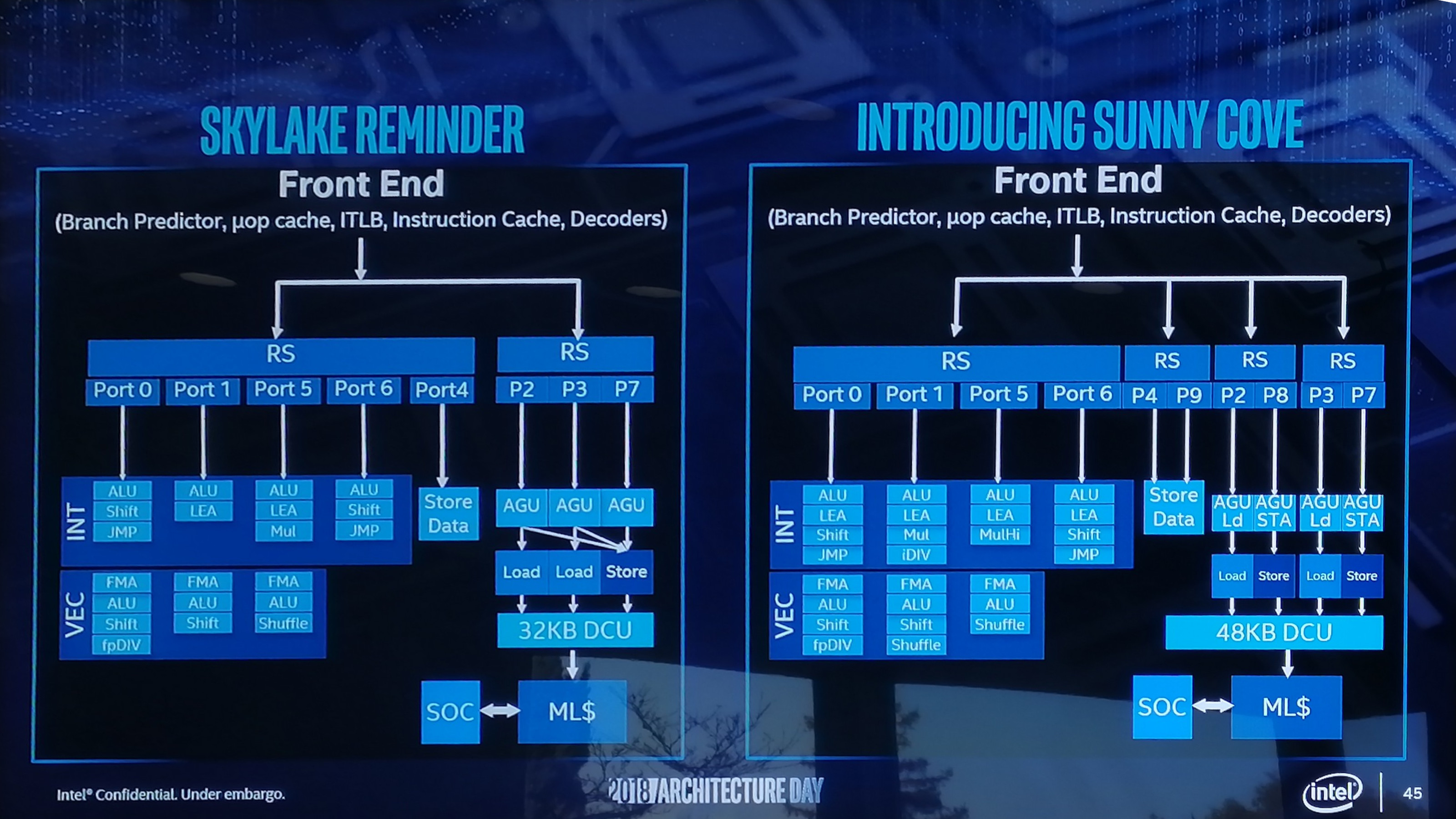
Mostly Column A, A Little of Column B
It’s mostly desktop Skylake at the end of the day – both Cannon Lake and Sunny Cove have the same AVX512 compatibility, just with the Skylake cache structure. We’re not too clear on most front end changes on Cannon Lake as those are difficult to measure, although we can tell that the re-order buffer size is the same as Skylake (224 uops). However, most of the features mentioned in the Sunny Cove announcement (doubling store bandwith, more execution ports, and capabilities per execution port) are not in Cannon Lake.
| Microarchitecture Comparison | ||||||
| Skylake Desktop |
Skylake Xeon |
Cannon Lake | Sunny Cove* | Ryzen | ||
| L1-D Cache |
32 KiB/core 8-way |
32 KiB/core 8-way |
32 KiB/core 8-way |
48 KiB/core ?-way |
64 KiB/core 4-way |
|
| L1-I Cache |
32 KiB/core 8-way |
32 KiB/core 8-way |
32 KiB/core 8-way |
? | 32 KiB/core 8-way |
|
| L2 Cache |
256 KiB/core 4-way |
1 MiB/core 16-way |
256 KiB/core 4-way |
256 KiB/core ?-way |
512 KiB/core 8-way |
|
| L3 Cache |
2 MiB/core 16-way |
1.375 MiB/core 11-way |
2 MiB/core 16-way |
? | 2 MiB/core | |
| L3 Cache Type | Inclusive | Non-Inclusive | Inclusive | ? | Non-Inclusive | |
| Decode | 4 + 1 | 4 + 1 | 4 + 1 | 5(?) + 1 | 4 | |
| uOP Cache | 1536 | 1536 | 1536 (?) | >1536 | ~2048 | |
| Reorder Buffer | 224 | 224 | 224 | ? | 192 | |
| Execution Ports | 8 | 8 | 8 | 10 | 10 | |
| AGUs | 2 + 1 | 2 + 1 | 2 + 1 | 2 + 2 | 2 | |
| AVX-512 | - | 2 x FMA | 1 x FMA | ? x FMA | - | |
| * Sunny Cove numbers for Client. Server will have different L2/L3 cache and FMA, like Skylake | ||||||
There are several parts to the story on Cannon Lake:
- New Instructions and AVX-512 Instruction Support
- Major Changes in Existing Instructions and Other Minor Changes
New Instructions and AVX-512 Instruction Support
The three new instructions supported on Cannon Lake are Integer Fused Multiply Add (IFMA), Vector Byte Manipulation Instructions (VBMI), and hardware based SHA (Secure Hash Algorithm) support. Intel has already stated that IFMA is supported on Ice Lake/Sunny Cove, although no word on VBMI. The hardware based SHA is already present in Goldmont, however our tests show the Goldmont version is actually better.
IFMA is a 52-bit Integer fused multiply add (FMA) behaves identically to AVX512 floating point FMA, offering a latency of four clocks and a throughput of two per clock (for xmm/ymm, zmm is four and one). This instruction is commonly listed as helping cryptographic functionality, but also means there is now added support for arbitrary precision arithmetic. Alexander Yee, the developer of the hyper optimized mathematical constant calculator y-cruncher, explained to be why IFMA helps his code when calculating constants like Pi:
The standard double-precision floating-point hardware in Intel CPUs has a very powerful multiplier that has been there since antiquity. But it couldn't be effectively tapped into because that multiplier was buried inside the floating-point unit. The SIMD integer multiply instructions only let you utilize up to 32x32 out of the 52x52 size of the double-precision multiply hardware with additional overhead needed. This inefficiency didn't go unnoticed, so people ranted about it, hence why we now have IFMA.
The main focus of research papers on this is that big number arithmetic that wants the largest integer multiplier possible. On x64 the largest multiplier was the 64 x 64 -> 128-bit scalar multiply instruction. This gives you (64*64 = 4096 bits) of work per cycle. With AVX512, the best you can do is eight 32 x 32 -> 64-bit multiply via the VPMULDQ instruction, which gets you (8 SIMD lanes * 32*32 * 2FMA = 16384 bits) of work per cycle. But in practice, it ends up being about half of that because you have the overhead of additions, shifts, and shuffles competing for the same execution ports.
With AVX512-IFMA, users can unleash the full power of the double-precision hardware. A low/high IFMA pair will get you (8 SIMD lanes * 52*52 = 21632 bits) of work. That's 21632/cycle with 2 FMAs or 10816/cycle with 1 FMA. But the fused addition and 12 "spare bits" allows the user to eliminate nearly all the overhead that is needed for the AVX512-only approach. Thus it is possible to achieve nearly the full 21632/cycle of efficiency with the right port configuration (CNL only has 1 FMA).
There's more to the IFMA arbitrary precision arithmetic than just the largest multiplier possible. RSA encryption is probably one of the only applications that will get the full benefit of the IFMA as described above. y-cruncher benefits partially. Prime95 will not benefit at all.
For the algorithms that can take advantage of it, this boils down to the following table:
| IFMA Performance | |||
| Scalar x64 | AVX512-F | AVX512-IFMA | |
| Single 512b FMA | 4096-bit/cycle | ~4000-bit/cycle | 10816-bit/cycle |
| Dual 512b FMA | 4096-bit/cycle | ~8000-bit/cycle | 21632-bit/cycle |
VBMI is useful in byte shuffling scenarios, offering several instructions:
| VBMI Intructions | |||
| Description | Latency | Throughput | |
| VPERMB | 64-byte any-to-any shuffle | 3 clocks | 1 per clock |
| VPERMI2B | 128-byte any-to-any overwriting indexes |
5 clocks | 1 per 2 clocks |
| VPERMT2B | 128-byte any-to-any overwriting tables |
5 clocks | 1 per 2 clocks |
| VPMULTISHIFTQB | Base64 conversion | 3 clocks | 1 per clock |
Alex says that y-cruncher could benefit from VBMI, however it is one of those things he has to test with hardware on hand rather than on an emulator. Intel hasn’t specified if the Sunny Cove core supports VBMI, which would be an interesting omission.
For hardware accelerated SHA, this is designed purely to accelerate cryptography. However our tools show that the Cannon Lake implementation is slower than both Ryzen and Goldmont, which means it isn’t particularly useful. Cannon Lake also supports Vector-AES, which allows AES instructions to use more of the AVX-512 unit at once, multiplying throughput. Intel has stated that Sunny Cove has implemented SHA and SHA-NI instructions, along with Galois Field instructions and Vector-AES, although to what extent we do not know.
Changes in Existing Instructions
Most generations, Intel will add additional logic to improve the instructions already in place, typically for increasing throughput or decreasing latency (or both).
The big change here is with 64-bit integer divisions now being hardware supported, rather than split into several instructions. Divisions are time consuming at the best of times, however implementing a hardware radix divider means that Cannon Lake can complete at 64-bit IDIV in 18 clocks, compared to 45 on Ryzen and 97 on Skylake. This adjustment is also in the second generation 10nm Sunny Cove core.
For block storage of strings, all of the REP STOS* series of instructions can now use the 512-bit execution write port, allowing a throughput of 61 bits per clock, compared to 43 on Skylake-SP, 31 on Skylake, and 14 on Ryzen.
The AVX512BW command VPERMW, for permuting word integer vectors, has decreased in latency from six clocks to four clocks, and doubled throughput to one per clock compared to one per two clocks. Similarly with vectors, moving or merging vectors of single or double precision scalars using VMOVSS and VMOVSD commands now behaves identically to other MOV commands. This is also present in Sunny Cove.
Other beneficial adjustments to the instruction set include making ZMM divisions and square roots one clock faster, and increasing throughput of some GATHER functions from one per four clocks to one per three clocks.
Regressions come in the form of old x87 commands, with x87 DIV, SQRT, REP CMPS, LFENCE, and MFENCE all being one clock slower. Other x87 transcendentals are many clocks slower, with the goal of deprecation.
There other points to mention:
The VPCONFLICT* commands, which had a latency of 3 clocks and a throughput of one per clock are still slow on Cannon Lake, with the DWORD ZMM form having a latency of 26 clocks and a throughput of one per 20 clocks. This change has not made its way across platforms as of yet.
The cache line write back function, CLWB, was introduced in Skylake-SP to help assist with persistent memory support. It writes back modified data of a cache line, but avoids invalidating the line from the cache (and instead transitions the line to non-modified state). CLWB attempts to minimize the compulsory cache miss if the same data is accessed temporally after the line is flushed if the same data is accessed temporally after the line is flushed. The idea is that this instruction will help with Optane Persistent DC Memory and databases, hence its inclusion in SKL-SP, however it is not in Cannon Lake. Intel’s own documents suggest it will be a feature in Sunny Cove.
There is also no Software Guard Extension (SGX) support on Cannon Lake.








129 Comments
View All Comments
KOneJ - Sunday, January 27, 2019 - link
Bingo.Spunjji - Tuesday, January 29, 2019 - link
Truly magnificent.KateH - Saturday, January 26, 2019 - link
but please, if OP is interested in taking a whack at "articulating" i'd love to see what that looks like and how my translation faredMidwayman - Friday, January 25, 2019 - link
Interesing. So Basically no real possibility for desktop improvement until 2020 at least. They really are giving AMD a huge window to take the performance crown. Zen 2 is due to ship this year, right?BigMamaInHouse - Friday, January 25, 2019 - link
And dont forget- there are many Dual/Quad core (lets Say from Q6600 ~SandyBridge to 7700K ) Intel PC's that gonna be upgraded finally with new Ryzen launch and those PC won't we upgraded for another 3+ Years,DanNeely - Sunday, January 27, 2019 - link
The lower end of that range has been upgrading for years. The upper end has no real reason to upgrade unless they're doing something other than gaming, since current games don't benefit from the higher core counts much.I'm in the middle with a 4790K; and still see myself on track for a nominal 2022 upgrade; short of games growing CPU demands significantly or unexpected hardware failures I don't see any need to bring it forward. The additional cores will be nice for future proofing; but what I'm mostly looking forward to is all the stuff outside the CPU.
My notional want list is 10GB ethernet, PCIe4(5?) to the GPU and SSD, 50/50 USB 3.x A/C mix, and DDR5. The first of these is starting to show up on halo priced mobos.
PCIe4 is rumored to be launching this year on AMD, although from the leaks so far it's not clear if it'll only reach the first x16 slot for the GPU or be more widely available (maximum trace lengths are short enough that anything other than M.2 on a not-dimm will probably need signal boosters increasing costs).
Dual USB-C is starting to show up on a few boards; but widerspread availability is likely to be blocked until the hardware to handle flipping the connector moves from a separate chip into the chipset itself.
DDR5 is supposed to start shipping in very limited quantities this year, but will be another year or two before reaching consumer devices.
My guess is late 2020/early 2021 before all the hardware I want is finally available; which fits well with the nominal 8y lifespan I'm targeting for my systems core components.
shadowx360 - Friday, February 1, 2019 - link
What is the point of DDR5? It's going to be beyond overpriced at launch for negligible performance gain. As for USB-C, you can find cases with front connectors.Gondalf - Friday, January 25, 2019 - link
Ask to TSMC, we have not any real date of shipment. Moreover we don't know how the new SKUs will perform.eastcoast_pete - Saturday, January 26, 2019 - link
I don't think TSMC would give anybody except their customer (AMD) an expected shipping date. Also, while we don't know how the new AMD processors will perform, we already know that I Intel's 10 nm tech was both late and hasn't performed so we'll. BTW, I am currently running all PCs around me on Intel chips, so no fanboy here. This disappointing 10 nm fiasco is bad for all of us, as we need Intel to egg on AMD and vice versa. If one of them drops behind, the other one gets lazy.eastcoast_pete - Saturday, January 26, 2019 - link
Damn autocorrect and no edit!