The iPhone XS & XS Max Review: Unveiling the Silicon Secrets
by Andrei Frumusanu on October 5, 2018 8:00 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- iPhone XS
- iPhone XS Max
The A12 Tempest CPU µarch: A Fierce Small Core
Apple had first introduced a “small” CPU core alongside the Twister cores in the A10 SoC, powering the iPhone 7 generation. We’ve never really had the opportunity to dissect these cores, and over the years there was a bit of mystery around them as to what they’re capable of.
Apple’s introduction of a heterogeneous CPU topology in one sense was one of the biggest validations for Arm designs. Having separate low(er)-power CPUs on a SoC is a simple matter of physics: It’s just not possible to have bigger microarchitectures scale down power as efficiently as if you would just use a separate smaller block. Even in a mythical perfectly clock-gated microarchitecture, you would not be able to combat the static leakage present in bigger CPU cores, and thus this would come with the negative consequence of being part of the everyday power consumption on a device, even for small workloads. Power gating the big CPU cores, and instead shifting to much smaller CPU in contrast, helps alleviate static leakage, as well as (if designed as such) improving the dynamic leakage power efficiency.
The Tempest cores in the A12 are now the third iteration of this “small” microarchitecture, and since the A11 they are now fully heterogeneous and work independently of the big cores. But the question is, is this actually the third iteration, or did Apple do something more interesting?
The Tempest core is a 3-wide out-of-order microarchitecture: Already out of the gate this means it has very little to do with Arm’s own “little” cores, such as the A53 and A55, as these are simpler in-order designs.
The Tempest core’s execution pipelines are also relatively few: There are just two main pipelines that are capable of simple ALU operations; meanwhile one of them also does integer and FP multiplications, and the other is able to do FP additions. Essentially we just have two primary execution ports to each of the more complex pipelines behind them. Meanwhile in addition to the two main pipelines, there’s also a dedicated combined load/store port.
Now what is very interesting here is that this essentially looks identical to Apple’s Swift microarchitecture from Apple's A6 SoC. It’s not very hard to imagine that Apple would have recycled this design, ported it to 64-bit, and they now use it as a lean out-of-order machine serving as the lower power CPU core. If this is indeed Swift derived, then on top of the three execution ports described above, we should also find a dedicated port for integer and fp divisions, such as not to block the main pipelines whenever such an instruction is fed.
The Tempest cores clock up to a maximum of 1587MHz and are served by 32KB instruction and data caches, as well as an increased shared 2MB L2 cache that uses power management to partially power down SRAM banks.
In terms of power efficiency, the Tempest cores were essentially my prime candidate to try to get to some sort of apples-to-apples comparison between the A11 and A12 for power efficiency. I haven’t seen major differences in the cores besides the bigger L2, and Apple has also kept the frequencies similar. Unfortunately, "similar" isn't identical in this case; because the small cores on the A11 can boost up to 1694MHz when there’s only one thread active on them, I had no really good way to also measure performance at iso-frequency.
I did run SPEC at an equal 1587MHz frequency by simply having a second dummy thread spinning on another core while the main workloads were benchmarking. And I did try to get some power figures through this method by regression testing the impact of the dummy thread. However the power was near identical to the figures I measured at 1694MHz. As a result I dropped the idea, and we'll just have to just keep in mind that the A11’s Mistal cores were running 6.7% faster in the following benchmarks:
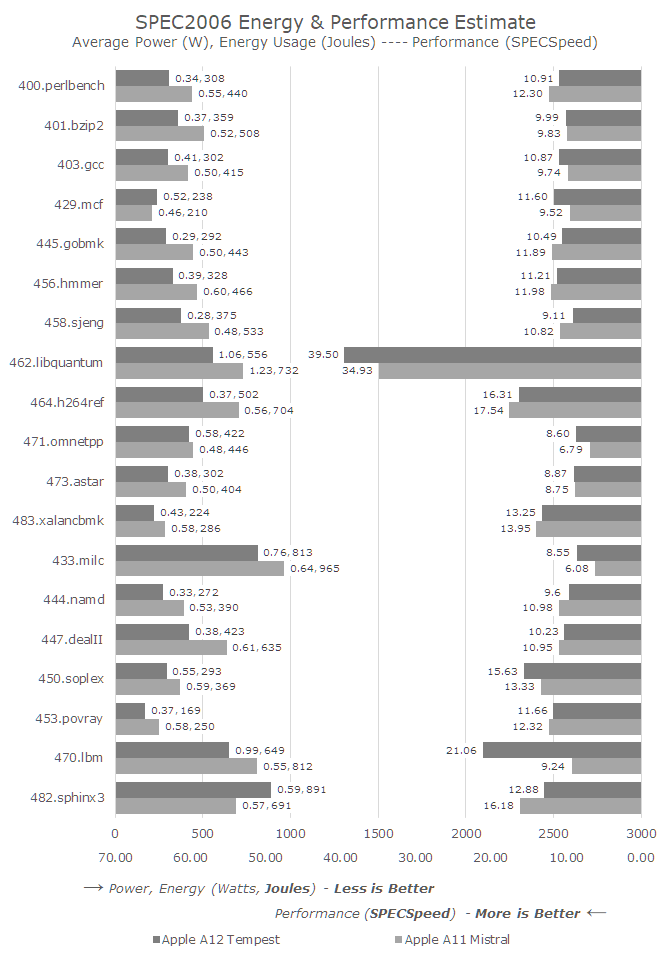
Much like on the Vortex big cores, the biggest improvements for the new Tempest cores are found in the memory-sensitive benchmarks. The benchmarks in which Tempest loses to Mistral are mainly execution bound, and because of the frequency disadvantage, there’s no surprise that the A12 lost in this particular single-threaded small core scenario.
Overall, besides the memory improvements, the new Tempest cores looks very similar in performance to last year’s Mistral cores. This is great as we can also investigate the power efficiency, and maybe learn something more concrete about the advantages of TSMC's 7nm manufacturing process.
Unfortunately, the energy efficiency improvements are somewhat inconclusive, and more so maybe disappointing. Looking at the SPECint2006 workloads overall, the Tempest-powered A12 was 35% more energy efficient than the Mistral-powered A11. Because the Mistral cores were running at a higher frequency in this test, the actual efficiency gains for A12 would likely be even less at an ISO-frequency level. Granted, we’re still looking at a general ISO-performance comparison here, as the memory improvements in A12 were able to push the Tempest cores to an integer suite score nearly identical to the higher-clocked Mistral cores.
In the overall FP benchmarks, Tempest was only 17% more efficient, even though it did perform better than the A11’s Mistral cores.
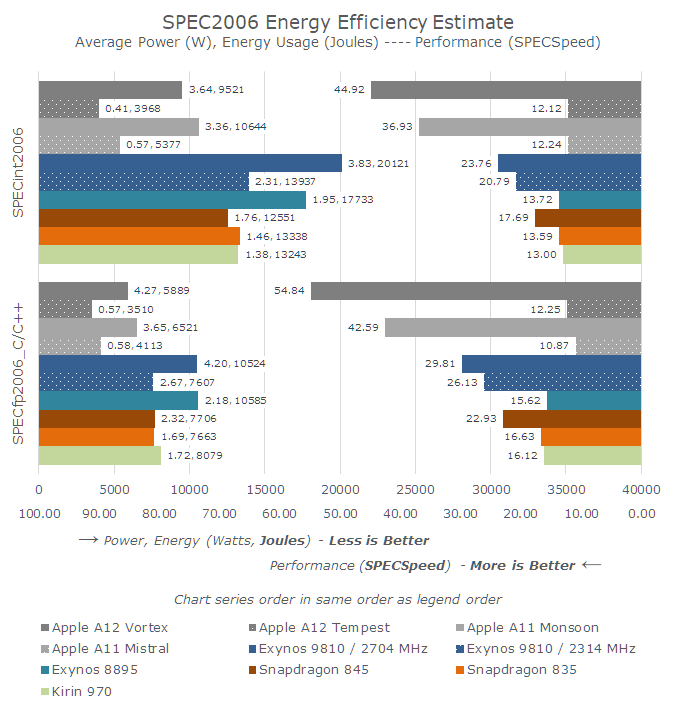
Putting the A11 and A12 small cores in comparison with their big brothers as well as the competition from Arm, there’s not much surprise in terms of the results. Compared to the big Apple cores, the small cores only offer a third to a fourth of the performance, but they also use less than half the energy.
What did surprise me a lot was seeing just how well Apple’s small cores compare to Arm’s Cortex-A73 under SPECint. Here Apple’s small cores almost match the performance of Arm’s high-performance cores from ust 2 years ago. In SPEC's integer workloads, A12 Tempest is nearly equivalent to a 2.1GHz A73.
However in the SPECfp workloads, the small cores aren’t competitive. Not having dedicated floating-point execution resources puts the cores at a disadvantage, though they still offer great energy efficiency.
Apple’s small cores in general are a lot more performant that one would think. I’ve gathered some incomplete SPEC numbers on Arm’s A55 (it takes ages!) and in general the performance difference here is 2-3x depending on the benchmark. In recent years I’ve felt that Arm’s little core performance range has become insufficient in many workloads, and this may also be why we’re going to see a lot more three-tiered SoCs (such as the Kirin 980) in the coming future. As it stands, the gap between the maximum performance of the little cores and the most efficient low performance point of the big continues to grow into one direction. All of which makes me wonder whether it’s still worth it to stay with an in-order microarchitecture for Arm's efficiency cores.
Neural Network Inferencing Performance on the A12
Another big, mysterious aspect of the new A12 was the SoC's new neural engine, which Apple advertises as designed in-house. As you may have noticed in the die shot, it’s a quite big silicon block, very much equaling the two big Vortex CPU cores in size.
To my surprise, I found out that Master Lu’s AImark benchmark also supports iOS, and better still it uses Apple's CoreML framework to accelerate the same inference models as on Android. I ran the benchmark on the latest iPhone generations, as well as a few key Android devices.
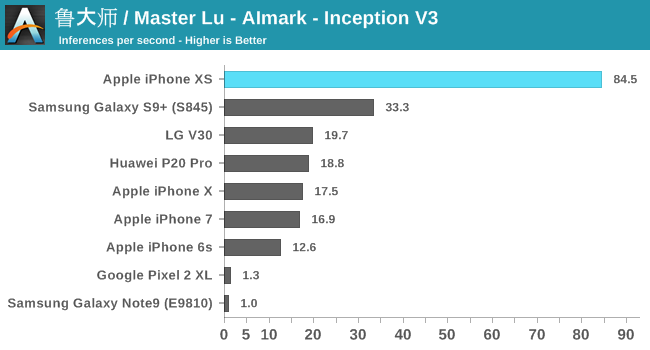
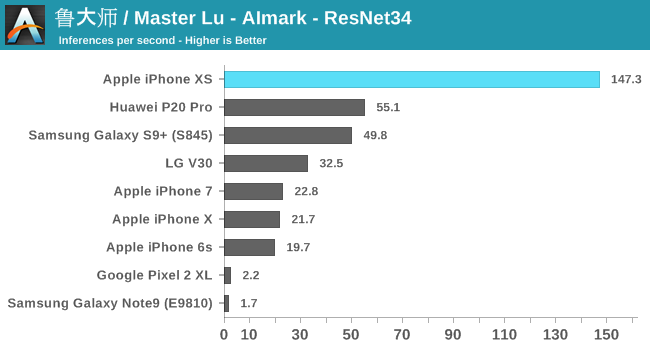
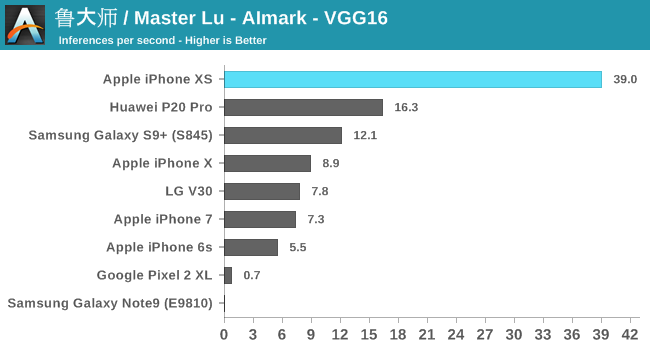
Overall, Apple’s 8x performance claims weren’t quite confirmed in this particular test suite, but we see solid improvements of 4-6.5x. There’s one catch here in regards to the older iPhones: as you can see in the results, the A11-based iPhone X performs quite similarly to previous generation phones. What’s happening here is that Apple’s executing CoreML on the GPU. It seems to me that the NPU in the A11 might have never been exposed publicly via APIs.
The Huawei P20 Pro’s Kirin 970 falls roughly 2.5x behind the new A12 – which coincidentally exactly matches the advertised 2TOPs vs 5TOPs throughout capabilities of both SoC’s respective NPUs. Here the new Kirin 980 should be able to significantly close the gap.
Qualcomm’s Snapdragon 845 also performs very well, trading blows with the Kirin 970. AImark uses the SNPE framework for inference acceleration, as it doesn’t support the NNAPI as of yet. The Pixel 2 and Note9 offered terrible results here as they both had to fall back to CPU accelerated libraries.
In terms of power, I’m not too comfortable publishing power on the A12 because of how the workload was visibly transactional: The actual inferencing workload bumped up power consumption up to 5.5W, with lower gaps in-between. Without actually knowing what is happening in-between the bursts of activity, the average power figures for the whole test run can vary greatly. Nevertheless, the fact that Apple’s willing to go up to 5.5W means that they’re very much pushing the power envelope here and going for the highest burst performance. The GPU-accelerated iPhone’s power peaked in the 2.3W to 5W range depending on the inference model.








253 Comments
View All Comments
Constructor - Monday, October 8, 2018 - link
I don't see that happening at all because Apple has explicitly maintained a clear distinction between Macs and iOS exactly along the lines of different interaction paradigms (point-based vs. touch).Windows with touch continues to be a mess and I don't see Apple following Microsoft into that dead end.
Constructor - Monday, October 8, 2018 - link
If they'd have a replacement offering noticeably higher performance than any Intel Mac Pro and if legacy software at least ran decently until new ARM recompiles were available, I don't think most users would mind all that much.Going from PowerMacs to Mac Pros was also not entirely painless, but most users still thought it was worth it overall.
id4andrei - Sunday, October 7, 2018 - link
Andrei, I remember you mentioning in the comment sections of an article - maybe the S9 review - that the A11 cannot maintain it's freq and drops by as much as 40% while the Snapdragon drops only 10% on sustained workloads.You made your testing on a bench fan. You tested the potential of the A12, and it is incredible, but not the real life performance of the iphone. When used for prolonged sessions the A12 might reach its threshold faster than the Snapdragon and drop performance. What are your musings on this? Throttling matters and identifying it is very important, especially considering Apple's recent history. The CPU is great but is that top performance sustainable and for how long?
Andrei Frumusanu - Sunday, October 7, 2018 - link
What you mention is in regards to the GPU performance, it's addressed in that section in this piece.And of course it's the real performance of a phone. The duration of a benchmark doesn't change the fact that the CPU is capable of that throughput. Real world workloads are transactional and are a few seconds at best in the majority of use-cases. In such scenarios, the performance is well exhibited.
id4andrei - Sunday, October 7, 2018 - link
That makes perfect sense. No one does folding on smartphones. Thanks for the prompt reply.eastcoast_pete - Sunday, October 7, 2018 - link
Also, folding your smartphone is really hard, and doesn't end well for the phone (:FunBunny2 - Sunday, October 7, 2018 - link
"folding your smartphone is really hard, and doesn't end well for the phone"I don't recall (too lazy to confirm :) ) which company, but a patent was awarded a couple or so years ago for a flexible display, such that it would (according to the drawing I saw) make a cylindrical bend the hinge when closed. still hasn't appeared, so far as I know. let's see... looks like Samsung and LG have some, and more recently than when I first saw..
here: https://www.androidauthority.com/lg-foldable-phone...
eastcoast_pete - Monday, October 8, 2018 - link
Yes, that comment was in jest. I believe both Samsung, LG and Huawei have folding smartphones with folding screens underdevelopment. If those work out and aren't too pricey, I'd be interested. Nice to be able to fold a phone with a 7 inch display to a little more then half its full size.varase - Tuesday, October 23, 2018 - link
While this would probably be neat to see in the short run, I can't imagine that would yield a long lasting display over the long haul.Javert89 - Sunday, October 7, 2018 - link
Hi, do you think the current power draw of the CPU (in watt) is sustainable for the battery, expecially in the long term? In this review you cite a case where a GPU benchmark made crash the phone because the power required is too high.. Any chance to see this behavior on real life scenario? Moreover do you think that the power draw (watt) is sustainable in smartphone envelope? Or other aspects like overall power consumption or leakage count?