The NVIDIA GeForce RTX 2080 Ti & RTX 2080 Founders Edition Review: Foundations For A Ray Traced Future
by Nate Oh on September 19, 2018 5:15 PM EST- Posted in
- GPUs
- Raytrace
- GeForce
- NVIDIA
- DirectX Raytracing
- Turing
- GeForce RTX
The RTX Recap: A Brief Overview of the Turing RTX Platform
Overall, NVIDIA’s grand vision for real-time, hybridized raytracing graphics means that they needed to make significant architectural investments into future GPUs. The very nature of the operations required for ray tracing means that they don’t map to traditional SIMT execution especially well, and while this doesn’t preclude GPU raytracing via traditional GPU compute, it does end up doing so relatively inefficiently. Which means that of the many architectural changes in Turing, a lot of them have gone into solving the raytracing problem – some of which exclusively so.
To that end, on the ray tracing front Turing introduces two new kinds of hardware units that were not present on its Pascal predecessor: RT cores and Tensor cores. The former is pretty much exactly what the name says on the tin, with RT cores accelerating the process of tracing rays, and all the new algorithms involved in that. Meanwhile the tensor cores are technically not related to the raytracing process itself, however they play a key part in making raytracing rendering viable, along with powering some other features being rolled out with the GeForce RTX series.
Starting with the RT cores, these are perhaps NVIDIA’s biggest innovation – efficient raytracing is a legitimately hard problem – however for that reason they’re also the piece of the puzzle that NVIDIA likes talking about the least. The company isn’t being entirely mum, thankfully. But we really only have a high level overview of what they do, with the secret sauce being very much secret. How NVIDIA ever solved the coherence problems that dog normal raytracing methods, they aren’t saying.
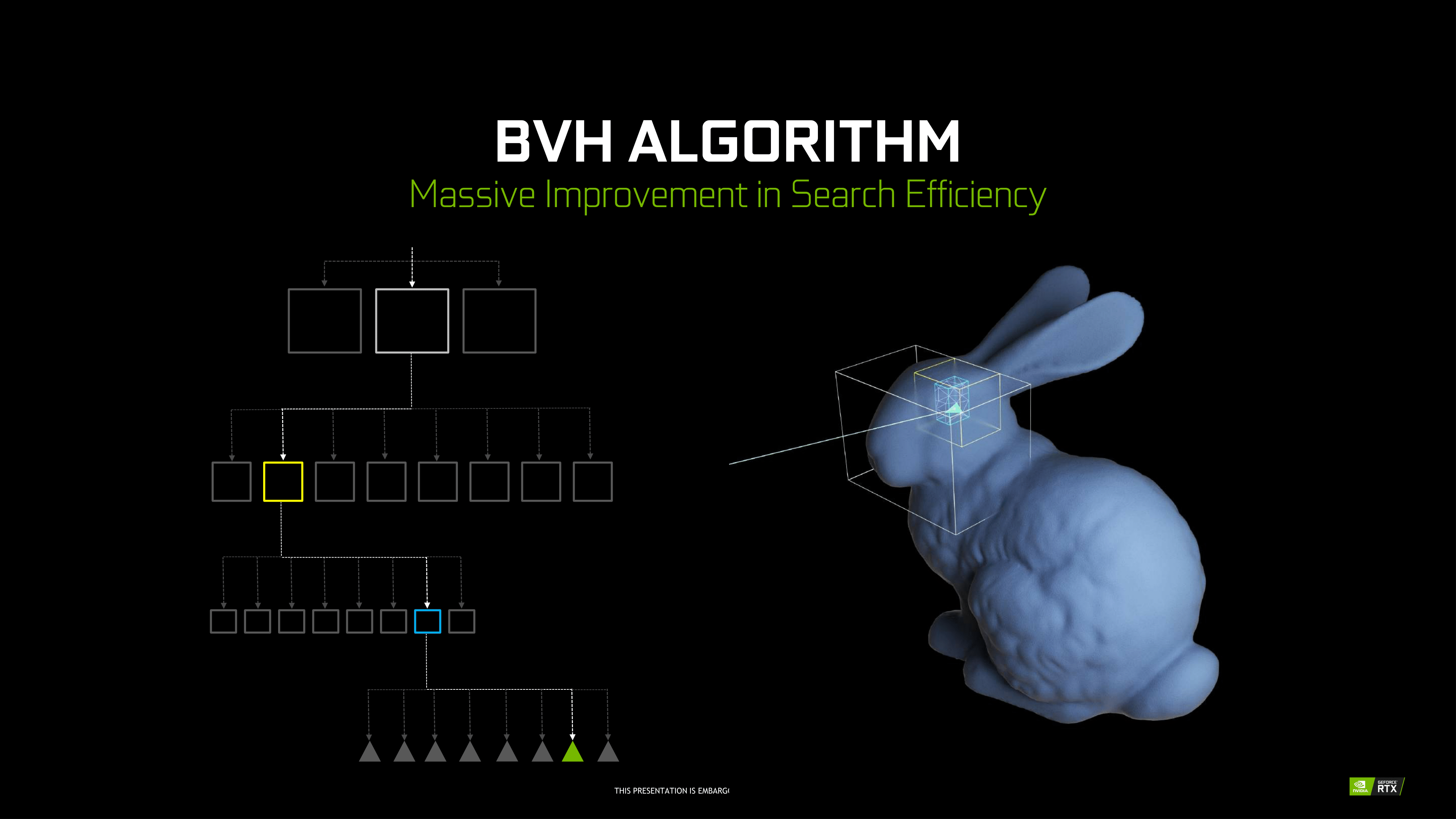
At a high level then, the RT cores can essentially be considered a fixed-function block that is designed specifically to accelerate Bounding Volume Hierarchy (BVH) searches. BVH is a tree-like structure used to store polygon information for raytracing, and it’s used here because it’s an innately efficient means of testing ray intersection. Specifically, by continuously subdividing a scene through ever-smaller bounding boxes, it becomes possible to identify the polygon(s) a ray intersects with in only a fraction of the time it would take to otherwise test all polygons.
NVIDIA’s RT cores then implement a hyper-optimized version of this process. What precisely that entails is NVIDIA’s secret sauce – in particular the how NVIDIA came to determine the best BVH variation for hardware acceleration – but in the end the RT cores are designed very specifically to accelerate this process. The end product is a collection of two distinct hardware blocks that constantly iterate through bounding box or polygon checks respectively to test intersection, to the tune of billions of rays per second and many times that number in individual tests. All told, NVIDIA claims that the fastest Turing parts, based on the TU102 GPU, can handle upwards of 10 billion ray intersections per second (10 GigaRays/second), ten-times what Pascal can do if it follows the same process using its shaders.

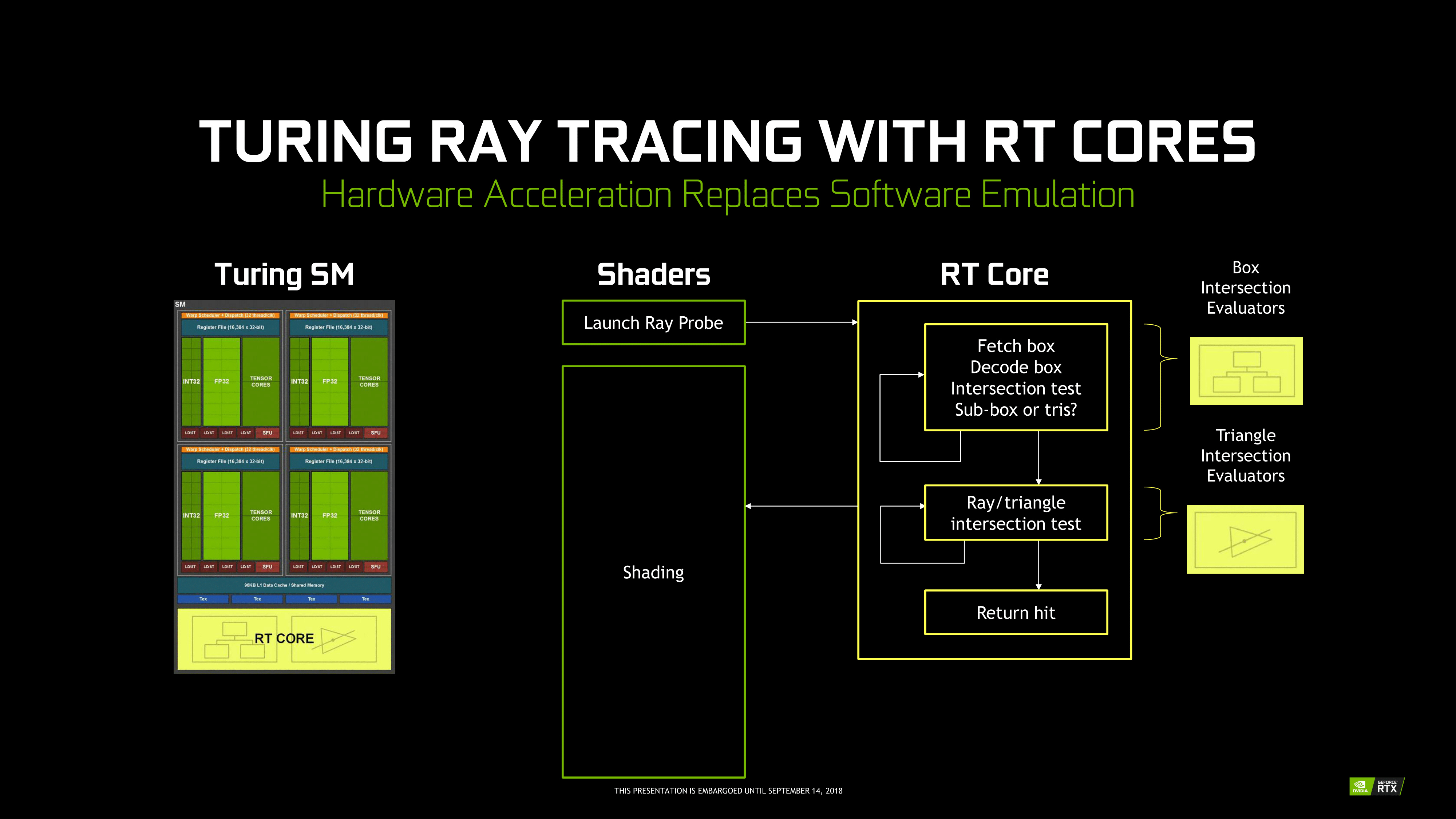
NVIDIA has not disclosed the size of an individual RT core, but they’re thought to be rather large. Turing implements just one RT core per SM, which means that even the massive TU102 GPU in the RTX 2080 Ti only has 72 of the units. Furthermore because the RT cores are part of the SM, they’re tightly couple to the SMs in terms of both performance and core counts. As NVIDIA scales down Turing for smaller GPUs by using a smaller number of SMs, the number of RT cores and resulting raytracing performance scale down with it as well. So NVIDIA always maintains the same ratio of SM resources (though chip designs can very elsewhere).
Along with developing a means to more efficiently test ray intersections, the other part of the formula for raytracing success in NVIDIA’s book is to eliminate as much of that work as possible. NVIDIA’s RT cores are comparatively fast, but even so, ray interaction testing is still moderately expensive. As a result, NVIDIA has turned to their tensor cores to carry them the rest of the way, allowing a moderate number of rays to still be sufficient for high-quality images.
In a nutshell, raytracing normally requires casting many rays from each and every pixel in a screen. This is necessary because it takes a large number of rays per pixel to generate the “clean” look of a fully rendered image. Conversely if you test too few rays, you end up with a “noisy” image where there’s significant discontinuity between pixels because there haven’t been enough rays casted to resolve the finer details. But since NVIDIA can’t actually test that many rays in real time, they’re doing the next-best thing and faking it, using neural networks to clean up an image and make it look more detailed than it actually is (or at least, started out at).

To do this, NVIDIA is tapping their tensor cores. These cores were first introduced in NVIDIA’s server-only Volta architecture, and can be thought of as a CUDA core on steroids. Fundamentally they’re just a much larger collection of ALUs inside a single core, with much of their flexibility stripped away. So instead of getting the highly flexible CUDA core, you end up with a massive matrix multiplication machine that is incredibly optimized for processing thousands of values at once (in what’s called a tensor operation). Turing’s tensor cores, in turn, double down on what Volta started by supporting newer, lower precision methods than the original that in certain cases can deliver even better performance while still offering sufficient accuracy.

As for how this applies to ray tracing, the strength of tensor cores is that tensor operations map extremely well to neural network inferencing. This means that NVIDIA can use the cores to run neural networks which will perform additional rendering tasks. in this case a neural network denoising filter is used to clean up the noisy raytraced image in a fraction of the time (and with a fraction of the resources) it would take to actually test the necessary number of rays.

No Denoising vs. Denoising in Raytracing
The denoising filter itself is essentially an image resizing filter on steroids, and can (usually) produce a similar quality image as brute force ray tracing by algorithmically guessing what details should be present among the noise. However getting it to perform well means that it needs to be trained, and thus it’s not a generic solution. Rather developers need to take part in the process, training a neural network based on high quality fully rendered images from their game.
Overall there are 8 tensor cores in every SM, so like the RT cores, they are tightly coupled with NVIDIA’s individual processor blocks. Furthermore this means tensor performance scales down with smaller GPUs (smaller SM counts) very well. So NVIDIA always has the same ratio of tensor cores to RT cores to handle what the RT cores coarsely spit out.
Deep Learning Super Sampling (DLSS)
Now with all of that said, unlike the RT cores, the tensor cores are not fixed function hardware in a traditional sense. They’re quite rigid in their abilities, but they are programmable none the less. And for their part, NVIDIA wants to see just how many different fields/tasks that they can apply their extensive neural network and AI hardware to.
Games of course don’t fall under the umbrella of traditional neural network tasks, as these networks lean towards consuming and analyzing images rather than creating them. None the less, along with denoising the output of their RT cores, NVIDIA’s other big gaming use case for their tensor cores is what they’re calling Deep Learning Super Sampling (DLSS).
DLSS follows the same principle as denoising – how can post-processing be used to clean up an image – but rather than removing noise, it’s about restoring detail. Specifically, how to approximate the image quality benefits of anti-aliasing – itself a roundabout way of rendering at a higher resolution – without the high cost of actually doing the work. When all goes right, according to NVIDIA the result is an image comparable to an anti-aliased image without the high cost.

Under the hood, the way this works is up to the developers, in part because they’re deciding how much work they want to do with regular rendering versus DLSS upscaling. In the standard mode, DLSS renders at a lower input sample count – typically 2x less but may depend on the game – and then infers a result, which at target resolution is similar quality to a Temporal Anti-Aliasing (TAA) result. A DLSS 2X mode exists, where the input is rendered at the final target resolution and then combined with a larger DLSS network. TAA is arguably not a very high bar to set – it’s also a hack of sorts that seeks to avoid doing real overdrawing in favor of post-processing – however NVIDIA is setting out to resolve some of TAA’s traditional inadequacies with DLSS, particularly blurring.
Now it should be noted that DLSS has to be trained per-game; it isn’t a one-size-fits all solution. This is done in order to apply a unique neutral network that’s appropriate for the game at-hand. In this case the neural networks are trained using 64x SSAA images, giving the networks a very high quality baseline to work against.
None the less, of NVIDIA’s two major gaming use cases for the tensor cores, DLSS is by far the more easily implemented. Developers need only to do some basic work to add NVIDIA’s NGX API calls to a game – essentially adding DLSS as a post-processing stage – and NVIDIA will do the rest as far as neural network training is concerned. So DLSS support will be coming out of the gate very quickly, while raytracing (and especially meaningful raytracing) utilization will take much longer.
In sum, then the upcoming game support aligns with the following table.
| Planned NVIDIA Turing Feature Support for Games | |||||
| Game | Real Time Raytracing | Deep Learning Supersampling (DLSS) | Turing Advanced Shading | ||
| Ark: Survival Evolved | Yes | ||||
| Assetto Corsa Competizione | Yes | ||||
| Atomic Heart | Yes | Yes | |||
| Battlefield V | Yes | ||||
| Control | Yes | ||||
| Dauntless | Yes | ||||
| Darksiders III | Yes | ||||
| Deliver Us The Moon: Fortuna | Yes | ||||
| Enlisted | Yes | ||||
| Fear The Wolves | Yes | ||||
| Final Fantasy XV | Yes | ||||
| Fractured Lands | Yes | ||||
| Hellblade: Senua's Sacrifice | Yes | ||||
| Hitman 2 | Yes | ||||
| In Death | Yes | ||||
| Islands of Nyne | Yes | ||||
| Justice | Yes | Yes | |||
| JX3 | Yes | Yes | |||
| KINETIK | Yes | ||||
| MechWarrior 5: Mercenaries | Yes | Yes | |||
| Metro Exodus | Yes | ||||
| Outpost Zero | Yes | ||||
| Overkill's The Walking Dead | Yes | ||||
| PlayerUnknown Battlegrounds | Yes | ||||
| ProjectDH | Yes | ||||
| Remnant: From the Ashes | Yes | ||||
| SCUM | Yes | ||||
| Serious Sam 4: Planet Badass | Yes | ||||
| Shadow of the Tomb Raider | Yes | ||||
| Stormdivers | Yes | ||||
| The Forge Arena | Yes | ||||
| We Happy Few | Yes | ||||
| Wolfenstein II | Yes | ||||








337 Comments
View All Comments
dustwalker13 - Sunday, September 23, 2018 - link
Way too expensive. If those cards were the same price as the 1080 / TI it would be a generation change.This actually is a regression, the price has increased out of every proportion even if you completely were to ignore that newer generations are EXPECTED to be a lot faster than the older ones for essentially the same price (plus a bit of inflation max).
paying 50% more for a 30% increase is a simple ripoff. no one should buy these cards ... sadly a lot of people will let themselves get ripped off once more by nvidia.
and no: raytracing is not an argument here, this feature is not supported anywhere and by the time it will be adopted (if ever) years will have gone bye and these cards will be old and obsolete. all of this is just marketing and hot air.
mapesdhs - Thursday, September 27, 2018 - link
There are those who claim buying RTX to get the new features is sensible for future proofing; I don't understand why they ignore that the performance of said features on these cards is so poor. NVIDIA spent years pushing gamers into high frequency monitors, 4K and VR, now they're trying to flip everyone round the other way, pretend that sub-60Hz 1080p is ok.And btw, it's a lot more than 50%. Where I am (UK) the 2080 Ti is almost 100% more than the 1080 Ti launch price. It's also crazy that the 2080 Ti does not have more RAM, it should have had at least 16GB. My guess is NVIDIA knows that by pushing gamers back down to lower resolutions, they don't need so much VRAM. People though have gotten used to the newer display tech, and those who've adopted high refresh displays physically cannot go back.
milkod2001 - Monday, September 24, 2018 - link
I wonder if NV did not hike prices so much on purpose so they don't have to lower existing GTX prices that much. There is still ton of GTX in stock.poohbear - Friday, September 28, 2018 - link
Why the tame conclusion? Do us a favor will u? Just come out and say you'd have to be mental to pay these prices for features that aren't even available yet and you'd be better off buying previous gen video cards that are currently heavily discounted.zozaino - Thursday, October 4, 2018 - link
i really want to use itzozaino - Thursday, October 4, 2018 - link
i really want to use it https://subwaysurfers.vip/https://psiphon.vip/
https://hillclimbracing.vip/
Luke212 - Wednesday, October 24, 2018 - link
Why does the 2080ti not use the tensor cores for GEMM? I have not seen any benchmark anywhere showing it working. It would be a good news story if Nvidia secretly gimped the tensor cores.