The NVIDIA Turing GPU Architecture Deep Dive: Prelude to GeForce RTX
by Nate Oh on September 14, 2018 12:30 PM ESTTuring RT Cores: Hybrid Rendering and Real Time Raytracing
As it presents itself in Turing, real-time raytracing doesn’t completely replace traditional rasterization-based rendering, instead existing as part of Turing’s ‘hybrid rendering’ model. In other words, rasterization is used for most rendering, while ray-tracing techniques are used for select graphical effects. Meanwhile, the ‘real-time’ performance is generally achieved with a very small amount of rays (e.g. 1 or 2) per pixel, and a very large amount of denoising.
The specific implementation is ultimately in the hands of developers, and NVIDIA naturally has their raytracing development ecosystem, which we’ll go over in a later section. But because of the computational intensity, it simply isn’t possible to use real-time raytracing for the complete rendering workload. And higher resolutions, more complex scenes, and numerous graphical effects also compound the difficulty. So for performance reasons, developers will be utilizing raytracing in a deliberate and targeted manner for specific effects, such as global illumination, ambient occlusion, realistic shadows, reflections, and refractions. Likewise, raytracing may be limited to specific objects in a scene, and rasterization and z-buffering may replace primary ray casting while only secondary rays are raytraced. Thus, the goal of developers is to use raytracing for the most noticeable and realistic effects that rasterization cannot accomplish.
Essentially, this style of ‘hybrid rendering’ is a lot less raytracing than one might imagine from the marketing material. Perhaps a blunt way to generalize might be: real time raytracing in Turing typically means only certain objects are being rendered with certain raytraced graphical effects, using a minimal amount of rays per pixel and/or only raytracing secondary rays, and using a lot of denoising filtering; anything more would affect performance too much. Interestingly, explaining all the caveats this way both undersells and oversells the technology, because therein lies the paradox. Even in this very circumscribed way, GPU performance is significantly affected, but image quality is enhanced with a realism that cannot be provided by a higher resolution or better anti-aliasing. Except ‘real time’ interactivity in gaming essentially means a minimum of 30 to 45 fps, and lowering the render resolution to achieve those framerates hurts image quality. What complicates this is that real time raytracing is indeed considered the ‘holy grail’ of computer graphics, and so managing the feat at all is a big deal, but there are equally valid professional and consumer perspectives on how that translates into a compelling product.
On that note, then, NVIDIA accomplished what the industry was not expecting to be possible for at least a few more years, and certainly not at this scale and development ecosystem. Real time raytracing is the culmination of a decade or so of work, and the Turing RT Cores are the lynchpin. But in building up to it, NVIDIA summarizes the achievement as a result of:
- Hybrid rendering pipeline
- Efficient denoising algorithms
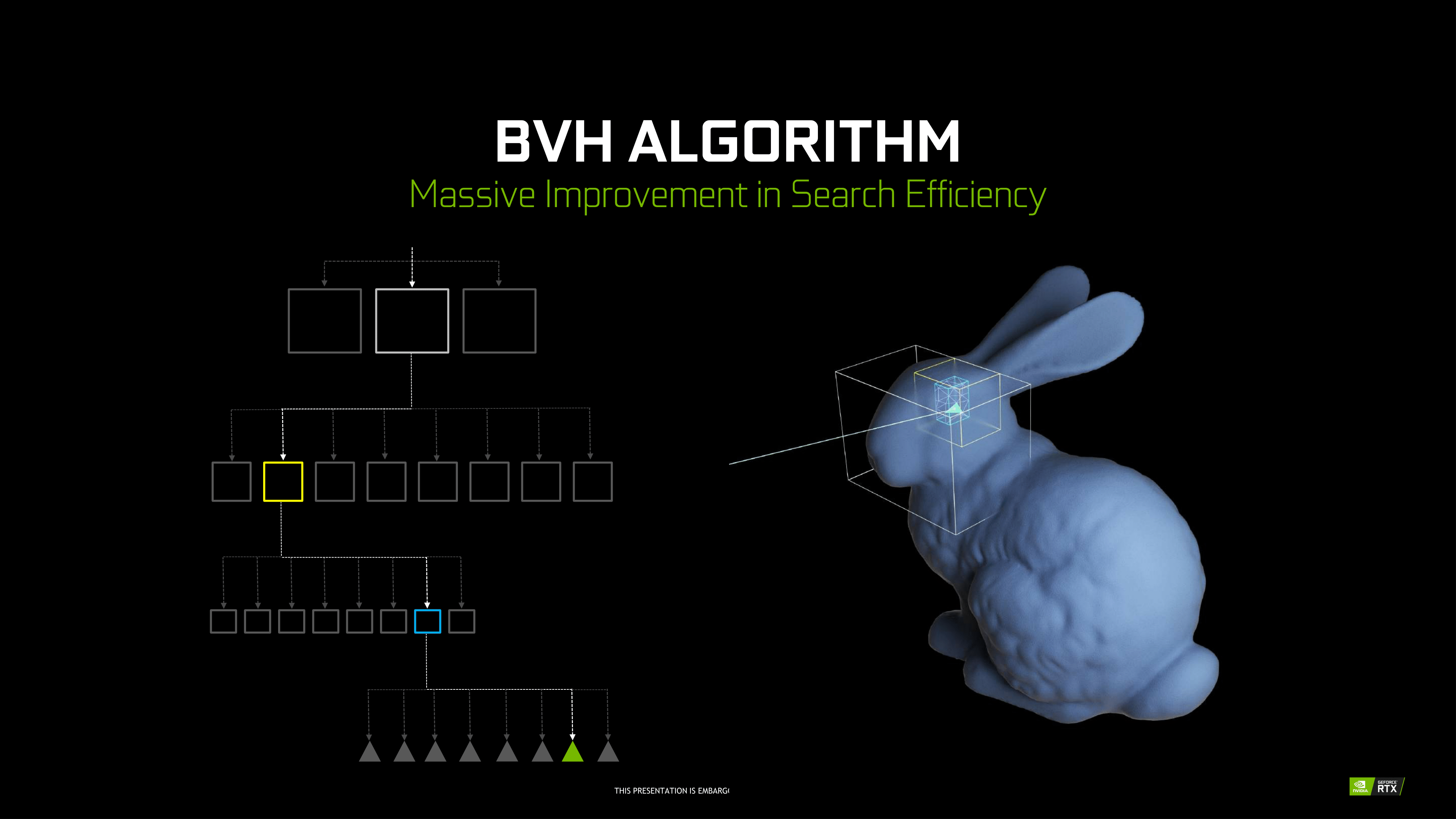
- Efficient BVH algorithms
By themselves, these developments were unable to improve raytracing efficiency, but set the stage for RT Cores. By virtue of raytracing’s importance in the world of computer graphics, NVIDIA Research has been looking into various BVH implementations for quite some time, as well as exploring architectural concerns for raytracing acceleration, something easily noted from their patents and publications. Likewise with denoising, though the latest trend has veered towards using AI and by extension Tensor Cores. When BVH became a standard of sorts, NVIDIA was able to design a corresponding fixed function hardware accelerator.
Being so crucial to their achievement, NVIDIA is not disclosing many details about the RT Cores or their BVH implementation. Of the details given, much is somewhat generic. To reiterate, BVH is a rather general category, and all modern raytracing acceleration structures are typically BVH or kd-tree based.
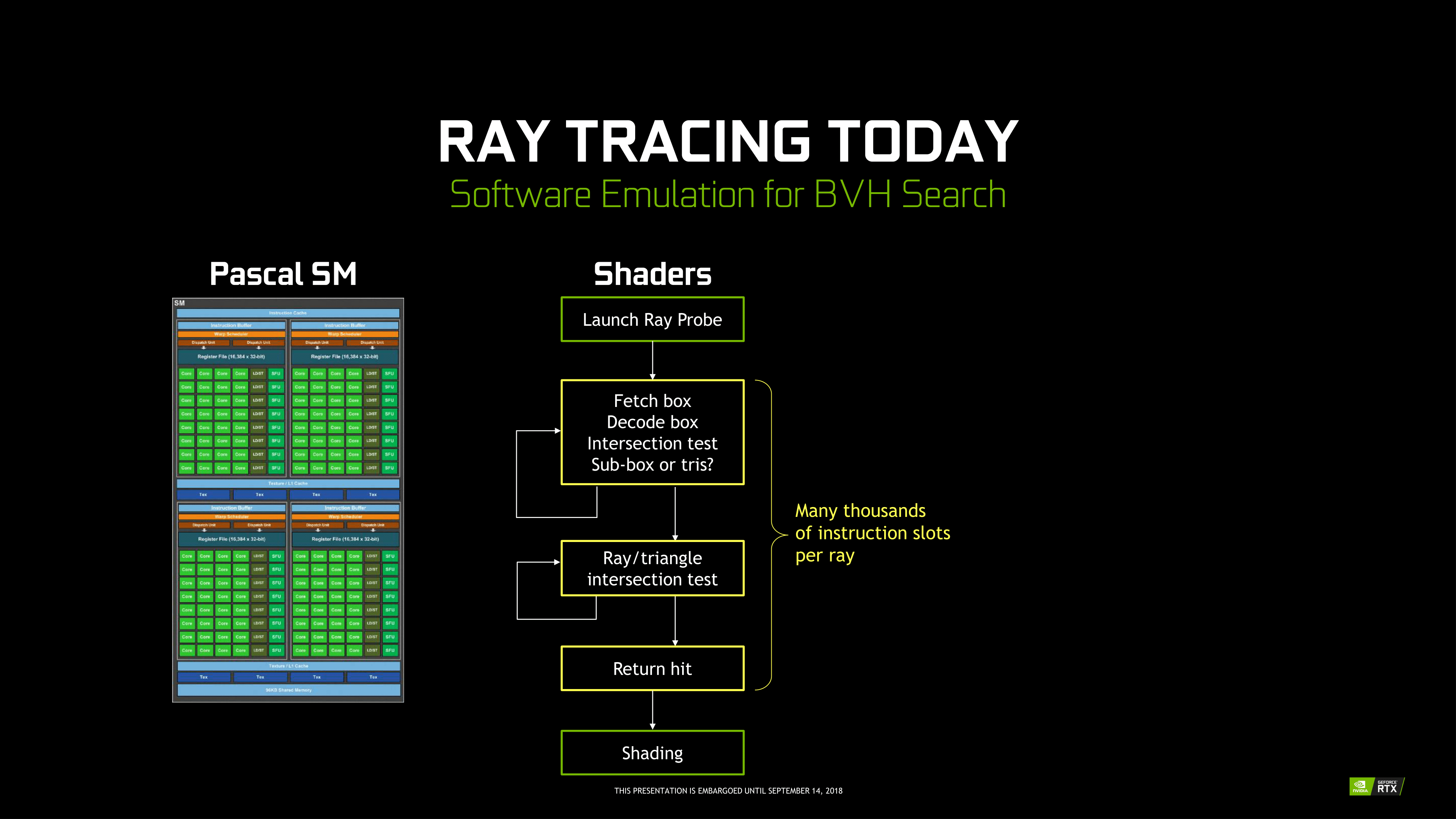
Unlike Tensor Cores, which are better seen as an FMA array alongside the FP and INT cores, the RT Cores are more like a classic offloading IP block. Treated very similar to texture units by the sub-cores, instructions bound for RT Cores are routed out of sub-cores, which is later notified on completion. Upon receiving a ray probe from the SM, the RT Core proceeds to autonomously traverse the BVH and perform ray-intersection tests. This type of ‘traversal and intersection’ fixed function raytracing accelerator is a well-known concept and has had quite a few implementations over the years, as traversal and intersection testing are two of the most computationally intensive tasks involved. In comparison, traversing the BVH in shaders would require thousands of instruction slots per ray cast, all for testing against bounding box intersections in the BVH.
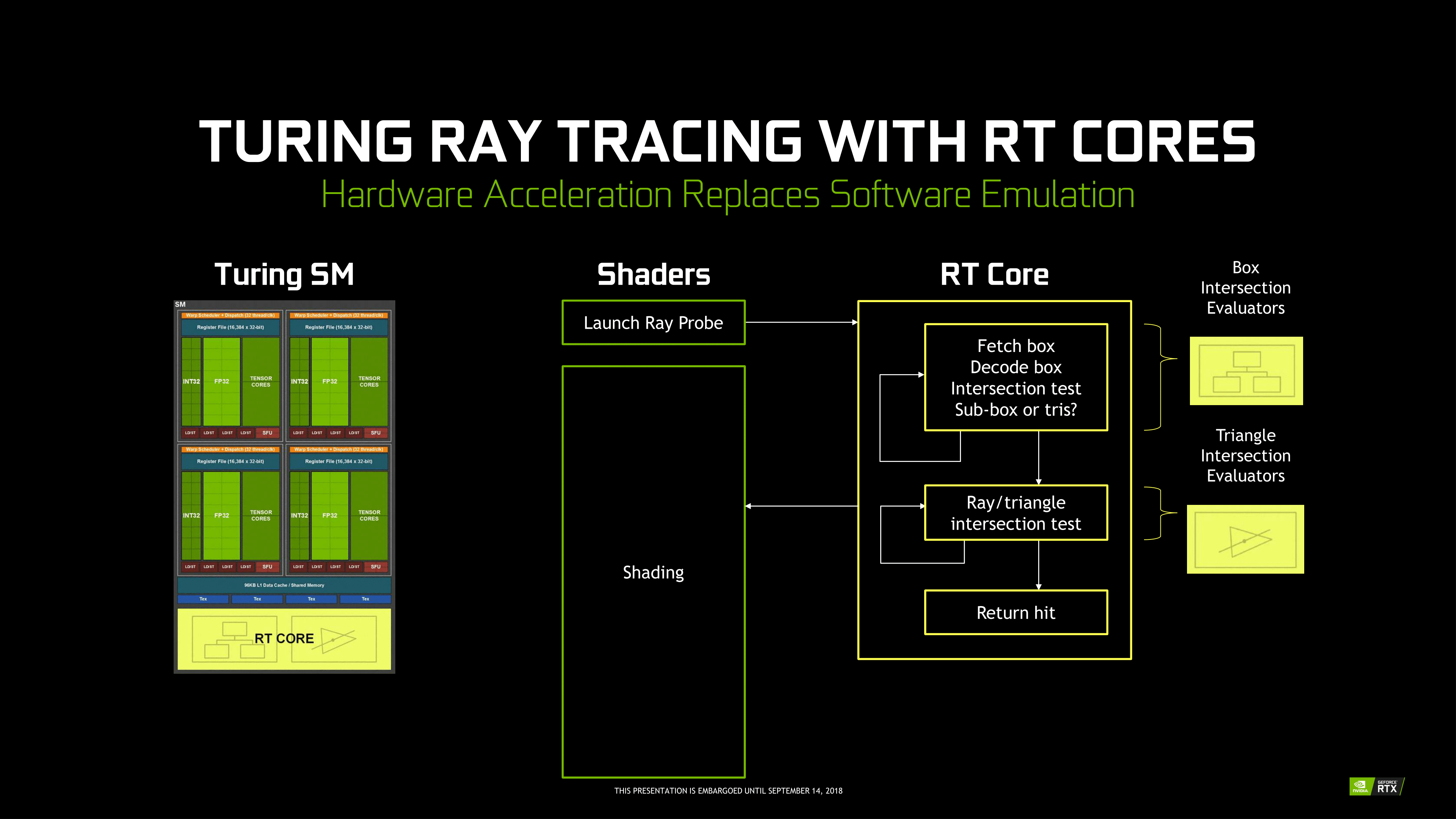
Returning to the RT Core, it will then return any hits and letting shaders do implement the result. The RT Core also handles some grouping and scheduling of memory operations for maximizing memory throughput across multiple rays. And given the workload, presumably some amount of memory and/or ray buffer within the SIP block as well. Like in many other workloads, memory bandwidth is a common bottleneck in raytracing, and has been the focus of several NVIDIA Research papers. And in general, raytracing workloads result in very irregular and random memory accesses, mainly due to incoherent rays, that prove especially problematic for how GPUs typically utilize their memory.
But otherwise, everything else is at a high level governed by the API (i.e. DXR) and the application; construction and update of the BVH is done on CUDA cores, governed by the particular IHV – in this case, NVIDIA – in their DXR implementation.
All-in-all, there’s clearly more involved, and we’ll be looking to run some microbenchmarks in the future. NVIDIA’s custom BVH algorithms are clearly in play, but right now we can’t say what the optimizations might be, such as compressions, wide BVH, node subdivision into treelets. The way the RT Cores are integrated into the SM and into the architecture is likely crucial to how it operates well. Internally, the RT Core might just be a basic traversal and intersection unit, but it might also have other bits inside; one of NVIDIA’s recent patents provide a representation, albeit dated, of what else might be present. I, for one, would not be surprised to see it closely tied with the MIO blocks, and perhaps did more with coherency gathering by manipulating memory traffic for higher efficiency. It would need to coordinate well with the other workloads in the SMs without strangling memory access with unmitigated incoherent rays.
Nevertheless, details like performance impact are as yet unspecified.








111 Comments
View All Comments
Tamz_msc - Saturday, September 15, 2018 - link
"Besides, what you said isn't true even limiting the discussion to what was covered in this article. The Turing Tensor cores allow for a greater range of precisions."You mean lower precision, right? INT8 and INT4 are lower range. From a higher-level view Volta is very similar to Turing, just like the OP described.
Yojimbo - Saturday, September 15, 2018 - link
"greater range of precisions"INT8, INT4, FP16, etc., are precisions. The range of precisions an architecture can handle is the set of all precisions it can handle. Turing Tensor Cores can handle INT4, INT8, and FP16, whereas Volta Tensor Cores can handle FP16. So Turing can handle a greater range of precisions.
Bulat Ziganshin - Friday, September 14, 2018 - link
I would pray for 2060 w/o all this RT/FP16 stuffSpunjji - Monday, September 17, 2018 - link
Seems likely given how nutso these die sizes are. I expect we won't see it until after Pascal inventory is cleared, though.Da W - Friday, September 14, 2018 - link
Well still playing on my 3-screen Haswell + GTX780 rig, and being pretty satisfied of it, i'll probably just get a cheap GTX 1070 or 1080 for my new Ryzen rig and wait if ray tracing really gets adopted in 1 or 2 years. Seems to me lots of transistors invested for not many games. If history told us anything, it's not because a technology is great that it will get adopted, especially if it asks LOADS more developper time for the game companies.Not sure AMD won't come up with something either down the line. They've been given for dead for over 2 decades, guess where they are now!
Holliday75 - Monday, September 17, 2018 - link
I am waiting as well. This is the first attempt to change the game. Next gen or two is where it will be fined tuned and worth purchasing. This feels like a 4k TV purchase. Waste of money.abufrejoval - Friday, September 14, 2018 - link
I wonder how much Turing is about staking out territorial claims vs. dark silicon also coming to GPUs...Obviously Nvidia wants to protect its CUDA machine learning and HPC empire against custom ASIC competitors which finally also include Intel with their Configurable Spatial Accellerator, as well as Cambricon, Google's TPU ASICs and far too many others for comfort.
But while many seem to bemoan that tensor core or rasterizing real-estate is a waste for gaming and just about raising the purchase prices with overhyped features nobody needs, I wonder if apart from the partial truth in that the other motivating driver is simply that the inability to translate additional transistors into additional performance as additional bandwidth requires step changes in GDDR6 lanes (with unshrinkable pad areas and amplifiers) and hits foundry reticle sizes.
So they had transistors left over (wonder where those came from without a die shrink: I/O voltage reduction, layout optimizations, really bigger chips?), that could not be turned into direct DX1x performance gains due to bandwidth and TDP constraints and going to a richer functional base with Tensor Cores and raytrace assists would eat alternate bandwidth or TDP budgets, not additional ones.
Any truth in those assumptions?
abufrejoval - Friday, September 14, 2018 - link
ok, much bigger chips...And no rip-off: They are worth what they are charging if only for the inference accelleration.
Yojimbo - Saturday, September 15, 2018 - link
I am not convinced the Tensor Cores take up a lot of real estate. And they are tightly integrated into NVIDIA's SMs. Designing two SMs, one with Tensor Cores and one without Tensor Cores would be a lot more expensive than leaving them in. Plus, NVIDIA sees deep learning as important for gaming.Your argument about FLOPS per bandwidth does have validity. It's just that neither Tensor Cores nor RT cores were just thrown in there because they had transistors left over. Look at the die sizes of these new GPUs compared to Pascal GPUs. If they built a smaller chip that performed the same in legacy games then they could sell them more cheaply, and so sell more of them, while making the same profit on each one. That would mean higher margins and greater profits.
The RTX and Tensor Cores are a strategic initiative. I think in making the decision to include them NVIDIA judged that those two technologies would have a positive impact on the future of gaming. The reason they made that judgment may include the dwindling FLOPS/memory bandwidth trend.
bernstein - Friday, September 14, 2018 - link
really interesting time in gpu's right now... remember a decade ago when intel teased a x86-gpu that promised to do real-time raytracing?yet turing may turn out to provide an abysmal price/perf ratio.
- about half the transistors will only be used in a few upcoming games, they could be used to possibly double performance in rasterization-only games (7nm amd navi anyone?)
- but if (hybrid-)raytracing takes off quickly, turing will be crushed by 7nm gpu's dedicating way more transistors to the task, as it's performance is still skewed heavily towards rasterization
- ai inferencing seems like a safe bet, again i'd wager that DLSS will only ever work with the vast minority of games released each day on steam, so it's usefulness will depends on whether developers make other use of the available silicon... (better AI opponents anyone?)