The NVIDIA Turing GPU Architecture Deep Dive: Prelude to GeForce RTX
by Nate Oh on September 14, 2018 12:30 PM ESTRay Tracing 101: What It Is & Why NVIDIA Is Betting On It
Because one of the two cornerstone technologies of the Turing architecture is NVIDIA’s ray tracing RT cores, before we dive too much into the Turing architecture, it’s perhaps best to start with a discussion on just what ray tracing is. And equally important, why NVIDIA is betting so much silicon on it.
Ray tracing, in short, is a rendering process that emulates how light behaves in the real world. From a fundamental (but not quite quantum physics) level, light can be considered to behave like a ray. This is because photons, outside other influences, will travel in a straight line until they hit something. At which point various interactions (reflection, refraction, etc) occur between photons and the object.

The catch with ray tracing is that it’s expensive. Incredibly expensive. The scale of the problem means that if you take a naïve approach and try to calculate all of the rays of photons emitting from every light source in a scene, you’re going to be tracing an uncountable, near-infinite number of rays bouncing around a scene. It is essentially modeling all of the physical interactions of light within a bounded space, and that’s an incredible number of interactions.
As a result there have been a number of optimizations developed for ray tracing over the years. Perhaps the most important of which is sort of turning the naïve concept on its head, and instead of tracing rays starting from light sources, you instead go backwards. You trace rays starting from the point of the observer – essentially casting them out into a scene – so that you only end up calculating the light rays that actually reach the camera.
Such “reverse” ray tracing cuts down on the problem space significantly. It also means that conceptually, ray tracing can be thought of as a pixel-based method; the goal is to figure out what each pixel should be.
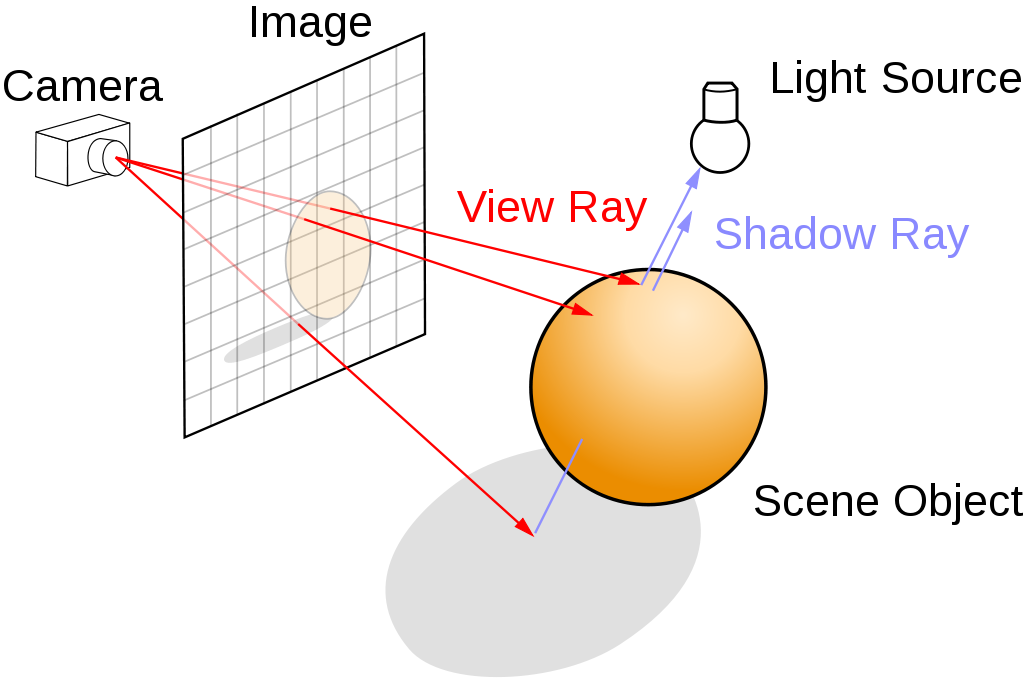
Ray Tracing Diagram (Henrik / CC BY-SA 4.0)
However even with this optimization and others, ray tracing is still very expensive. These techniques make ray tracing cheap enough that it can be done on a computer in a reasonable amount of time, where “reasonable” is measured in minutes or hours, depending on the scene and just how precise and clean you want the rendered frame to be. As a result, anything other than the cheapest, grainiest ray tracing has been beyond the reach of real-time rendering.
In practical terms then, up until now ray tracing has been reserved purely for “offline” scenarios, particularly 3D graphics in movies. The quality of ray tracing makes it second to none – it’s emulating how light actually works, after all – as it can accurately calculate reflections, shadows, light diffusion, and other effects to a degree of accuracy that no other method can. But doing all of this comes at a heavy cost.

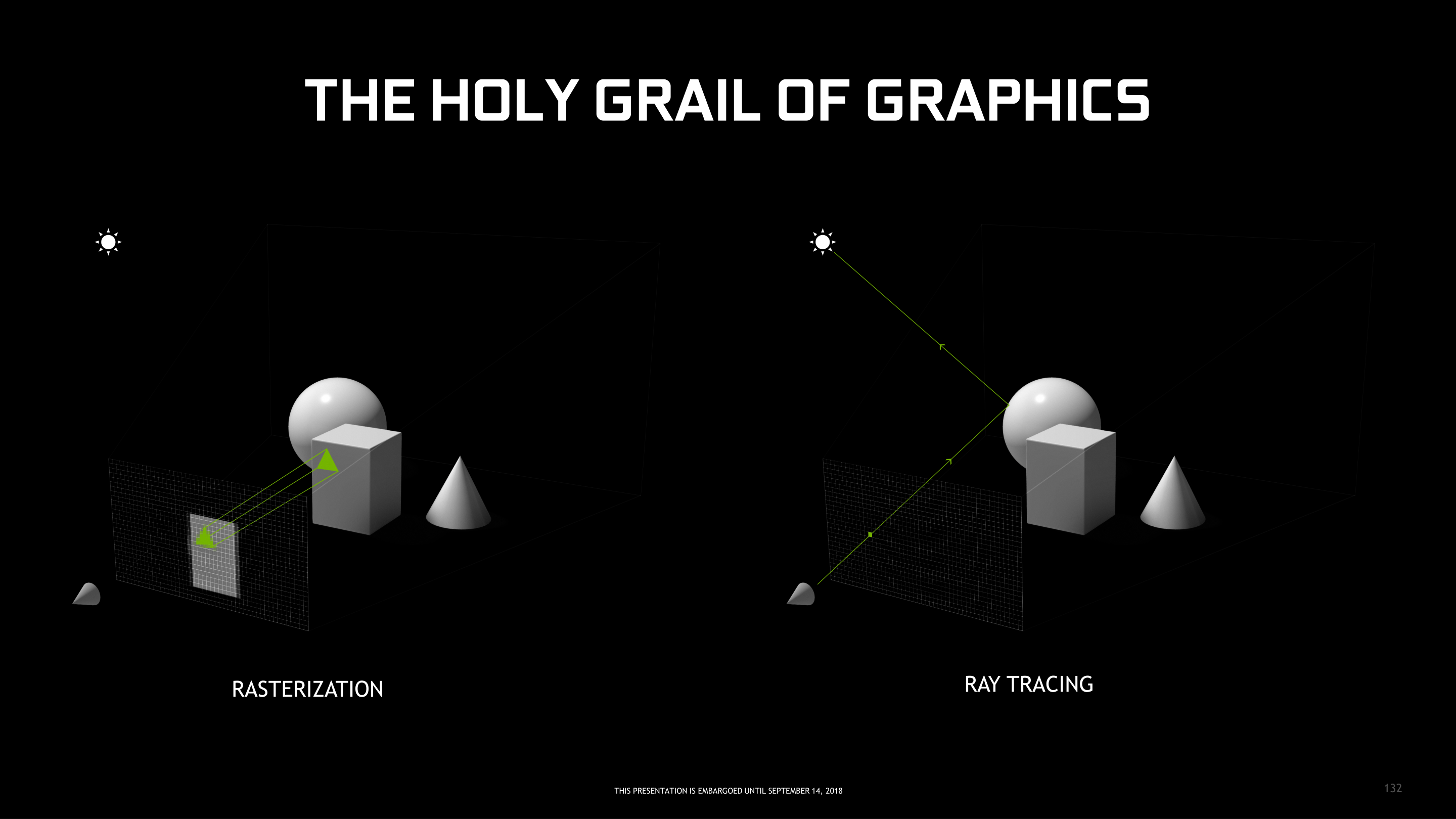
Enter Rasterization: The World’s Greatest Hack
The high computational cost of ray tracing means that it hasn’t been viable for real-time graphics. Instead, since the earliest of days, the computing industry has turned to rasterization.
If ray tracing is a pixel-based approach, then rasterization would be called a polygon-centric approach to 3D rendering. But more than that, rasterization is a hack – a glorious hack to get around the fact that computers aren’t (or at least, weren’t) fast enough to do real-time ray tracing. Rasterization takes a number of shortcuts and makes a number of assumptions about how light, objects, and materials work in order to reduce the computational workload for rendering a scene down to something that can be done in real time.
Rasterization at its most basic level is the process of taking the polygons in a scene and mapping them to a 2D plane, the pixel grid. This means polygons are sorted and tested to see which polygons are actually visible, and then in various stages, these polygons are textured, shaded, and otherwise processed to determine their final color. And admittedly this is a gross simplification of a process that was already a simplification – I’m completely ignoring all the math that goes into transforming 3D objects into a 2D representation – but in an amusing twist of fate, the hack that is rasterization is in some ways more complex than the natural process of ray tracing.
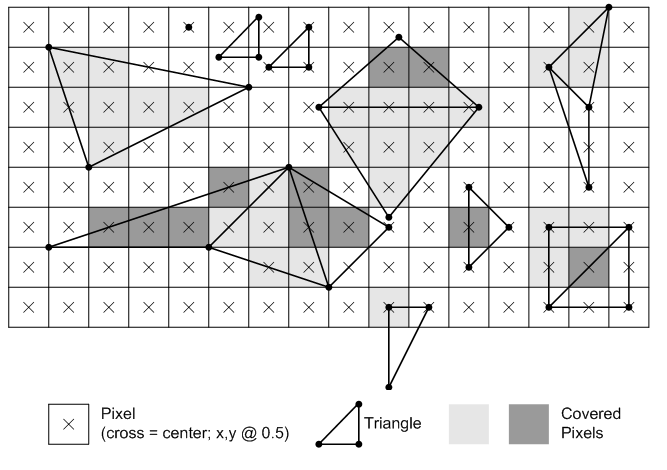
The key point to rasterization is not so much how it works, but rather that it doesn’t use rays, and therefore it’s cheap. Very cheap. And better still, it can be done in parallel. As a result GPUs have arisen as incredible matrix multiplication machines, and are capable of testing hundreds of millions of polygons every second and coloring billions of pixels. With a few exceptions, rasterization is nice and orderly, allowing computational techniques like Single Instruction Multiple Data/Thread (SIMD/SIMT) to do the necessary processing with incredible efficiency.
The catch to rasterization is that because it’s a hack – however glorious it is – at the end of the day there are limitations to how well it can fake how vision and light work in the real world. Past basic polygon projection and texturing, pixel shading is where most of the work is done these days to actually determine what color a pixel needs to be. It’s in pixel shaders that the various forms of lighting (shadows, reflection, refraction, etc) are emulated, where distortion effects are calculated, etc. And pixel shaders, while powerful in their own right, are not capable of emulating real light to a high degree, at least not in a performant manner.
It’s these limitations that lead to the well-publicized drawbacks in rasterization. The unnatural light, the limited reflections, the low resolution shadows, etc. Now conceptually, it is by no means impossible to resolve these issues with rasterization. However the computational cost of doing so is very high, as the nature of rasterization is such that it’s difficult to bolt on such high accuracy methods on to what’s at its core a hack. Rasterization is meant to be quick & dirty, not accurate.
Ray Tracing Returns – Hybridization
Coming full-circle then, we reach the obvious question: if rasterization is so inaccurate, how are games meant to further improve their image quality? Certainly it’s possible to continue going down the road of rasterization, and even if the problem gets harder, image quality will get better. But keeping in mind that rasterization is a hack, it’s good to periodically look at what that hack is trying to achieve and whether that hack is worth the trade-offs.
Or to put this another way: if you’re going to put in this much effort just to cheat, maybe it would be better to put that effort into accurately rendering a scene to begin with?
Now in 2018, the computing industry as a whole is starting to ask just that question. Ray tracing is still expensive, but then so are highly accurate rasterization methods. So at some point it may make more sense to just do ray tracing at certain points rather than to hack it. And it’s this train of thought that NVIDIA is pursuing with great gusto for Turing.
For NVIDIA, the path forward is no longer pure rasterization. Instead their world view is one of hybrid rendering: combining the best parts of rasterization and compute with the best parts of ray tracing. Just what those parts are and where they should be done is a question ultimately up to developers, but at a high level, the idea NVIDIA is putting forth is to use ray tracing where it makes sense – for lighting, shadows, and everything else involving the interaction of light – and then using traditional rasterization-based methods for everything else.

This means that rather than immediately jumping from rasterization to ray tracing and losing all of the performance benefits of the former, developers can enjoy the best of both worlds, choosing how they want to balance the performance of rasterization with the quality of ray tracing. The examples NVIDIA and its partners have pitched thus far have been the low-hanging fruit – accurate real-time reflections, improved transparency, and better global illumination – but the use cases conceivably be extended to any kind of lighting-related operation. And perhaps, for the John Carmacks and Tim Sweeneys of the world, possibly something a lot more unorthodox.
With all of that said however, just because hybrid rasterization and ray tracing looks like a good idea on paper, that doesn’t mean it’s guaranteed to work well in practice. Certainly this initiative spans far more than just NVIDIA – Microsoft’s DXR API is a cornerstone that everyone can build from – however to call this the early days would be an overstatement. NVIDIA, Microsoft, and other companies are going to have to build an ecosystem essentially from scratch. And they’re not only going to have to sell developers on the merits of ray tracing, but they’re going to have to teach developers on how to implement it in an efficient manner. Neither of these are easy tasks. After all, ray tracing is not the only way forward, it’s merely one way forward. And, if you agree with NVIDIA, the most promising way forward.
But for today, let’s table the discussion of the merits of ray tracing. NVIDIA has made their move, and indeed the decisions that lead to Turing would have happened years ago. So instead, let’s take a look at how NVIDIA is going to transform their goals into reality by building hardware units specifically for ray tracing.








{kind=link}
111 Comments
View All Comments
Tamz_msc - Saturday, September 15, 2018 - link
"Besides, what you said isn't true even limiting the discussion to what was covered in this article. The Turing Tensor cores allow for a greater range of precisions."You mean lower precision, right? INT8 and INT4 are lower range. From a higher-level view Volta is very similar to Turing, just like the OP described.
Yojimbo - Saturday, September 15, 2018 - link
"greater range of precisions"INT8, INT4, FP16, etc., are precisions. The range of precisions an architecture can handle is the set of all precisions it can handle. Turing Tensor Cores can handle INT4, INT8, and FP16, whereas Volta Tensor Cores can handle FP16. So Turing can handle a greater range of precisions.
Bulat Ziganshin - Friday, September 14, 2018 - link
I would pray for 2060 w/o all this RT/FP16 stuffSpunjji - Monday, September 17, 2018 - link
Seems likely given how nutso these die sizes are. I expect we won't see it until after Pascal inventory is cleared, though.Da W - Friday, September 14, 2018 - link
Well still playing on my 3-screen Haswell + GTX780 rig, and being pretty satisfied of it, i'll probably just get a cheap GTX 1070 or 1080 for my new Ryzen rig and wait if ray tracing really gets adopted in 1 or 2 years. Seems to me lots of transistors invested for not many games. If history told us anything, it's not because a technology is great that it will get adopted, especially if it asks LOADS more developper time for the game companies.Not sure AMD won't come up with something either down the line. They've been given for dead for over 2 decades, guess where they are now!
Holliday75 - Monday, September 17, 2018 - link
I am waiting as well. This is the first attempt to change the game. Next gen or two is where it will be fined tuned and worth purchasing. This feels like a 4k TV purchase. Waste of money.abufrejoval - Friday, September 14, 2018 - link
I wonder how much Turing is about staking out territorial claims vs. dark silicon also coming to GPUs...Obviously Nvidia wants to protect its CUDA machine learning and HPC empire against custom ASIC competitors which finally also include Intel with their Configurable Spatial Accellerator, as well as Cambricon, Google's TPU ASICs and far too many others for comfort.
But while many seem to bemoan that tensor core or rasterizing real-estate is a waste for gaming and just about raising the purchase prices with overhyped features nobody needs, I wonder if apart from the partial truth in that the other motivating driver is simply that the inability to translate additional transistors into additional performance as additional bandwidth requires step changes in GDDR6 lanes (with unshrinkable pad areas and amplifiers) and hits foundry reticle sizes.
So they had transistors left over (wonder where those came from without a die shrink: I/O voltage reduction, layout optimizations, really bigger chips?), that could not be turned into direct DX1x performance gains due to bandwidth and TDP constraints and going to a richer functional base with Tensor Cores and raytrace assists would eat alternate bandwidth or TDP budgets, not additional ones.
Any truth in those assumptions?
abufrejoval - Friday, September 14, 2018 - link
ok, much bigger chips...And no rip-off: They are worth what they are charging if only for the inference accelleration.
Yojimbo - Saturday, September 15, 2018 - link
I am not convinced the Tensor Cores take up a lot of real estate. And they are tightly integrated into NVIDIA's SMs. Designing two SMs, one with Tensor Cores and one without Tensor Cores would be a lot more expensive than leaving them in. Plus, NVIDIA sees deep learning as important for gaming.Your argument about FLOPS per bandwidth does have validity. It's just that neither Tensor Cores nor RT cores were just thrown in there because they had transistors left over. Look at the die sizes of these new GPUs compared to Pascal GPUs. If they built a smaller chip that performed the same in legacy games then they could sell them more cheaply, and so sell more of them, while making the same profit on each one. That would mean higher margins and greater profits.
The RTX and Tensor Cores are a strategic initiative. I think in making the decision to include them NVIDIA judged that those two technologies would have a positive impact on the future of gaming. The reason they made that judgment may include the dwindling FLOPS/memory bandwidth trend.
bernstein - Friday, September 14, 2018 - link
really interesting time in gpu's right now... remember a decade ago when intel teased a x86-gpu that promised to do real-time raytracing?yet turing may turn out to provide an abysmal price/perf ratio.
- about half the transistors will only be used in a few upcoming games, they could be used to possibly double performance in rasterization-only games (7nm amd navi anyone?)
- but if (hybrid-)raytracing takes off quickly, turing will be crushed by 7nm gpu's dedicating way more transistors to the task, as it's performance is still skewed heavily towards rasterization
- ai inferencing seems like a safe bet, again i'd wager that DLSS will only ever work with the vast minority of games released each day on steam, so it's usefulness will depends on whether developers make other use of the available silicon... (better AI opponents anyone?)