The NVIDIA Turing GPU Architecture Deep Dive: Prelude to GeForce RTX
by Nate Oh on September 14, 2018 12:30 PM ESTTuring Tensor Cores: Leveraging Deep Learning Inference for Gaming
Though RT Cores are Turing’s poster child feature, the tensor cores were very much Volta’s. In Turing, they’ve been updated, reflecting its positioning as a gaming/consumer feature via inferencing. The main changes for the 2nd generation tensor cores are INT8 and INT4 precision modes for inferencing, enabled by new hardware data paths, and perform dot products to accumulate into an INT32 product. INT8 mode operates at double the FP16 rate, or 2048 integer operations per clock. INT4 mode operates at quadruple the FP16 rate, or 4096 integer ops per clock.

Naturally, only some networks tolerate these lower precisions and any necessary quantization, meaning the storage and calculation of compacted format data. INT4 is firmly in the research area, whereas INT8’s practical applicability is much more developed. Regardless, the 2nd generation tensor cores still have FP16 mode, which they now support in a pure FP16 mode without FP32 accumulator. While CUDA 10 is not yet out, the enhanced WMMA operations should shed light on any other differences, such as additional accepted matrix sizes for operands.
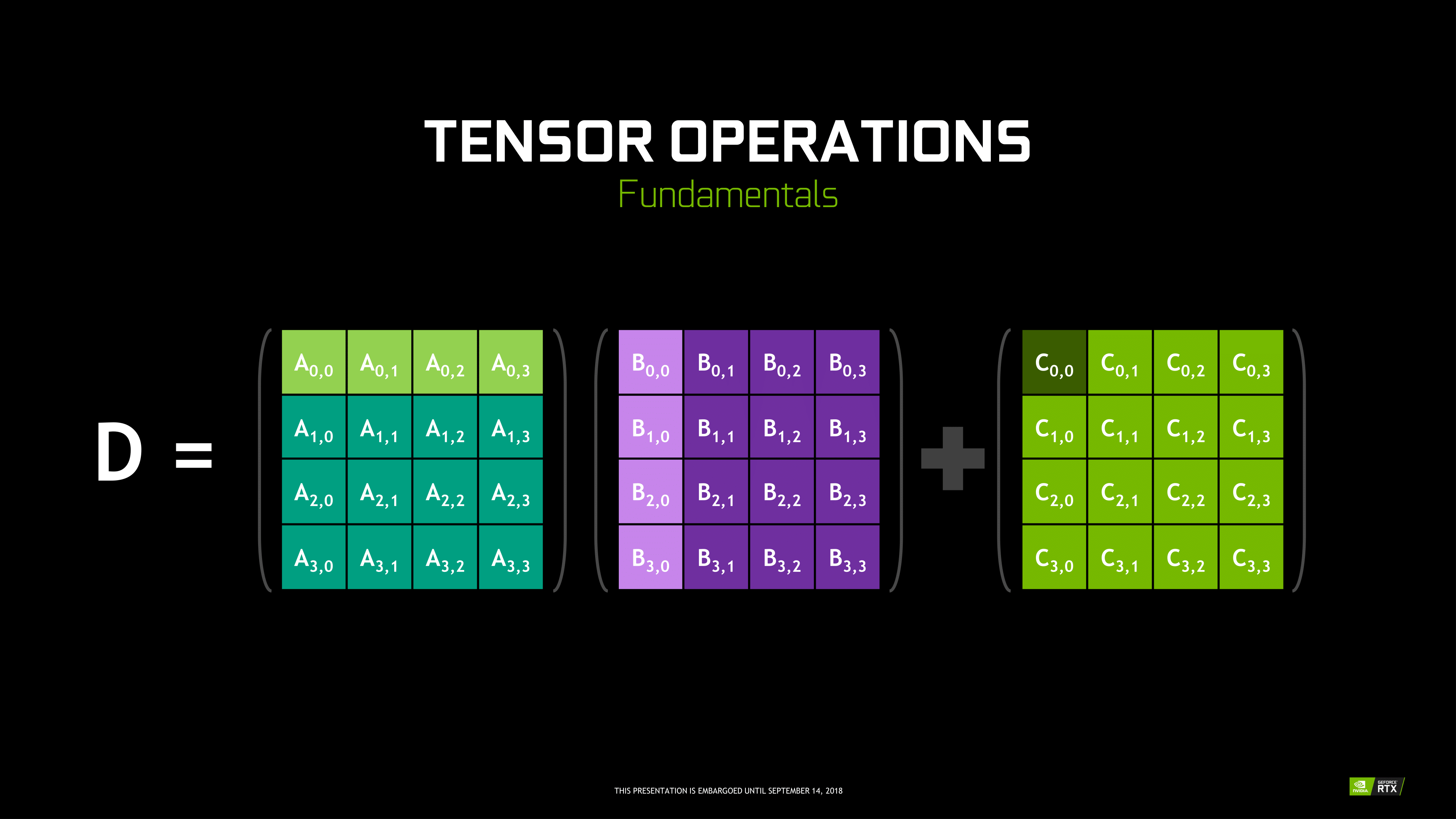
Inasmuch as deep learning is involved, NVIDIA is pushing what was a purely compute/professional feature into consumer territory, and we will go over the full picture in a later section. For Turing, the tensor cores can accelerate the features under the NGX umbrella, which includes DLSS. They can also accelerate certain AI-based denoisers that cleanup and correct real time raytraced rendering, though most developers seem to be opting for non-tensor core accelerated denoisers at the moment.








111 Comments
View All Comments
Yojimbo - Saturday, September 15, 2018 - link
Of course he meant giga as in billion. Of course it's simple. But where did you see "gigarays/sec" before? You didn't. So as far as you know, it is an NVIDIA-made term.He said it that way because it's easier to talk about it that way, and because NVIDIA is making a marketing term out of it. And he introduced it with a joke.
edzieba - Saturday, September 15, 2018 - link
'Gigs' is an SI prefix. You put it in front of any unit to indicate 10^9 of that unit.eddman - Saturday, September 15, 2018 - link
Why does it even matter?! As I pointed out, I meant to write "rays/sec". I forgot to take out the giga part after copy/paste.I'm pretty sure a lot of ray tracing developers have uttered the words "giga rays" before jensen.
markiz - Monday, September 17, 2018 - link
Well car makers are also using kilowatts for engines. Bastards.Yojimbo - Saturday, September 15, 2018 - link
Where do you get these die area estimates from?edzieba - Saturday, September 15, 2018 - link
If you compare scaled die shots of Turing to Pascal (GP102), isolate an SM, and assume each CUDA core occupies the same die area, then the combination of Tensor and RT cores takes around 24% die area. This is more of an upper bound, as the CUDA cores are likely to be larger due to the concurrent execution capability, there is more space in the SM taken by memory, and more uncore taken by the NVLink interfacesYojimbo - Saturday, September 15, 2018 - link
Where are these die shots? Paste them? I think that people are looking at schematics, not die shots.edzieba - Saturday, September 15, 2018 - link
Nvidia posted them (surprisingly correctly scaled) as part of the Turing unveil presentation.Yojimbo - Saturday, September 15, 2018 - link
Can you link me to them and to an analysis of them?808Hilo - Sunday, September 16, 2018 - link
So far 10% better than 1080ti and 15% over 1080. Really not worth it. Better spend money on MB, new chip, ram and fast SSD if coming from an older PC.