The NVIDIA Turing GPU Architecture Deep Dive: Prelude to GeForce RTX
by Nate Oh on September 14, 2018 12:30 PM ESTTuring Tensor Cores: Leveraging Deep Learning Inference for Gaming
Though RT Cores are Turing’s poster child feature, the tensor cores were very much Volta’s. In Turing, they’ve been updated, reflecting its positioning as a gaming/consumer feature via inferencing. The main changes for the 2nd generation tensor cores are INT8 and INT4 precision modes for inferencing, enabled by new hardware data paths, and perform dot products to accumulate into an INT32 product. INT8 mode operates at double the FP16 rate, or 2048 integer operations per clock. INT4 mode operates at quadruple the FP16 rate, or 4096 integer ops per clock.

Naturally, only some networks tolerate these lower precisions and any necessary quantization, meaning the storage and calculation of compacted format data. INT4 is firmly in the research area, whereas INT8’s practical applicability is much more developed. Regardless, the 2nd generation tensor cores still have FP16 mode, which they now support in a pure FP16 mode without FP32 accumulator. While CUDA 10 is not yet out, the enhanced WMMA operations should shed light on any other differences, such as additional accepted matrix sizes for operands.
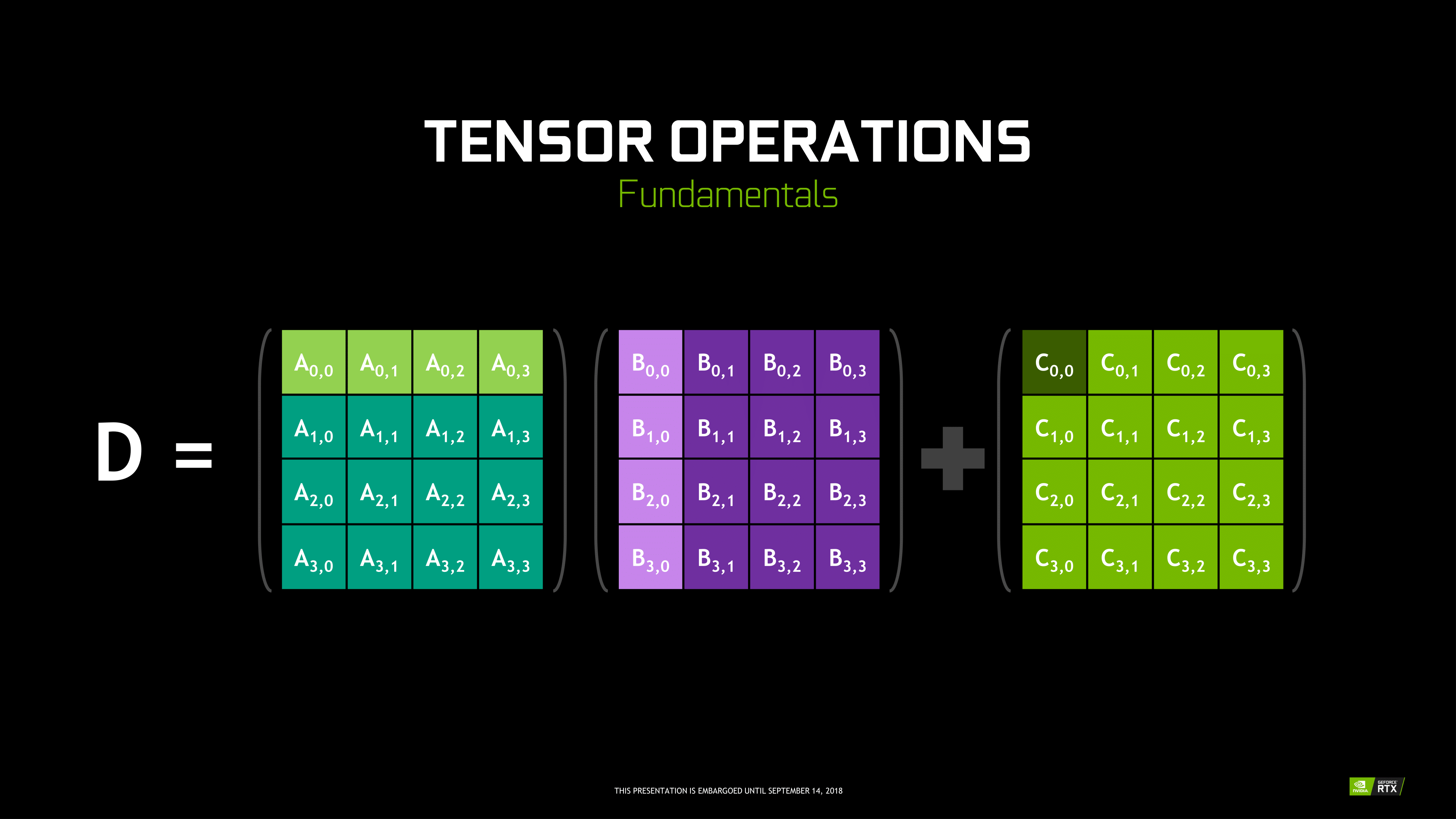
Inasmuch as deep learning is involved, NVIDIA is pushing what was a purely compute/professional feature into consumer territory, and we will go over the full picture in a later section. For Turing, the tensor cores can accelerate the features under the NGX umbrella, which includes DLSS. They can also accelerate certain AI-based denoisers that cleanup and correct real time raytraced rendering, though most developers seem to be opting for non-tensor core accelerated denoisers at the moment.








111 Comments
View All Comments
BurntMyBacon - Monday, September 17, 2018 - link
Good article. I would have been nice to get more information as to exactly what nVidia is doing with the RT cores to optimize ray tracing, but I can understand why they would want to keep that a secret at this point. One oversight in an otherwise excellent article:@Nate Oh (article): "The net result is that with nearly every generation, the amount of memory bandwidth available per FLOP, per texture lookup, and per pixel blend has continued to drop. ... Turing, in turn, is a bit of an interesting swerve in this pattern thanks to its heavy focus on ray tracing and neural network inferencing. If we're looking at memory bandwidth merely per CUDA core FLOP, then bandwidth per FLOP has actually gone up, since RTX 2080 doesn't deliver a significant increase in (on-paper) CUDA core throughput relative to GTX 1080."
The trend has certainly been downward, but I was curious as to why the GTX 780 wasn't listed. When I checked it out, I found that it is another "swerve" in the pattern similar to the RTX2080. The specifications for the NVIDIA Memory Bandwidth per FLOP (In Bits) chart are:
GTX 780 - 0.58 bits | 3.977 TFLOPS | 288GB/sec
This is easily found information and its omission is pretty noticeable (at least to me), so I assume it got overlooked (easy to do in an article this large). While it doesn't match your initial always downward observation, it also clearly doesn't change the trend. It just means the trend is not strictly monotonic.
nboelter - Tuesday, September 18, 2018 - link
I had to solve the problem of “random memory accesses from the graphics card memory are the main bottleneck for the performance of the molecular dynamics simulation” when i did some physics on CUDA, and got great results with Hilbert space-filling curves (there is a fabulous german paper from 1891 about this newfangled technology) to - essentially - construct BVHs. Only difference really is that i had grains of sand instead of photons. Now i really wonder if these RT cores could be used for physics simulations!webdoctors - Tuesday, September 18, 2018 - link
This will likely get lost in the 100 comments, but this is really huge and getting ignored by the pricing.I've often wondered and complained for years to my friends why we keep going to higher resolutions from 720p to 4K rather than actually improving the graphics. Look at a movie on DVD from 20 yrs ago at 480p resolution, and the graphics are so much more REALISTSIC than the 4K stuff you see in games today because its either real ppl on film or if CG raytraced offline with full lighting. Imagine getting REAL TIME renders that look like real life video, that's a huge breakthrough. Sure we've raytracing for decades, but never real time on non-datacenter size clusters.
Rasterization 4K or 8K content will never look as REAL as 1080p raytraced content. It might look nicer, but it won't look REAL. Its great we'll have hardware where we can choose whether we want to use the fake rasterization cartoony path or the REAL path.
A 2080TI that costs $1200 will be $120 in 10 years, but it won't change the fact that now you're getting REAL vs fake. 2 years ago, you didn't have the option, you couldn't say I'll pay you $5k to give me the ray traced option in the game, now we'll get (hopefully) developer support and see this mainstream. Probably can use AWS to gamestream this instead of buying a video card and than get the raytrace now too.
If you're happy with non-ray tracing, just buy a 1070 and stick to playing games in 1080p. You'll never be perf limited for any games and move on.
eddman - Wednesday, September 19, 2018 - link
You are not getting REAL with 20 series, not even close.MadManMark - Wednesday, September 19, 2018 - link
His point is that we are getting CLOSER to "real," not that it is CLOSE or IS real. Would have thought that was obvious, but guess ti isn't to everyone.eddman - Thursday, September 20, 2018 - link
It seems you are the one who misread. From his comment: "it won't change the fact that now you're getting REAL vs fake"So, yes, he does think with 20 series you get the REAL thing.
sudz - Wednesday, September 19, 2018 - link
"as opposed Pascal’s 2 partition setup with two dispatch ports per sub-core warp scheduler."So in conclusion: RTX has more warp cores.
Engage!
ajp_anton - Friday, September 21, 2018 - link
This comment is a bit late, but your math for memory efficiency is wrong.If bandwidth+compression gives a 50% increase, and bandwidth alone is a 27% increase, you can't just subtract them to get the compression increase. In this example, compression increase is 1.5/1.27 = 1,18, or 18%. Not the 23% that you get by subtracting.
This also means you have to re-write the text where you think it's weird how this is higher than the last generation increase, because it no longer is higher.
Overmind - Thursday, September 27, 2018 - link
There are many inconsistencies in the article.Overmind - Thursday, September 27, 2018 - link
If the 102 with 12 complete functional modules has 72 RTCs (RTX-ops) how can the 2080 Ti with 11 functional modules has 78 RTCs ? The correct value is clearly 68.