ATI Radeon X800 Pro and XT Platinum Edition: R420 Arrives
by Derek Wilson on May 4, 2004 10:28 AM EST- Posted in
- GPUs
Depth and Stencil with Hyper Z HD
In accordance with their "High Definition Gaming" theme, ATI is calling the R420's method of handling depth and stencil processing Hyper Z HD. Depth and stencil processing is handled at multiple points throughout the pipeline, but grouping all this hardware into one block can make sense as each step along the way will touch the z-buffer (an on die cache of z and stencil data). We have previously covered other incarnations of Hyper Z which have done basically the same job. Here we can see where the Hyper Z HD functionality interfaces with the rendering pipeline:
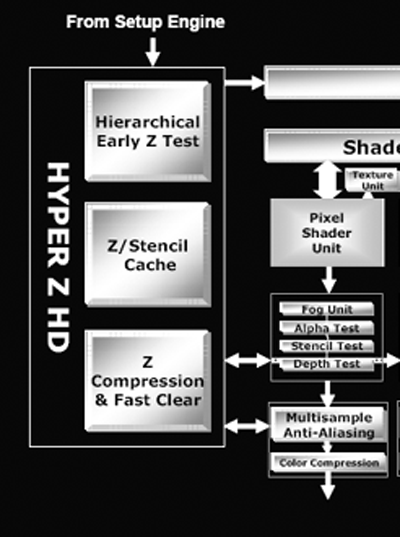
The R420 architecture implements a hierarchical and early z type of occlusion culling in the rendering pipeline.
With early z, as data emerges from the geometry processing portion of the GPU, it is possible to skip further rendering large portions of the scene that are occluded (or covered) by other geometry. In this way, pixels that won't be seen don't need to run through the pixel shader pipelines and waste precious resources.
Hierarchical z indicates that large blocks of pixels are checked and thrown out if the entire tile is occluded. In R420, these tiles are the very same ones output by the geometry and setup engine. If only part of a tile is occluded, smaller subsections are checked and thrown out if possible. This processing doesn't eliminate all the occluded pixels, so pixels coming out of the pixel pipelines also need to be tested for visibility before they are drawn to the framebuffer. The real difference between R3xx and R420 is in the number of pixels that can be gracefully handled.
As rasterization draws nearer, the ATI and NVIDIA architectures begin to differentiate themselves more. Both claim that they are able to calculate up to 32 z or stencil operations per clock, but the conditions under which this is true are different. NV40 is able to push two z/stencil operations per pixel pipeline during a z or stencil only pass or in other cases when no color data is being dealt with (the color unit in NV40 can work with z/stencil data when no color computation is needed). By contrast, R420 pushes 32 z/stencil operations per clock cycle when antialiasing is enabled (one z/stencil operation can be completed per clock at the end of each pixel pipeline, and one z/stencil operation can be completed inside the multisample AA unit).
The different approaches these architectures take mean that each will excel in different ways when dealing with z or stencil data. Under R420, z/stencil speed will be maximized when antialiasing is enabled and will only see 16 z/stencil operations per clock under non-antialiased rendering. NV40 will achieve maximum z/stencil performance when a z/stencil only pass is performed regardless of the state of antialiasing.
The average case for NV40 will be closer to 16 z/stencil operations per clock, and if users don't run antialiasing on R420 they won't see more than 16 z/stencil operations per clock. Really, if everyone begins to enable antialiasing, R420 will begin to shine in real world situations, and if developers embrace z or stencil only passes (such as in Doom III), NV40 will do very well. The bottom line on which approach is better will be defined by the direction the users and developers take in the future. Will enabling antialiasing win out over running at ultra-high resolutions? Will developers mimic John Carmack and the intensive shadowing capabilities of Doom III? Both scenarios could play out simultaneously, but, really, only time will tell.








95 Comments
View All Comments
saechaka - Tuesday, May 4, 2004 - link
wow. very impressive. i was set on getting an nvidia but just don't know anymorePhiro - Tuesday, May 4, 2004 - link
The message is clear; Matrox has failed!Brickster - Tuesday, May 4, 2004 - link
Show me the money!MemberSince97 - Tuesday, May 4, 2004 - link
Advanced features are worthless if your driver team keeps breaking them..f11 - Tuesday, May 4, 2004 - link
kinda starting to feel sorry for nvidia now. each generation they stuff their cards with more feautures than they need to, end end up with a slower and more featured card. If anyone's expecting SM3 to be a big hit, remember that the original FX line had lots of extensions to DX9 and they never really made much a difference.