The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTCore to Core to Core: Design Trade Offs
AMD’s approach to these big processors is to take a small repeating unit, such as the 4-core complex or 8-core silicon die (which has two complexes on it), and put several on a package to get the required number of cores and threads. The upside of this is that there are a lot of replicated units, such as memory channels and PCIe lanes. The downside is how cores and memory have to talk to each other.
In a standard monolithic (single) silicon design, each core is on an internal interconnect to the memory controller and can hop out to main memory with a low latency. The speed between the cores and the memory controller is usually low, and the routing mechanism (a ring or a mesh) can determine bandwidth or latency or scalability, and the final performance is usually a trade-off.
In a multiple silicon design, where each die has access to specific memory locally but also has access to other memory via a jump, we then come across a non-uniform memory architecture, known in the business as a NUMA design. Performance can be limited by this abnormal memory delay, and software has to be ‘NUMA-aware’ in order to maximize both the latency and the bandwidth. The extra jumps between silicon and memory controllers also burn some power.
We saw this before with the first generation Threadripper: having two active silicon dies on the package meant that there was a hop if the data required was in the memory attached to the other silicon. With the second generation Threadripper, it gets a lot more complex.
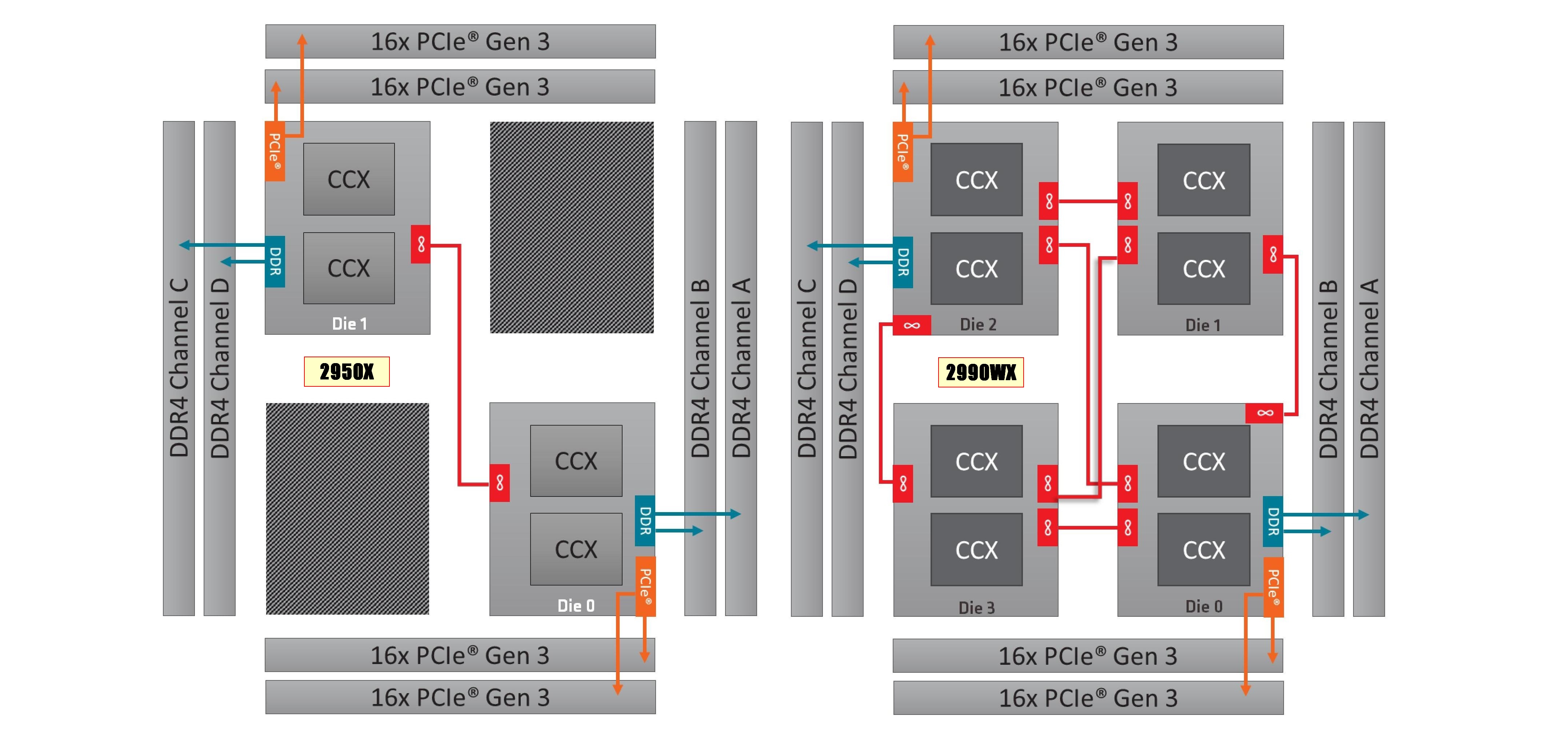
On the left is the 1950X/2950X design, with two active silicon dies. Each die has direct access to 32 PCIe lanes and two memory channels each, which when combined gives 60/64 PCIe lanes and four memory channels. The cores that have direct access to the memory/PCIe connected to the die are faster than going off-die.
For the 2990WX and 2970WX, the two ‘inactive’ dies are now enabled, but do not have extra access to memory or PCIe. For these cores, there is no ‘local’ memory or connectivity: every access to main memory requires an extra hop. There is also extra die-to-die interconnects using AMD’s Infinity Fabric (IF), which consumes power.
The reason that these extra cores do not have direct access is down to the platform: the TR4 platform for the Threadripper processors is set at quad-channel memory and 60 PCIe lanes. If the other two dies had their memory and PCIe enabled, it would require new motherboards and memory arrangements.
Users might ask, well can we not change it so each silicon die has one memory channel, and one set of 16 PCIe lanes? The answer is that yes, this change could occur. However the platform is somewhat locked in how the pins and traces are managed on the socket and motherboards. The firmware is expecting two memory channels per die, and also for electrical and power reasons, the current motherboards on the market are not set up in this way. This is going to be an important point when get into the performance in the review, so keep this in mind.
It is worth noting that this new second generation of Threadripper and AMD’s server platform, EPYC, are cousins. They are both built from the same package layout and socket, but EPYC has all the memory channels (eight) and all the PCIe lanes (128) enabled:
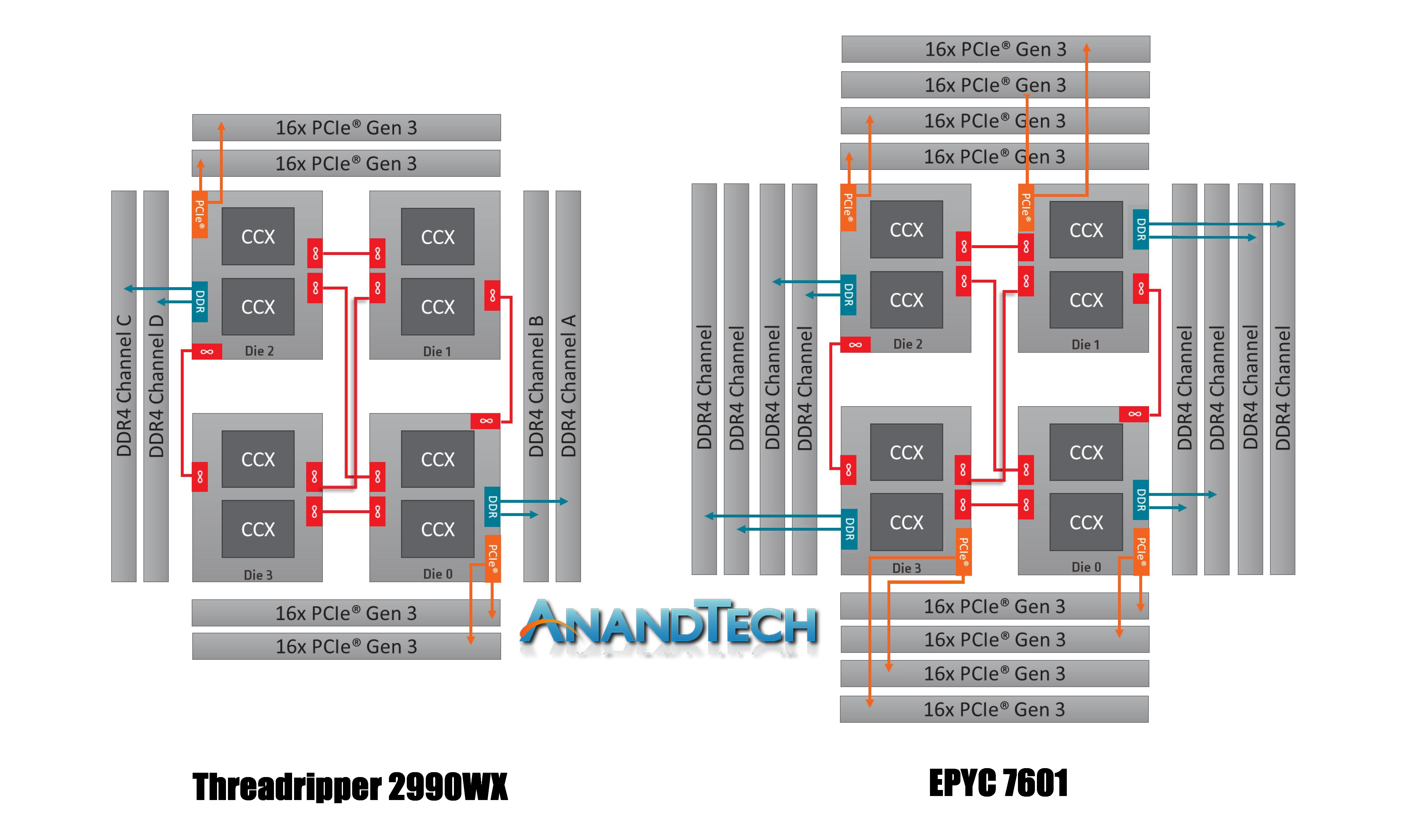
Where Threadripper 2 falls down on having some cores without direct access to memory, EPYC has direct memory available everywhere. This has the downside of requiring more power, but it offers a more homogenous core-to-core traffic layout.
Going back to Threadripper 2, it is important to understand how the chip is going to be loaded. We confirmed this with AMD, but for the most part the scheduler will load up the cores that are directly attached to memory first, before using the other cores. What happens is that each core has a priority weighting, based on performance, thermals, and power – the ones closest to memory get a higher priority, however as those fill up, the cores nearby get demoted due to thermal inefficiencies. This means that while the CPU will likely fill up the cores close to memory first, it will not be a simple case of filling up all of those cores first – the system may get to 12-14 cores loaded before going out to the two new bits of silicon.








171 Comments
View All Comments
Ian Cutress - Monday, August 13, 2018 - link
It looks like the 2950X are reversed (C++ should be OpenCL), but I checked the raw data and that's what came out of the benchmark. I need to put the 2950X back on to test, I'll do it in a bitStuka87 - Monday, August 13, 2018 - link
Thanks for getting this up Ian! An awesome read per usual :)deathBOB - Monday, August 13, 2018 - link
The interconnect analysis was very interesting, glad you spent time on that.mapesdhs - Monday, August 13, 2018 - link
Yes, that was good. I had flashbacks to reading SGI Origin technical reports 20 years ago. :Dhttp://www.sgidepot.co.uk/origin/isca.pdf
http://www.sgidepot.co.uk/origin/hypercube.pdf
Index: http://www.sgidepot.co.uk/origin/
I see a great many similarities, though the emphasis is different (SGI was all about bandwidth rather than latency, for extreme I/O and huge datasets in shared memory, though they greatly improved the latency behaviour with the 2nd-gen design). Fascinating to see many of the same issues play out in the consumer space, but for rather different tasks, though I bet a lot of researchers in industry and academia will be taking keen interest in what AMD has released.
close - Monday, August 13, 2018 - link
"They will enable four cores per complex (8+8+8+8) and three cores per complex (6+6+6+6)"3/4 cores per complex or 6/8 cores?
MrSpadge - Monday, August 13, 2018 - link
The 8 cores per die are distributed over 2 CCX core complexes with 4 cores each, as in Ryzen 1.FreckledTrout - Monday, August 13, 2018 - link
LOL You actually ran tests with the plastic on? That is just funny. Did the plastic melt?Ian Cutress - Monday, August 13, 2018 - link
It ran fine, though the numbers suggest the thermals reduced PB2/XFR2 turbo by a fair bit. Some tests look a bit down. Still writing it up :)FreckledTrout - Tuesday, August 14, 2018 - link
Hilarious. That does sound like something I would do in a hurry. I see you have a whole section awaiting for plastic vs no plastic thermals. I bet that will be an Anandtech only talking point. :)msroadkill612 - Thursday, August 16, 2018 - link
A coredom?