The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTHEDT Benchmarks: System Tests
Our System Test section focuses significantly on real-world testing, user experience, with a slight nod to throughput. In this section we cover application loading time, image processing, simple scientific physics, emulation, neural simulation, optimized compute, and 3d model development, with a combination of readily available and custom software. For some of these tests, the bigger suites such as PCMark do cover them (we publish those values in our office section), although multiple perspectives is always beneficial. In all our tests we will explain in-depth what is being tested, and how we are testing.
Application Load: GIMP 2.10.4
One of the most important aspects about user experience and workflow is how fast does a system respond. A good test of this is to see how long it takes for an application to load. Most applications these days, when on an SSD, load fairly instantly, however some office tools require asset pre-loading before being available. Most operating systems employ caching as well, so when certain software is loaded repeatedly (web browser, office tools), then can be initialized much quicker.
In our last suite, we tested how long it took to load a large PDF in Adobe Acrobat. Unfortunately this test was a nightmare to program for, and didn’t transfer over to Win10 RS3 easily. In the meantime we discovered an application that can automate this test, and we put it up against GIMP, a popular free open-source online photo editing tool, and the major alternative to Adobe Photoshop. We set it to load a large 50MB design template, and perform the load 10 times with 10 seconds in-between each. Due to caching, the first 3-5 results are often slower than the rest, and time to cache can be inconsistent, we take the average of the last five results to show CPU processing on cached loading.
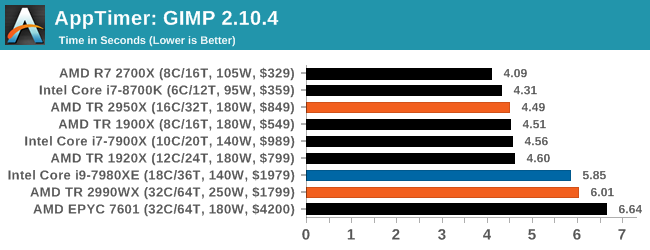
This benchmark has neatly fallen into two categories: mostly lower core count processors on one side, and the high-end desktop on the other. The 1920X and 2950X are quick, while Intel’s 18-core and the 32-core parts are slower. This is likely due to the bigger differential in single core performance, however I suspect that some of the memory latency might also be a factor here.
FCAT: Image Processing
The FCAT software was developed to help detect microstuttering, dropped frames, and run frames in graphics benchmarks when two accelerators were paired together to render a scene. Due to game engines and graphics drivers, not all GPU combinations performed ideally, which led to this software fixing colors to each rendered frame and dynamic raw recording of the data using a video capture device.
The FCAT software takes that recorded video, which in our case is 90 seconds of a 1440p run of Rise of the Tomb Raider, and processes that color data into frame time data so the system can plot an ‘observed’ frame rate, and correlate that to the power consumption of the accelerators. This test, by virtue of how quickly it was put together, is single threaded. We run the process and report the time to completion.
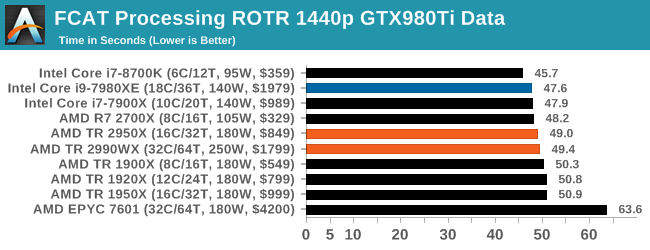
All our systems perform similarly, however Intel’s faster single threaded performance puts its processors in the lead here. The EPYC 7601 sits out back with its low single core frequency.
3D Particle Movement v2.1: Brownian Motion
Our 3DPM test is a custom built benchmark designed to simulate six different particle movement algorithms of points in a 3D space. The algorithms were developed as part of my PhD., and while ultimately perform best on a GPU, provide a good idea on how instruction streams are interpreted by different microarchitectures.
A key part of the algorithms is the random number generation – we use relatively fast generation which ends up implementing dependency chains in the code. The upgrade over the naïve first version of this code solved for false sharing in the caches, a major bottleneck. We are also looking at AVX2 and AVX512 versions of this benchmark for future reviews.
For this test, we run a stock particle set over the six algorithms for 20 seconds apiece, with 10 second pauses, and report the total rate of particle movement, in millions of operations (movements) per second.
3DPM v2.1 can be downloaded from our server: 3DPMv2.1.rar (13.0 MB)
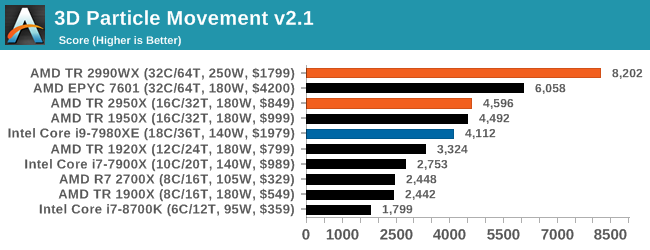
It would appear that 3DPM loves threads and frequency, with the top four spots going to AMD. Even last generation’s 16-core outperforms Intel’s 18-core in this test using non-AVX instructions. An interesting comparison here is between the 2990WX and the EPYC 7601 – the extra frequency on the consumer processor helps drive an extra 30%+ performance.
Dolphin 5.0: Console Emulation
One of the popular requested tests in our suite is to do with console emulation. Being able to pick up a game from an older system and run it as expected depends on the overhead of the emulator: it takes a significantly more powerful x86 system to be able to accurately emulate an older non-x86 console, especially if code for that console was made to abuse certain physical bugs in the hardware.
For our test, we use the popular Dolphin emulation software, and run a compute project through it to determine how close to a standard console system our processors can emulate. In this test, a Nintendo Wii would take around 1050 seconds.
The latest version of Dolphin can be downloaded from https://dolphin-emu.org/
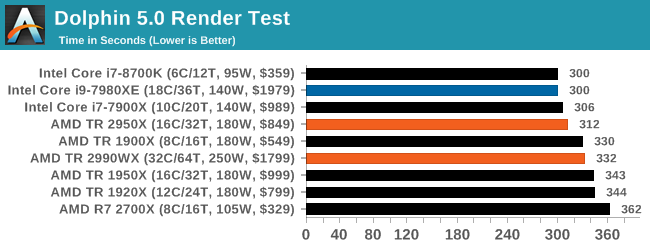
Dolphin is typically governed by single threaded performance, so Intel sits at the front here again, although having the R7 2700X at the end seems a little odd. On the off chance that this is a freak result, I should run this test again. However on the second generation TR parts, the higher clock frequency of the 2950X puts it ahead of the 2990WX by a good 20 seconds.
DigiCortex 1.20: Sea Slug Brain Simulation
This benchmark was originally designed for simulation and visualization of neuron and synapse activity, as is commonly found in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron / 1.8B synapse simulation, equivalent to a Sea Slug.
Example of a 2.1B neuron simulation
We report the results as the ability to simulate the data as a fraction of real-time, so anything above a ‘one’ is suitable for real-time work. Out of the two modes, a ‘non-firing’ mode which is DRAM heavy and a ‘firing’ mode which has CPU work, we choose the latter. Despite this, the benchmark is still affected by DRAM speed a fair amount.
DigiCortex can be downloaded from http://www.digicortex.net/
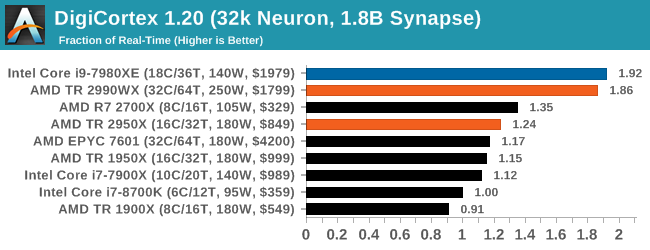
Here the quad-core processors with lots of cores have a good lead out front, however the low frequency of the EPYC 7601 puts it down the list. It would seem that the extra latency bi-modal cores in the 2990WX have not done too much damage, although you would feel that there might be extra performance to gain.
y-Cruncher v0.7.6: Microarchitecture Optimized Compute
I’ve known about y-Cruncher for a while, as a tool to help compute various mathematical constants, but it wasn’t until I began talking with its developer, Alex Yee, a researcher from NWU and now software optimization developer, that I realized that he has optimized the software like crazy to get the best performance. Naturally, any simulation that can take 20+ days can benefit from a 1% performance increase! Alex started y-cruncher as a high-school project, but it is now at a state where Alex is keeping it up to date to take advantage of the latest instruction sets before they are even made available in hardware.
For our test we run y-cruncher v0.7.6 through all the different optimized variants of the binary, single threaded and multi-threaded, including the AVX-512 optimized binaries. The test is to calculate 250m digits of Pi, and we use the single threaded and multi-threaded versions of this test.
Users can download y-cruncher from Alex’s website: http://www.numberworld.org/y-cruncher/
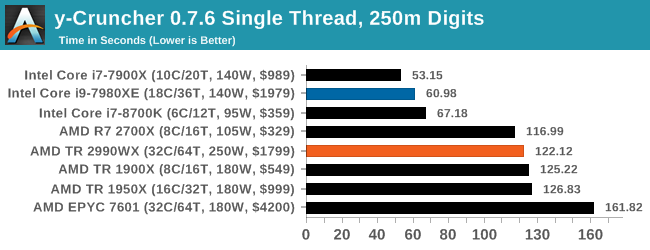
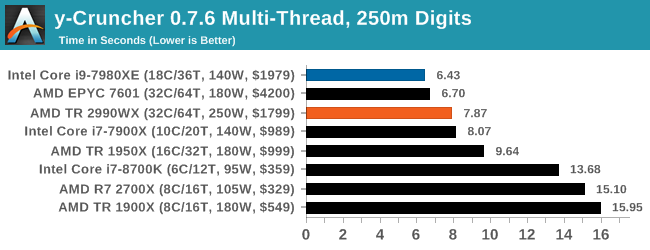
The Intel software is heavily optimized for AVX2 or AVX512, which sows in our single threaded test, however when we pile on the cores and the memory channels, both of AMD’s 32-core parts give the Core i9 a run for its money.
Agisoft Photoscan 1.3.3: 2D Image to 3D Model Conversion
One of the ISVs that we have worked with for a number of years is Agisoft, who develop software called PhotoScan that transforms a number of 2D images into a 3D model. This is an important tool in model development and archiving, and relies on a number of single threaded and multi-threaded algorithms to go from one side of the computation to the other.

In our test, we take v1.3.3 of the software with a good sized data set of 84 x 18 megapixel photos and push it through a reasonably fast variant of the algorithms, but is still more stringent than our 2017 test. We report the total time to complete the process.
Agisoft’s Photoscan website can be found here: http://www.agisoft.com/

Photoscan shows a good spread, however the 2990WX is sitting at the back as it has cores that cannot access memory quick enough – the EPYC 7601 with double the memory channels operates almost 500 seconds (20%+) quicker, so if the 2990WX had extra memory, I’m sure it would shoot up the list.
Interesting the TR 1950X sits top, above the TR 2950X which has better cache latency and higher frequency in all scenarios. That’s a head scratcher.








171 Comments
View All Comments
plonk420 - Tuesday, August 14, 2018 - link
worse for efficiency?https://techreport.com/r.x/2018_08_13_AMD_s_Ryzen_...
Railgun - Monday, August 13, 2018 - link
How can you tell? The article isn’t even finished.mapesdhs - Monday, August 13, 2018 - link
People will argue a lot here about performance per watt and suchlike, but in the real world the cost of the software and the annual license renewal is often far more than the base hw cost, resulting in a long term TCO that dwarfs any differences in some CPU cost. I'm referring here to the kind of user that would find the 32c option relevant.Also missing from the article is the notion of being able to run multiple medium scale tasks on the same system, eg. 3 or 4 tasks each of which is using 8 to 10 cores. This is quite common practice. An article can only test so much though, at this level of hw the number of different parameters to consider can be very large.
Most people on tech forums of this kind will default to tasks like 3D rendering and video conversion when thinking about compute loads that can use a lot of cores, but those are very different to QCD, FEA and dozens of other tasks in research and data crunching. Some will match the arch AMD is using, others won't; some could be tweaked to run better, others will be fine with 6 to 10 cores and just run 4 instances testing different things. It varies.
Talking to an admin at COSMOS years ago, I was told that even coders with seemingly unlimited cores to play with found it quite hard to scale relevant code beyond about 512 cores, so instead for the sort of work they were doing, the centre would run multilple simulations at the same time, which on the hw platform in question worked very nicely indeed (1856 cores of the SandyBridge-EP era, 14.5TB of globally shared memory, used primarily for research in cosmology, astrophysics and particle physics; squish it all into a laptop and I'm sure Sheldon would be happy. :D) That was back in 2012, but the same concepts apply today.
For TR2, the tricky part is getting the OS to play nice, along with the BIOS, and optimised sw. It'll be interesting to see how 2990WX performance evolves over time as BIOS updates come out and AMD gets feedback on how best to exploit the design, new optimisations from sw vendors (activate TR2 mode!) and so on.
SGI dealt with a lot of these same issues when evolving its Origin design 20 years ago. For some tasks it absolutely obliterated the competition (eg. weather modelling and QCD), while for others in an unoptimised state it was terrible (animation rendering, not something that needs shared memory, but ILM wrote custom sw to reuse bits of a frame already calculated for future frame, the data able to fly between CPUs very fast, increasing throughput by 80% and making the 32-CPU systems very competitive, but in the long run it was easier to brute force on x86 and save the coder salary costs).
There are so many different tasks in the professional space, the variety is vast. It's too easy to think cores are all that matter, but sometimes having oodles of RAM is more important, or massive I/O (defense imaging, medical and GIS are good examples).
I'm just delighted to see this kind of tech finally filter down to the prosumer/consumer, but alas much of the nuance will be lost, and sadly some will undoubtedly buy based on the marketing, as opposed to the golden rule of any tech at this level: ignore the publish benchmarks, the ony test that actually matters is your specific intended task and data, so try and test it with that before making a purchasing decision.
Ian.
AbRASiON - Monday, August 13, 2018 - link
Really? I can't tell if posts like these are facetious or kidding or what?I want AMD to compete so badly long term for all of us, but Intel have such immense resources, such huge infrastructure, they have ties to so many big business for high end server solutions. They have the bottom end of the low power market sealed up.
Even if their 10nm is delayed another 3 years, AMD will only just begin to start to really make a genuine long term dent in Intel.
I'd love to see us at a 50/50 situation here, heck I'd be happy with a 25/75 situation. As it stands, Intel isn't finished, not even close.
imaheadcase - Monday, August 13, 2018 - link
Are you looking at same benchmarks as everyone else? I mean AMD ass was handed to it in Encoding tests and even went neck to neck against some 6c intel products. If AMD got one of these out every 6 months with better improvements sure, but they never do.imaheadcase - Monday, August 13, 2018 - link
Especially when you consider they are using double the core count to get the numbers they do have, its not very efficient way to get better performance.crotach - Tuesday, August 14, 2018 - link
It's happened before. AMD trashes Intel. Intel takes it on the chin. AMD leads for 1-2 years and celebrates. Then Intel releases a new platform and AMD plays catch-up for 10 years and tries hard not to go bankrupt.I dearly hope they've learned a lesson the last time, but I have my doubts. I will support them and my next machine will be AMD, which makes perfect sense, but I won't be investing heavily in the platform, so no X399 for me.
boozed - Tuesday, August 14, 2018 - link
We're talking about CPUs that cost more than most complete PCs. Willy-waving aside, they are irrelevant to the market.Ian Cutress - Monday, August 13, 2018 - link
Hey everyone, sorry for leaving a few pages blank right now. Jet lag hit me hard over the weekend from Flash Memory Summit. Will be filling in the blanks and the analysis throughout today.But here's what there is to look forward to:
- Our new test suite
- Analysis of Overclocking Results at 4G
- Direct Comparison to EPYC
- Me being an idiot and leaving the plastic cover on my cooler, but it completed a set of benchmarks. I pick through the data to see if it was as bad as I expected
The benchmark data should now be in Bench, under the CPU 2019 section, as our new suite will go into next year as well.
Thoughts and commentary welcome!
Tamz_msc - Monday, August 13, 2018 - link
Are the numbers for test LuxMark C++ test correct? Seems they've been swapped(2900WX and 2950X).