The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTCore to Core to Core: Design Trade Offs
AMD’s approach to these big processors is to take a small repeating unit, such as the 4-core complex or 8-core silicon die (which has two complexes on it), and put several on a package to get the required number of cores and threads. The upside of this is that there are a lot of replicated units, such as memory channels and PCIe lanes. The downside is how cores and memory have to talk to each other.
In a standard monolithic (single) silicon design, each core is on an internal interconnect to the memory controller and can hop out to main memory with a low latency. The speed between the cores and the memory controller is usually low, and the routing mechanism (a ring or a mesh) can determine bandwidth or latency or scalability, and the final performance is usually a trade-off.
In a multiple silicon design, where each die has access to specific memory locally but also has access to other memory via a jump, we then come across a non-uniform memory architecture, known in the business as a NUMA design. Performance can be limited by this abnormal memory delay, and software has to be ‘NUMA-aware’ in order to maximize both the latency and the bandwidth. The extra jumps between silicon and memory controllers also burn some power.
We saw this before with the first generation Threadripper: having two active silicon dies on the package meant that there was a hop if the data required was in the memory attached to the other silicon. With the second generation Threadripper, it gets a lot more complex.
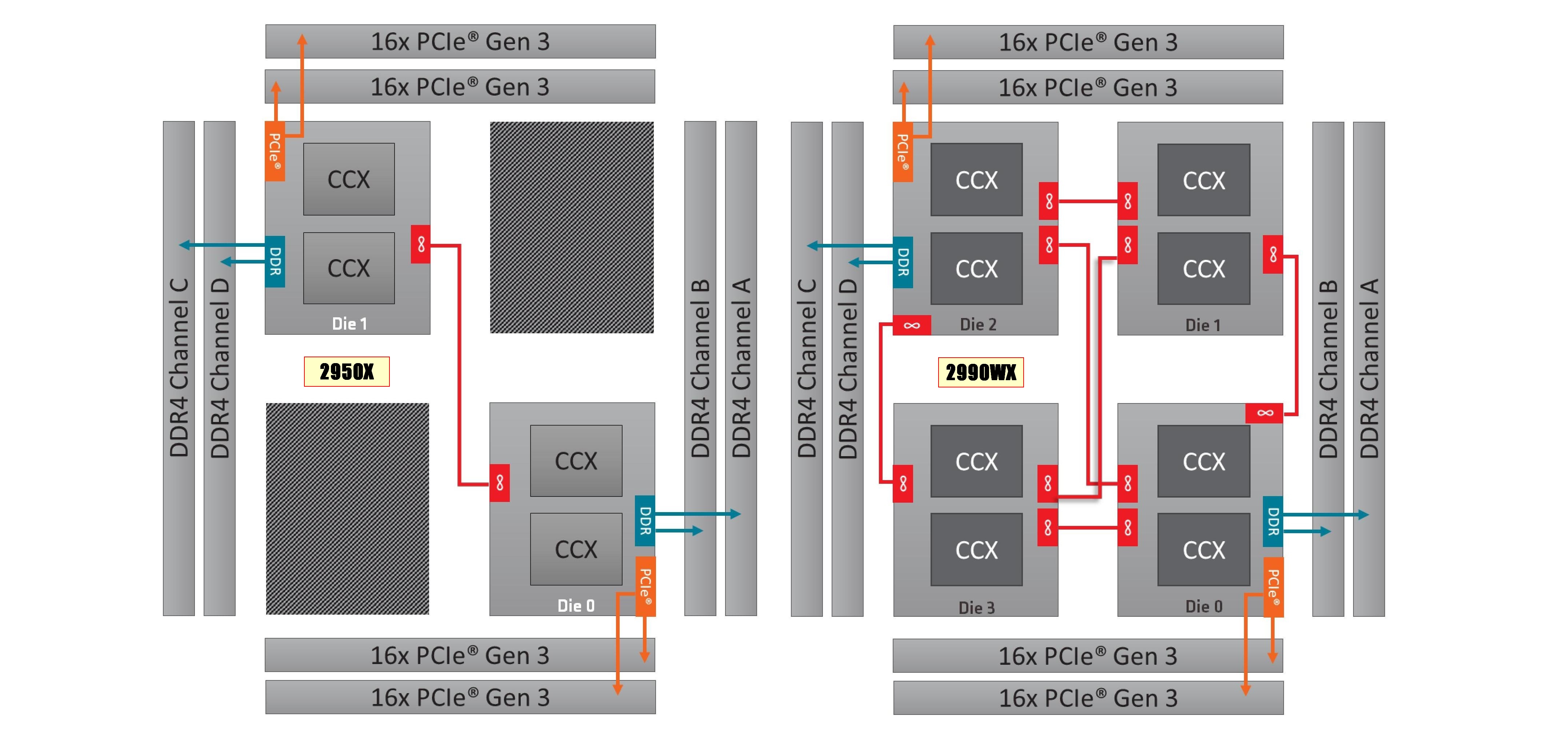
On the left is the 1950X/2950X design, with two active silicon dies. Each die has direct access to 32 PCIe lanes and two memory channels each, which when combined gives 60/64 PCIe lanes and four memory channels. The cores that have direct access to the memory/PCIe connected to the die are faster than going off-die.
For the 2990WX and 2970WX, the two ‘inactive’ dies are now enabled, but do not have extra access to memory or PCIe. For these cores, there is no ‘local’ memory or connectivity: every access to main memory requires an extra hop. There is also extra die-to-die interconnects using AMD’s Infinity Fabric (IF), which consumes power.
The reason that these extra cores do not have direct access is down to the platform: the TR4 platform for the Threadripper processors is set at quad-channel memory and 60 PCIe lanes. If the other two dies had their memory and PCIe enabled, it would require new motherboards and memory arrangements.
Users might ask, well can we not change it so each silicon die has one memory channel, and one set of 16 PCIe lanes? The answer is that yes, this change could occur. However the platform is somewhat locked in how the pins and traces are managed on the socket and motherboards. The firmware is expecting two memory channels per die, and also for electrical and power reasons, the current motherboards on the market are not set up in this way. This is going to be an important point when get into the performance in the review, so keep this in mind.
It is worth noting that this new second generation of Threadripper and AMD’s server platform, EPYC, are cousins. They are both built from the same package layout and socket, but EPYC has all the memory channels (eight) and all the PCIe lanes (128) enabled:
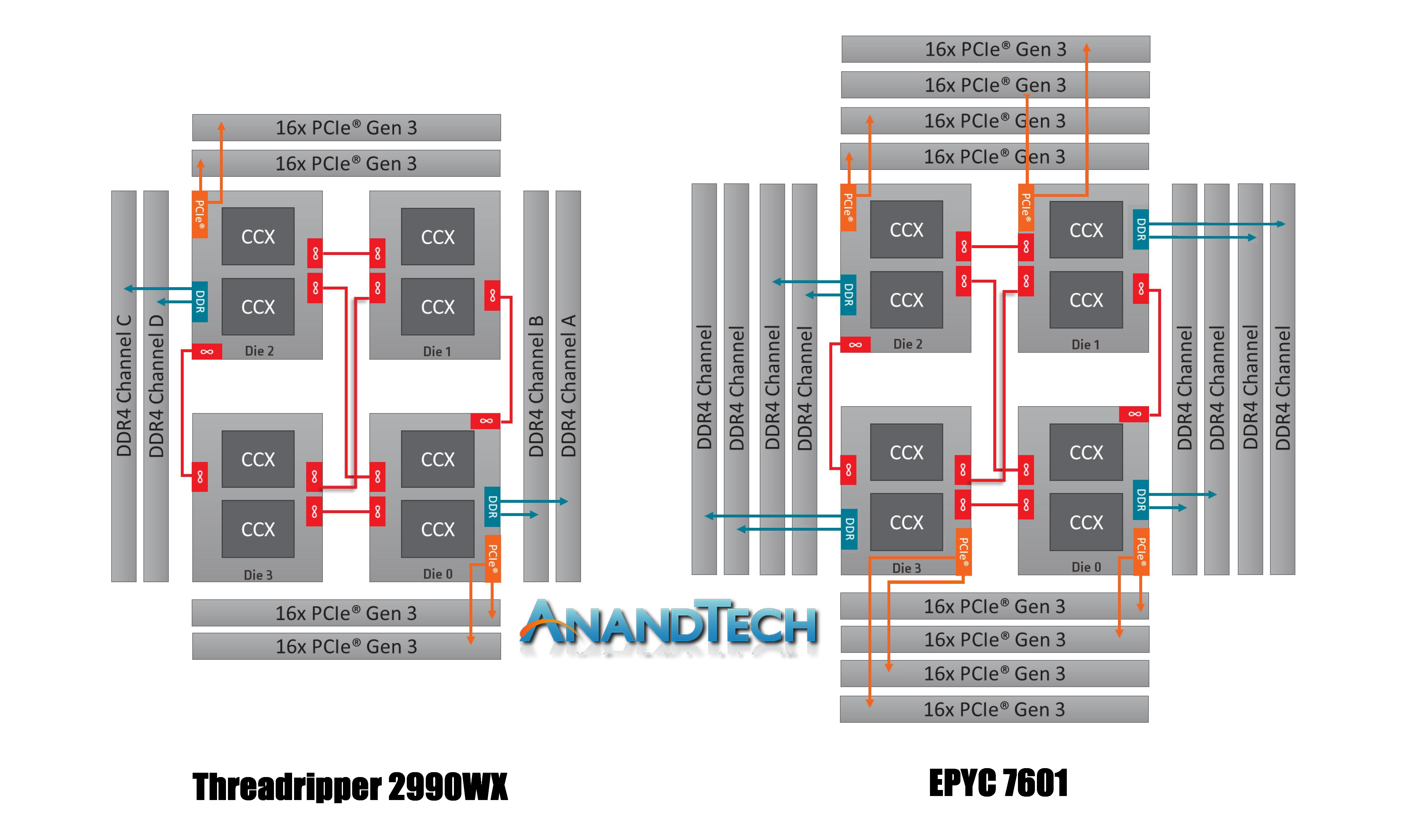
Where Threadripper 2 falls down on having some cores without direct access to memory, EPYC has direct memory available everywhere. This has the downside of requiring more power, but it offers a more homogenous core-to-core traffic layout.
Going back to Threadripper 2, it is important to understand how the chip is going to be loaded. We confirmed this with AMD, but for the most part the scheduler will load up the cores that are directly attached to memory first, before using the other cores. What happens is that each core has a priority weighting, based on performance, thermals, and power – the ones closest to memory get a higher priority, however as those fill up, the cores nearby get demoted due to thermal inefficiencies. This means that while the CPU will likely fill up the cores close to memory first, it will not be a simple case of filling up all of those cores first – the system may get to 12-14 cores loaded before going out to the two new bits of silicon.








171 Comments
View All Comments
edzieba - Monday, August 13, 2018 - link
Not really. In chasing Moar Cores you only excel in embarrassingly parallel workloads. And embarrassingly parallel workloads are in GPGPU's house. And GPU lives in GPGPU's house.boeush - Monday, August 13, 2018 - link
Try to run multiple VMs/Containers and/or multiple desktop sessions on a GPGPU: you might find out that GPGPU's house isn't all it's cracked up to be...SonicKrunch - Monday, August 13, 2018 - link
Look at that power consumption. I'm not suggesting AMD didn't create a really great CPU here, but they really need to work on their efficiency. It's always been their problem, and it's not seemingly going away. The market for these near 2k chips is also not huge in comparison to normal desktop space. Intel has plenty of time to answer here with their known efficiency.The_Assimilator - Monday, August 13, 2018 - link
Yeah... look at the number of cores, numpty.somejerkwad - Monday, August 13, 2018 - link
The same efficiency that has consumer-grade products operating on more electricity in per-core and per-clock comparisons? Overclocking power gets really silly on Intel's high end offerings too, if you care to look at the numbers people are getting with an i9 that has fewer cores.eddman - Monday, August 13, 2018 - link
Interesting, can you post a link, please? I've read a few reviews here and there and when comparing 2600x to 8700k (which is more or less fair), it seems in most cases 8700k consumes less energy, even though it has higher boost clocks.CrazyElf - Monday, August 13, 2018 - link
The 8700k is not the problem. It is Skylake X.https://www.tomshardware.com/reviews/-intel-skylak...
Power consumption when you OC X299 scales up quickly. Threadripper is not an 8700k competitor. It is an X299 competitor. The 32 core AMD is clearly priced to compete against the 7980X, unless Intel cuts the price.
eddman - Tuesday, August 14, 2018 - link
I should've made it clear. I was replying to the "more electricity in per-core and per-clock" part. Also, he wrote consumer-grade, which is not HEDT. I do know that TR competes with SKL-X.Comparing OCing power consumption is rather pointless when one chip is able to clock much higher.
Even when comparing 2950 to 7980, there are a lot of instances where 7980 consumes about the same power or even less. I don't see how ryzen is more efficient.
alpha754293 - Monday, August 13, 2018 - link
@ibnmadhi"It's over, Intel is finished."
Hardly.
For example, the Threadripper 2990WX (32C, 3.0 GHz) gets the highest score in POV-Ray 3.7.1 benchmark, but when you compute the efficiency, it's actually the worst for it.
It consumes more power and only gets about 114 points per (base clock * # of cores - which is a way to roughly estimate the CPU's total processing capability).
By comparison, the Intel Core i9-7980XE (18C, 2.6 GHz) is actually the MOST EFFICIENT at 168 points per (base clock * # of cores). It consumes less power than the Threadripper processors, but it does also cost more.
If I can get a system that can do as much or more for less, both in terms of capital cost and running cost (i.e. total cost of ownership), then why would I want to go AMD?
I use to run all AMD when it was a better value proposition and when Intel's power profile was much worse than AMD's. Now, it has completely flipped around.
Keep also in mind, that they kept the Epyc 7601 processor in here for comparison, a processor that costs $4200 each.
At that price, I know that I can get an Intel Xeon processor, with about the same core count and base clock speed for about the same price, but I also know that it will outperform the Epyc 7601 as well when you look at the data.
As of August, 2018, Intel has a commanding 79.4% market share compared to AMD's 20.6%. That's FARRR from Intel being over.
ender8282 - Monday, August 13, 2018 - link
base clock * number of cores seems like a poor stand in for performance per watt. If we assume that IPC and other factors like mem/cache latency are the same then sure base clock * num cores effectively gives us performance unit of power but we know those are not constant.