The Intel SSD 660p SSD Review: QLC NAND Arrives For Consumer SSDs
by Billy Tallis on August 7, 2018 11:00 AM ESTAnandTech Storage Bench - Heavy
Our Heavy storage benchmark is proportionally more write-heavy than The Destroyer, but much shorter overall. The total writes in the Heavy test aren't enough to fill the drive, so performance never drops down to steady state. This test is far more representative of a power user's day to day usage, and is heavily influenced by the drive's peak performance. The Heavy workload test details can be found here. This test is run twice, once on a freshly erased drive and once after filling the drive with sequential writes.
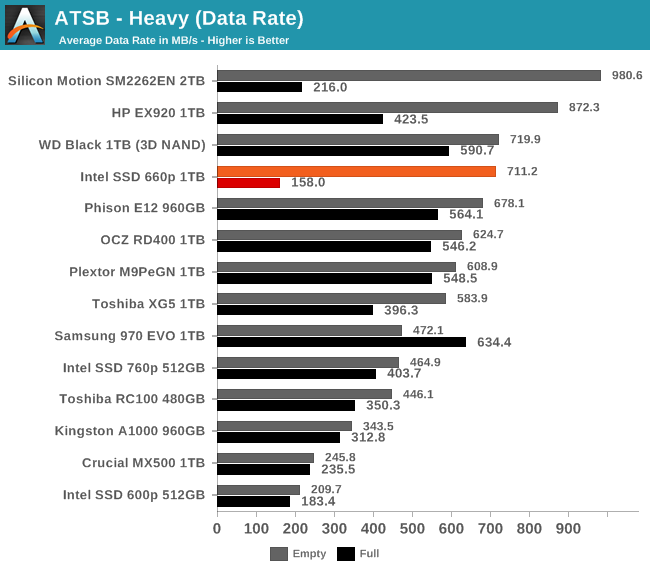
When the Heavy test is run on an empty Intel SSD 660p, the test is able to operate almost entirely within the large SLC cache and the average data rate is competitive with many high-end NVMe SSDs. When the drive is full and the SLC cache is small, the low performance of the QLC NAND shows through with an average data rate that is slower than the 600p or Crucial MX500, but still far faster than a mechanical hard drive.
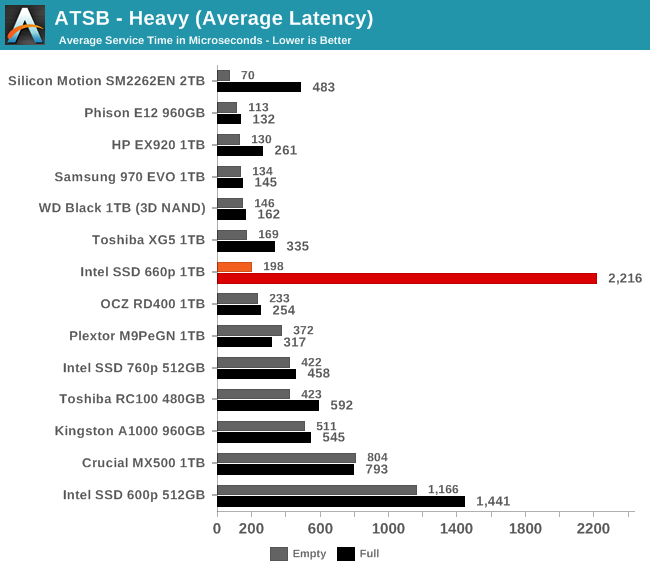
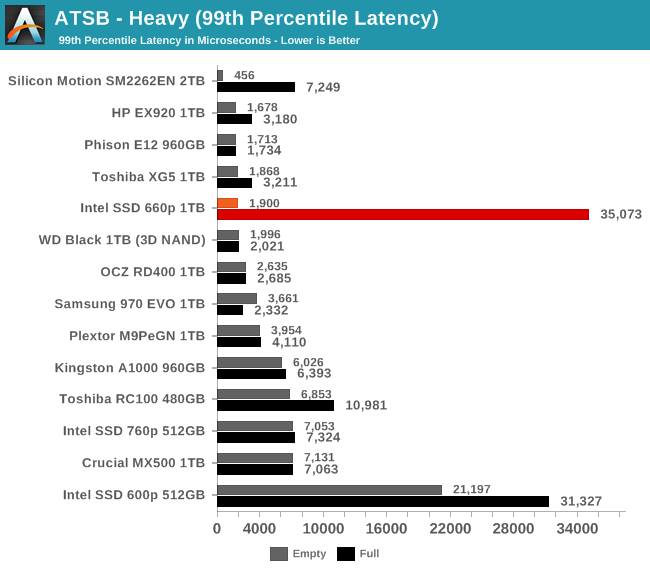
The average and 99th percentile latency scores of the 660p on the empty-drive test run are clearly high-end; the use of a four-channel controller doesn't seem to be holding back the performance of the SLC cache. The full-drive latency scores are an order of magnitude higher and worse than other SSDs of comparable capacity, but not worse than some of the slowest low-capacity TLC drives we've tested.
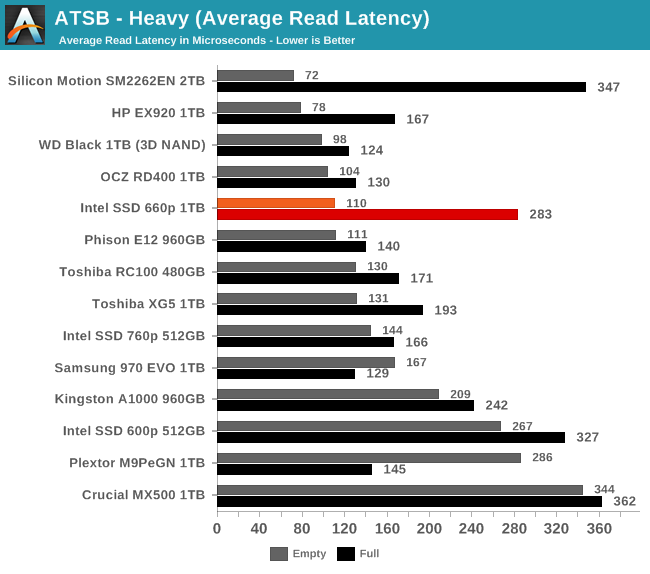
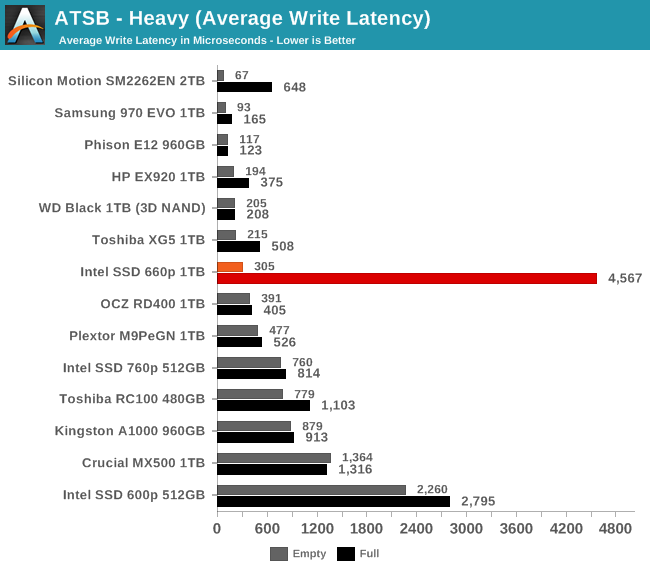
The average read latency of the Intel 660p on the Heavy test is about 2.5x higher for the full-drive test run than when the test is run on a freshly-erased drive. Neither score is unprecedented for a NVMe drive, and it's not quite the largest disparity we've seen between full and empty performance. The average write latency is where the 660p suffers most from being full, with latency that's about 60% higher than the already-slow 600p.
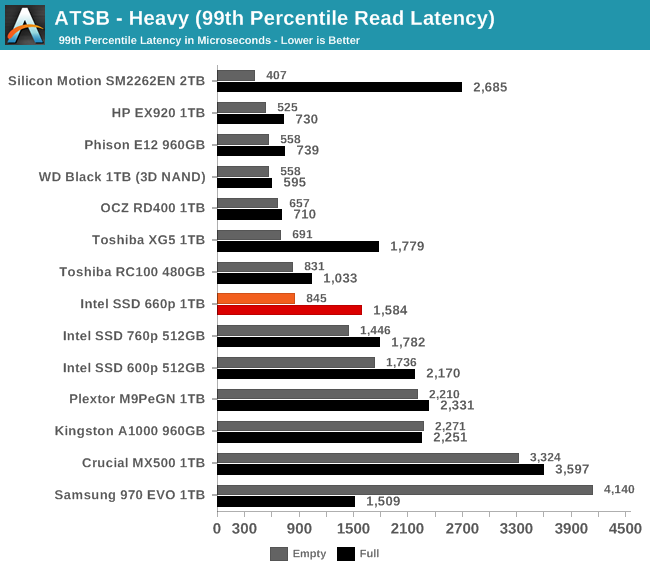
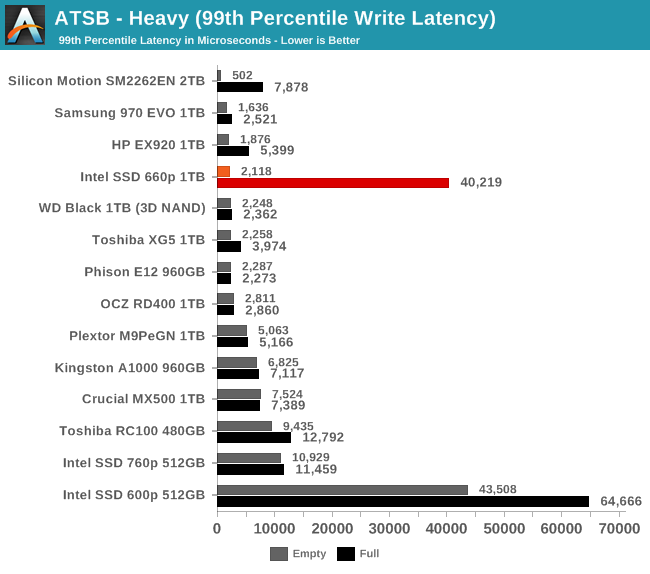
The 99th percentile read latency scores from the 660p are fine for a low-end NVMe drive, and close to high-end for the empty-drive test run that is mostly using the SLC cache. The 99th percentile write latency is similarly great when using the SLC cache, but almost 20 times worse when the drive is full. This is pretty bad in comparison to other current-generation NVMe drives or mainstream SATA drives, but is actually slightly better than the Intel 600p's best case for 99th percentile write latency.
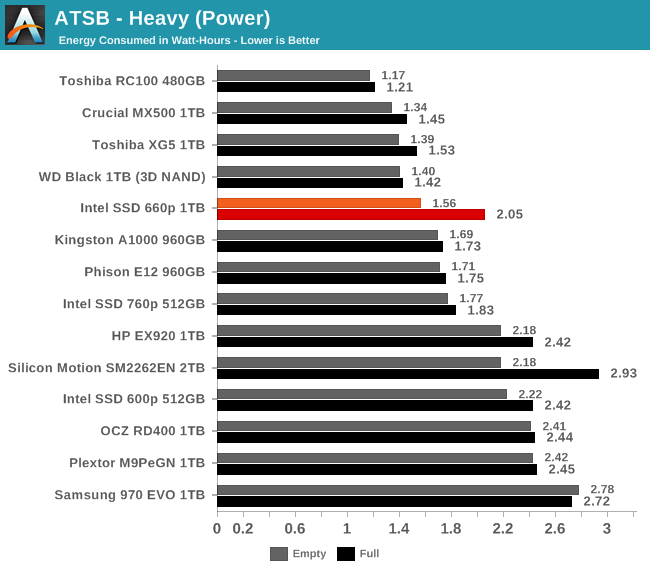
The Intel SSD 660p shows above average power efficiency on the Heavy test, by NVMe standards. Even the full-drive test run energy usage is lower than several high-end drives.








86 Comments
View All Comments
zodiacfml - Wednesday, August 8, 2018 - link
I think the limiting factor for reliability is the electronics/controller, not the NAND. You just lose drive space with a QLC much sooner with plenty of writes.romrunning - Wednesday, August 8, 2018 - link
Given that you can buy 1TB 2.5" HDD for $40-60 (maybe less for volume purchases), and even this QLC drive is still $0.20/GB, I think it's still going to be quite a while before notebook mfgs replace their "big" HDD with a QLC drive. After all, the first thing the consumer sees is "it's got lots of storage!"evilpaul666 - Wednesday, August 8, 2018 - link
Does the 660p series of drives work with the Intel CAS (Cache Acceleration Software)? I've used the trial version and it works about as well as Optane does for speeding up a mechanical HDD while being quite a lot larger.eddieobscurant - Wednesday, August 8, 2018 - link
Wow,this got a recommended award and the adata 8200 didn't. Another pro-intel marketing from anandtech. Waiting for biased threadripper 2 review.BurntMyBacon - Wednesday, August 8, 2018 - link
The performance of this SSD is quite bipolar. I'm not sure I'd be as generous with the award. Though, I think the decision to give out an award had more to do with the price of the drive and the probable performance for typical consumer workloads than some "pro-intel marketing" bias.danwat1234 - Wednesday, August 8, 2018 - link
The drive is only rated to write to each cell 200 times before it begins to wear out? Ewwww.azazel1024 - Wednesday, August 8, 2018 - link
For some consumer uses, yes 100MiB/sec constant write speed isn't terrible once the SLC cache is exhausted, but it'll probably be a no for me. Granted, SSD prices aren't where I want them to be yet to replace my HDDs for bulk storage. Getting close, but prices still need to come down by about a factor of 3 first.My use case is 2x1GbE between my desktop and my server and at some point sooner rather than later I'd like to go with 2.5GbE or better yet 5GbE. No, I don't run 4k video editing studio or anything like that, but yes I do occasionally throw 50GiB files across my network. Right now my network link is the bottleneck, though as my RAID0 arrays are filling up, it is getting to be disk bound (2x3TB Seagate 7200rpm drive arrays in both machines). And small files it definitely runs in to disk issues.
I'd like the network link to continue to be the limiting factor and not the drives. If I moved to a 2.5GbE link which can push around 270MiB/sec and I start lobbing large files, the drive steady state write limits are going to quickly be reached. And I really don't want to be running an SSD storage array in RAID. That is partly why I want to move to SSDs so I can run a storage pool and be confident that each individual SSD is sufficiently fast to at least saturate 2.5GbE (if I run 5GbE and the drives can't keep up, at least in an SLC cache saturated state, I am okay with that, but I'd like them to at least be able to run 250+ MiB/sec).
Also although rare, I've had to transfer a full back-up of my server or desktop to the other machine when I've managed to do something to kill the file copy (only happened twice over the last 3 years, but it HAS happened. Also why I keep a cold back-up that is updated every month or two on an external HDD). When you are transferring 3TiB or so of data, being limited to 100MiB/sec would really suck. At least right now when that happens I can push an average of 200MiB/sec (accounting for some of it being smaller files which are getting pushed at more like 80-140MiB/sec rather than the 235MiB/sec of large files).
That is a difference from close to 8:30 compared to about 4:15. Ideally I'd be looking at more like 3:30 for 3TiB.
But, then again, looking at price movement, unless I win the lottery, SSD prices are probably going to take at least 4 or more likely 5-6 years before I can drop my HDD array and just replace it with SSDs. Heck, odds are excellent I'll end up replacing my HDD array with a set of even faster 4 or 6TiB HDDs before SSDs are closer enough in price (closer enough to me is paying $1000 or less for 12TB of SSD storage).
That is keeping in mind that with HDDs I'd likely want utilized capacity under 75% and ideally under 67% to keep from utilizing those inner tracks and slowing way down. With SSDs (ignoring the SLC write cache size reductions), write penalties seem to be much less. Or at least the performance (for TLC and MLC) is so much higher than HDDs to start with, that it still remains high enough not to be a serious issue for me.
So an SSD storage pool could probably be up around 80-90% utilized and be okay, where as a HDD array is going to want to be no more than 67-75% utilized. And also in my use case, it should be easy enough to simply slap in another SSD to increase the pool size, with HDDs I'd need to chuck the entire array and get new sets of matched drives.
iwod - Wednesday, August 8, 2018 - link
On Mac, two weeks of normal usage has gotten 1TB of written data. And it does 10-15GB on average per day.100TB endurance is nothing.......
abufrejoval - Wednesday, August 8, 2018 - link
I wonder if underneath the algorithm has already changed to do what I’d call the ‘smart’ thing: Essentially QLC encoding is a way of compression (brings back old memories about “Stacker”) data 4:1 at the cost of write bandwidth.So unless you run out of free space, you first let all data be written in fast SLC mode and then start compressing things into QLC as a background activity. As long as the input isn’t constantly saturated, the compression should reclaim enough SLC mode blocks faster on average after compression than they are filled with new data. The bigger the overall capacity and remaining cache, the longer the burst it can sustain. Of course, once the SSD is completely filled the cache will be whatever they put into the spare area and updates will dwindle down to the ‘native’ QLC write rate of 100MB/s.
In a way this is the perfect storage for stuff like Steam games: Those tend to be hundreds of gigabytes these days, they are very sensitive to random reads (perhaps because the developers don’t know how to tune their data) but their maximum change rate is actually the capacity of your download bandwidth (wish mine was 100MB/s).
But it’s also great for data warehouse databases or quite simply data that is read-mostly, but likes high bandwidth and better latency than spinning disks.
The problem that I see, though, is that the compression pass needs power. So this doesn’t play well with mobile devices that you shut off immediately after slurping massive amounts of data. Worst case would be a backup SSD where you write and unplug.
The specific problem I see for Anandtech and technical writers is that you’re no longer comparing hardware but complex software. And Emil Post proved in 1946, that it’s generally impossible.
And with an MRAM buffer (those other articles) you could even avoid writing things at SLC first, as long as the write bursts do not overflow the buffer and QLC encoding empties it faster on average that it is filled. Should a burst overflow it, it could switch to SLC temporarily.
I think I like it…
And I think I would like it even better, if you could switch the caching and writing strategy at the OS or even application level. I don’t want to have to decide between buying a 2TB QLC, 1TB TLC, a 500GB MLC or 250GB SLC and then find out I need a little more here and a little less there. I have knowledge at the application (usage level), how long-lived my data will be and how it should best be treated: Let’s just use it, because the hardware internally is flexible enough to support at least SLC, TLC and QLC.
That would also make it easier to control the QLC rewrite or compression activity in mobile or portable form factors.
ikjadoon - Thursday, August 9, 2018 - link
Billy, thank you!I posted a reddit comment a long time ago about separating SSD performance by storage size! I might be behind, but this is the first I’ve seen of it. It’s, to me, a much more reliable graph for purchases.
A big shout out. 💪👌