Arm's Cortex-A76 CPU Unveiled: Taking Aim at the Top for 7nm
by Andrei Frumusanu on May 31, 2018 3:01 PM EST- Posted in
- CPUs
- Arm
- Smartphones
- Mobile
- SoCs
- Cortex-A76
Cortex A76 µarch - Backend
Switching to the back-end of the core we have a look at the execution core.

The integer core contains 6 issue queues and execution ports (4 depicted in the slide plus 2 load/store pipelines). There are 3 integer execution pipelines – two ALUs capable of simple arithmetic operations and a complex pipeline handling also multiplication, division and CRC ops. The three integer pipelines are served by 16 deep issue queues. The same size issue queue can also be found serving the single branch execution port.
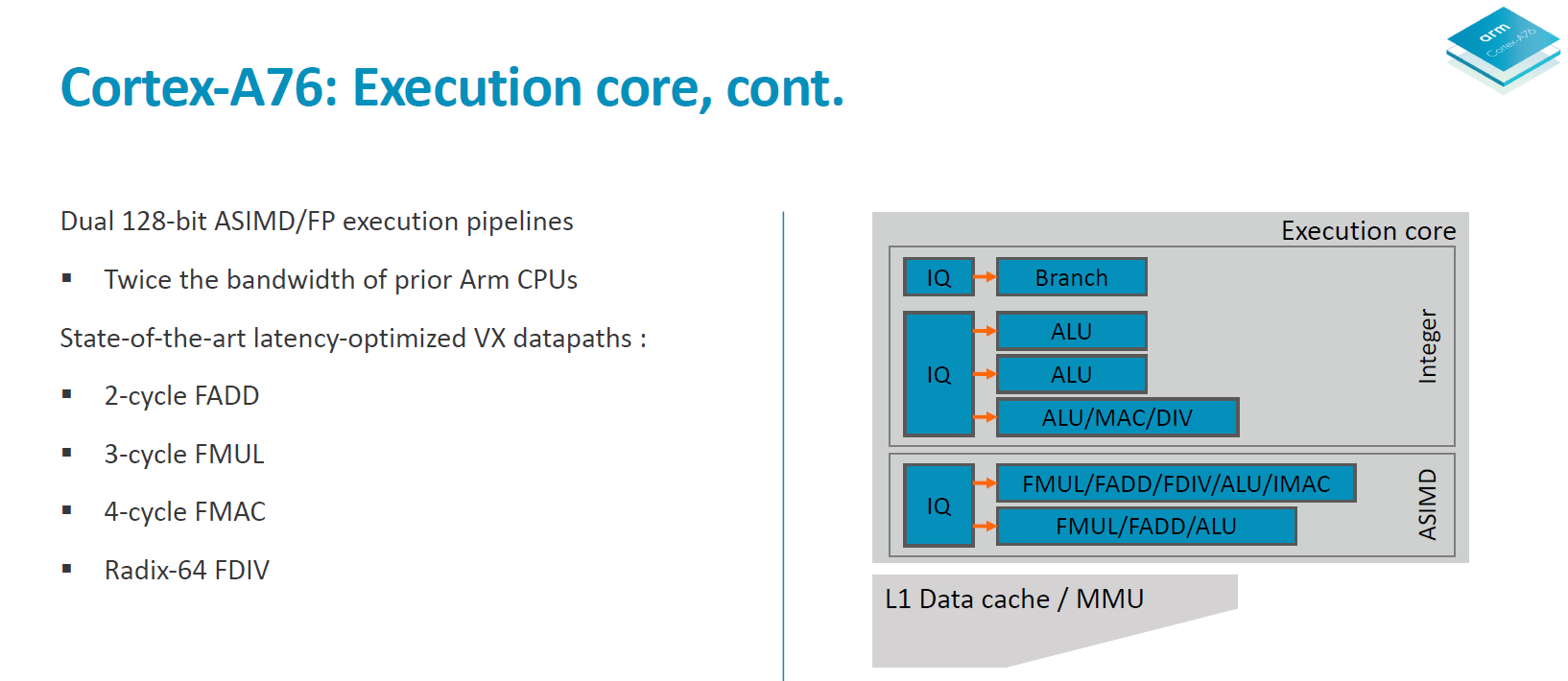
Two load/store units are the remaining ports of the integer core and are each served by two 12 deep issue queues. The issue queue stages are 3 cycles deep and while I mentioned that the rename/dispatch is 1 stage deep, the dispatch stage actually overlaps with the first cycle of the issue queues stages.
The ASIMD/floating point core contains two pipelines which are served by two 16-deep issue queues.
When it comes to the backend of a CPU core the two most important metrics are instruction throughput and latency. Where the A76 in particular improves a lot is in terms of instruction latency as it’s able to shave off cycles on very important instructions.
To better overview the improvements I created a table with the most common instruction types. The execution throughput and latencies presented here are for AArch64 instructions and if not otherwise noted represent operations on 64-bit data for integer and 64bit (double precision) FP.
| Backend Execution Throughput and Latency | ||||||
| Cortex-A75 | Cortex-A76 | Exynos-M3 | ||||
| Exec | Lat | Exec | Lat | Exec | Lat | |
| Integer Arithmetic (Add, sub) | 2 | 1 | 3 | 1 | 4 | 1 |
| Integer Multiply 32b | 1 | 3 | 1 | 2 | 2 | 3 |
| Integer Multiply 64b | 1 | 3 | 1 | 2 | 1 (2x 0.5) |
4 |
| Integer Multiply Accumulate | 1 | 3 | 1 | 2 | 1 | 3 |
| Integer Division 32b | 0.25 | 12 | 0.2 | < 12 | 1/12 - 1 | < 12 |
| Integer Division 64b | 0.25 | 12 | 0.2 | < 12 | 1/21 - 1 | < 21 |
| Move (Mov) | 2 | 1 | 3 | 1 | 3 | 1 |
| Shift ops (Lsl) | 2 | 1 | 3 | 1 | 3 | 1 |
| Load instructions | 2 | 4 | 2 | 4 | 2 | 4 |
| Store instructions | 2 | 1 | 2 | 1 | 1 | 1 |
| FP Arithmetic | 2 | 3 | 2 | 2 | 3 | 2 |
| FP Multiply | 2 | 3 | 2 | 3 | 3 | 4 |
| FP Multiply Accumulate | 2 | 5 | 2 | 4 | 3 | 4 |
| FP Division (S-form) | 0.2-0.33 | 6-10 | 0.66 | 7 | >0.16 (2x 1+/12) |
12 |
| FP Load | 2 | 5 | 2 | 5 | 2 | 5 |
| FP Store | 2 | 1-N | 2 | 2 | 2 | 1 |
| ASIMD Arithmetic | 2 | 3 | 2 | 2 | 3 | 1 |
| ASIMD Multiply | 1 | 4 | 1 | 4 | 1 | 3 |
| ASIMD Multiply Accumulate | 1 | 4 | 1 | 4 | 1 | 3 |
| ASIMD FP Arithmetic | 2 | 3 | 2 | 2 | 3 | 2 |
| ASIMD FP Multiply | 2 | 3 | 2 | 3 | 1 | 3 |
| ASIMD FP Chained MAC (VMLA) | 2 | 6 | 2 | 5 | 3 | 5 |
| ASIMD FP Fused MAC (VFMA) | 2 | 5 | 2 | 4 | 3 | 4 |
On the integer operations side the A76 improves the multiplication and multiply accumulate latencies from 3 cycles down to 2 cycles, with the throughput remaining the same when compared to the A75. Obviously because the A76 has 3 integer pipelines simple arithmetic operations see a 50% increase in throughput versus the A75’s 2 pipelines.
The much larger and important improvements can be found in the “VX” (vector execution) pipelines which are in charge of FP and ASIMD operations. Arm calls the new pipeline a “state-of-the-art” design and this is finally the result that’s been hyped up for several years now.
Floating point arithmetic operations have been reduced in latency from 3 cycles down to 2 cycles, and multiply accumulate has also shaved off a cycle from 5 cycles down to 4.
What Arm means by the “Dual 128bit ASIMD” with doubled execution bandwidth is that for the A75 and prior only one of the vector pipelines was capable of 128bit while the other one was still 64-bit. For the A76 both vector pipelines are 128-bit now so quad-precision operations see a doubling of the execution throughput.
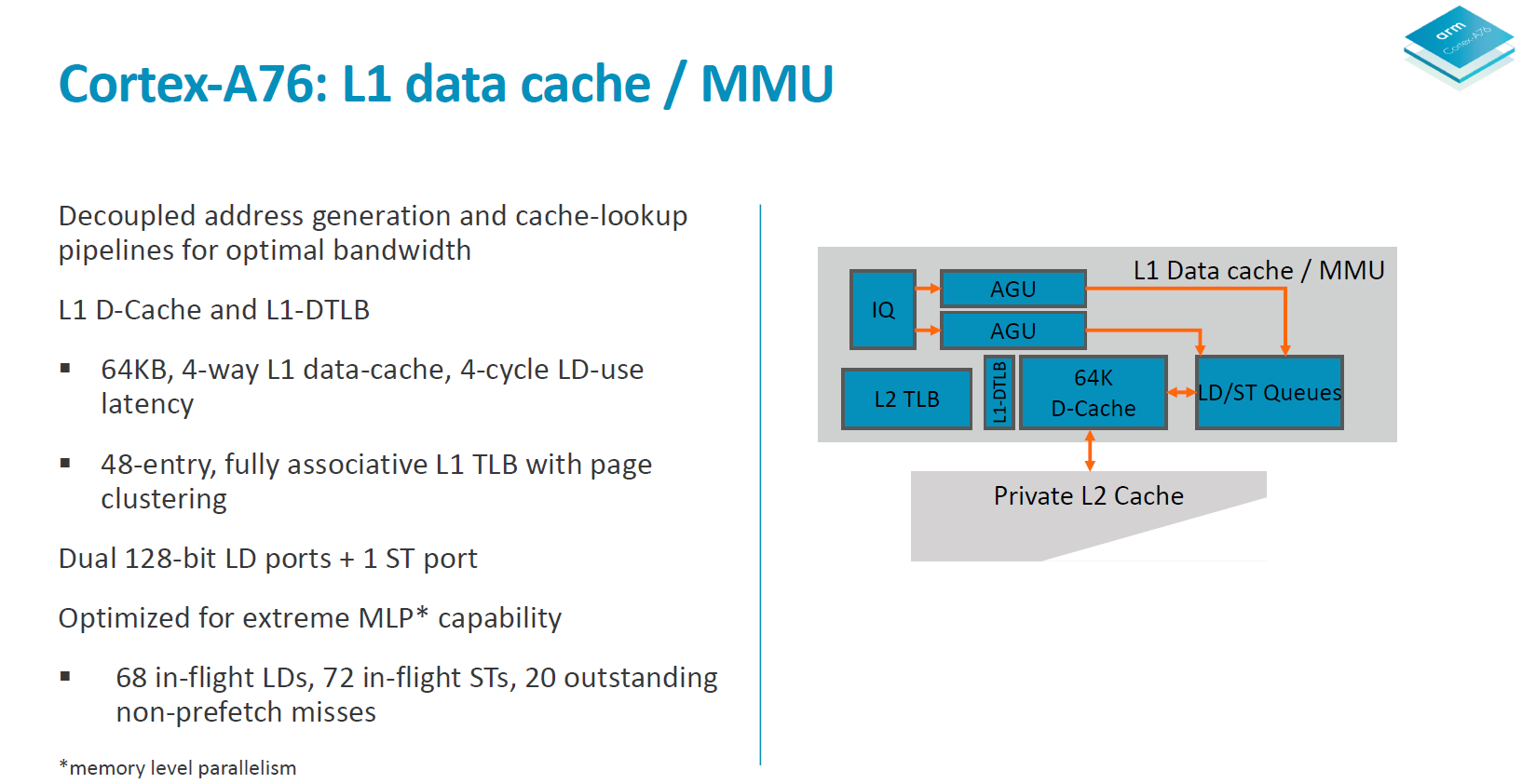
Moving onto more details of the data handling side, we see the again the two load/store pipelines which was something first implemented on the A73 and A75. Although depicted as one issue queue in the slide, the LD/S pipelines each have their own queues at 16 entries deep.
The data cache is fixed at 64KB and is 4-way associative. Load latency remains at 4 cycles. The DTLBs run a separate pipeline as tag and data lookup. Arm’s goals here is aiming for maximum MLP/ memory level parallelism to be able to feed the core.
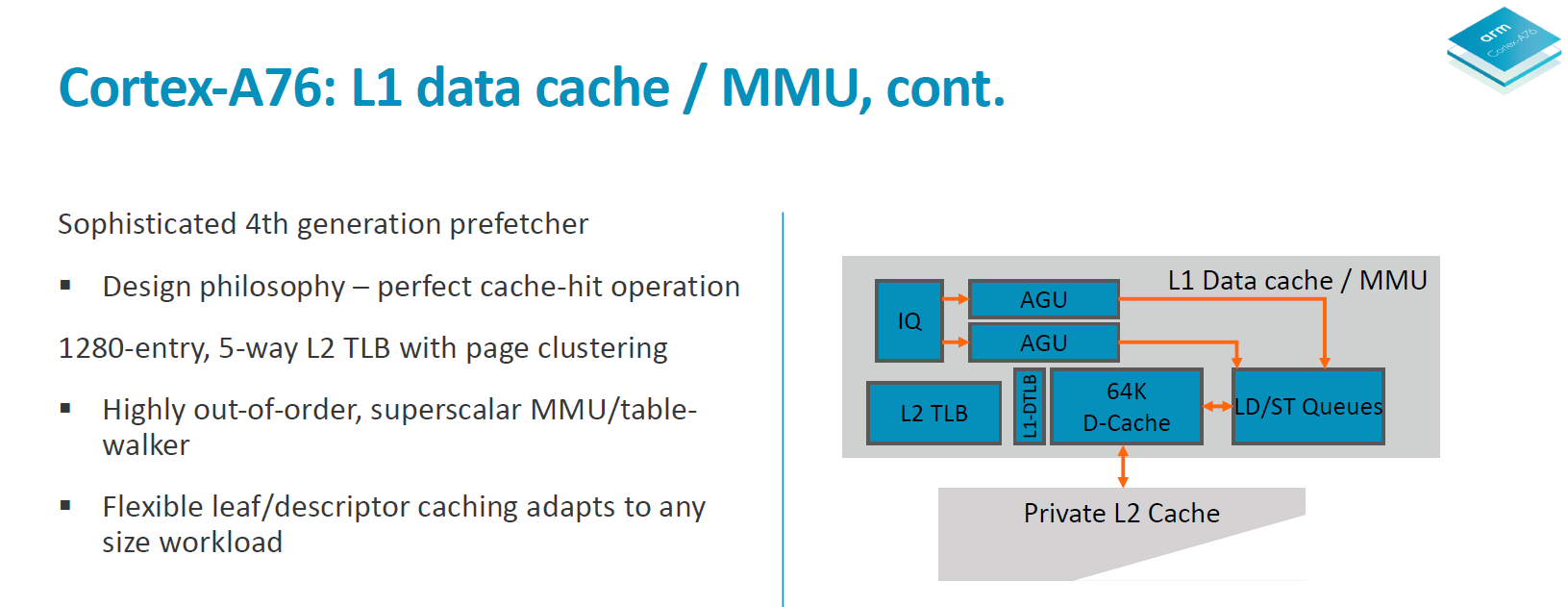
In a perfect machine everything would be already located in the caches, so it’s important to have very robust prefetching capabilities. On the A76 we see a new 4th generation prefetchers introduced to get nearer to this goal of perfect cache-hit operation. In all the A76 has 4 different prefetching engines running in parallel looking at various data patterns and loading data into the caches.
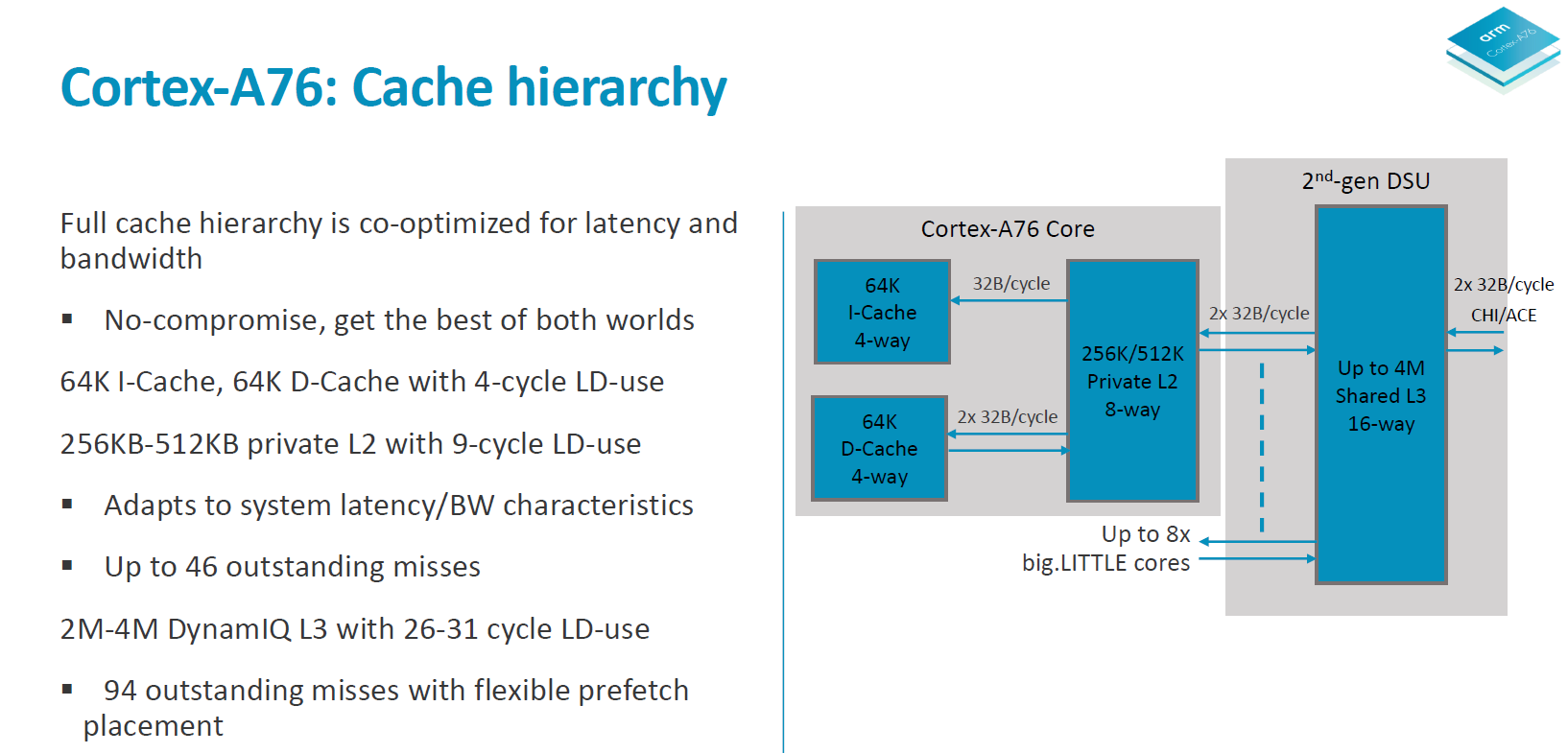
In terms of the A76 cache hierarchy Arm is said to have made no compromises and got the best of both worlds in terms of bandwidth and latency. The 64KB L1 instruction cache reads up to 32B/cycle and the same bandwidth applies to the L1 data cache in both directions. The L1 is a writeback cache. The L2 cache is configurable in 256 or 512KB sizes and is D-side inclusive with the same 2x 32B/cycle write and read interfaces up to the exclusive L3 cache in the 2nd generation DSU.
Overall the microarchitectural improvements on the core are said to improve memory bandwidth to DRAM by up to 90% in microbenchmarks.

All in all the microarchitecture of the A76 could be summed up in a few focus design points: Maximise memory performance throughout the core by looking at every single cycle. During the design phase the engineers were looking at feature changes with a sensitivity of up to 0.25% in performance or power – if that metric was fulfilled then it was deemed to be a worthwhile change in the core. Small percentages then in turn add up to create significant figures in the end product.
The focus on bandwidth on latency is said to have been extreme, and Arm was very adamant in re-iterating that to be able to take full advantage of the microarchitecture that vendors need to implement an equally capable memory subsystem on the SoC to see full advantages. A figure that was put out there was 0.25% of performance per nanosecond of latency to main memory. As we’ve seen in the Snapdragon 845 one of the reasons the SoC didn’t quite reach Arm’s projected performance metrics was the degraded memory latency figures which might have been introduced by the L4 system cache in the SoC. In the future vendors will need to focus more on providing latency sensitive memory subsystems as otherwise they’ll be letting free performance and power on the table with differences that could amount to basically a generational difference in CPU IP.








123 Comments
View All Comments
lmcd - Friday, June 1, 2018 - link
They're at the mercy of chipmakers. The only companies that would buy such a core have already left reference designs behind. Everyone else wants small, cheap chips, so much so that we've had A53-only designs in the entire middle-and-lower range. Will anyone even use the A76? I don't know if that's guaranteed.vladx - Friday, June 1, 2018 - link
Read the last part of the article, it's almost guaranteed next Kirin is skipping the A75.and going directly to A76. I think Huawei is done playing catch-up.darkich - Friday, June 1, 2018 - link
It's so frustrating how even you people who are into SoC's already forget that Apple was basically cheating the customers with secret huge compromises, just to be able to put unbalanced and owerpowered cores in the iPhones.Zoolookuk - Friday, June 1, 2018 - link
Wow, I've seen some seriously bad anti-Apple comments over the last 30 years, but this is probably the best one yet. A10 and A11 are not unbalanced and not 'cheating' customers. Anyone with half a brain can the history of this advantage Apple has started with A7, which was the first 64-bit ARM-based SoC in phones. Ever since they, they've been consistently 2 generations ahead of the competition, and that gap shows no sign of closing.The comments below this that 'at 3ghz' the (still unreleased) A76 would 'only need a 20% boost' to match last year's A11 is pretty funny. So a chip already at its thermal and power limit "only" needs to be overclocked by 20% to match a chip designed two years ago running 40% slower.
techconc - Tuesday, June 5, 2018 - link
Actual device performance easily disproves your claim. Your comment isn't helpful and you would have more credibility if you at least attempted to justify the claim you made.jjj - Friday, June 1, 2018 - link
In reality Apple is the one behind but won't bother to explain, just remember the core count for Apple's solutions.Anyway, A76 at 3GHz and 750mW per core would require less than a 20% boost in clocks to match Apple's A11 in Geekbench.
Apple has only 2 large cores and when including the 4 small ones, the SoC throttles hard under 100% load
If that is what you want, A76 should be able to deliver something close enough when configured as dual core with stupid high clocks. A SoC vendor could push A76 to 2W-3W per core instead of 0.75W and get clocks as high as possible.
But maybe it's better to have more than enough perf, 4 cores and sane efficiency.
Lolimaster - Friday, June 1, 2018 - link
Please stop using geekbench as a comparison tool specially between 2 different ARM ecosystems.jjj - Friday, June 1, 2018 - link
You have results for Apple on anything else?Elstar - Friday, June 1, 2018 - link
Because, crazy as it sounds, most ARM's customers don't want fast off the shelf designs, at least at first. ARM's whole business model is rather simple: they sell simple, affordable, efficient, and feature rich reference designs as a "gateway drug". Once you get hooked on their ecosystem, then they charge a lot for nontrivial customization.name99 - Friday, June 1, 2018 - link
This is like asking "why doesn't Apple come out with a 5GHz A12?" It's not so much that they can't as that this does not make sense for their business model.You can SAY that you want (and would be willing to pay for) Apple level's of performance, but is that really true? God knows Android people complain all the time about how expensive Apple products are, and they MOSTLY buy the midrange phones, not the high end phones. Essential just went bust assuming that more people want to pay for high end Android phones than actually exist.