Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
The ThunderX2 SKUs: 16 to 32 Cores
The SKU inside our test system was the ThunderX2 CN9980 2.2. This is the top SKU that is available right now, offering 32 cores at 2.2 GHz, which are able to further boost to 2.5 GHz.
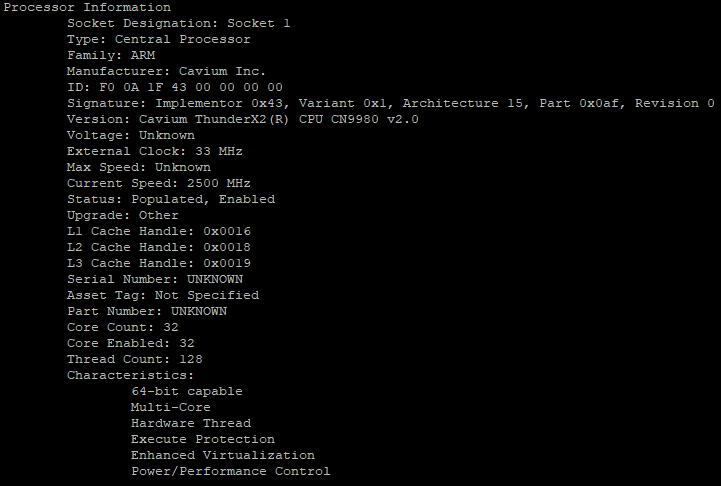
According to Cavium's plans, many more SKUs will be available in the coming months. Cavium claims that a CN9980 at 2.5 GHz will be available soon, which would be capable of boosting to 3 GHz.
Cavium has listed all of their planned SKUs together alongside the comparable Intel SKU. By Cavium's definition, a comparable Intel SKU is a chip that achieves the same SPECInRate (2017) under gcc as Cavium's SKU.
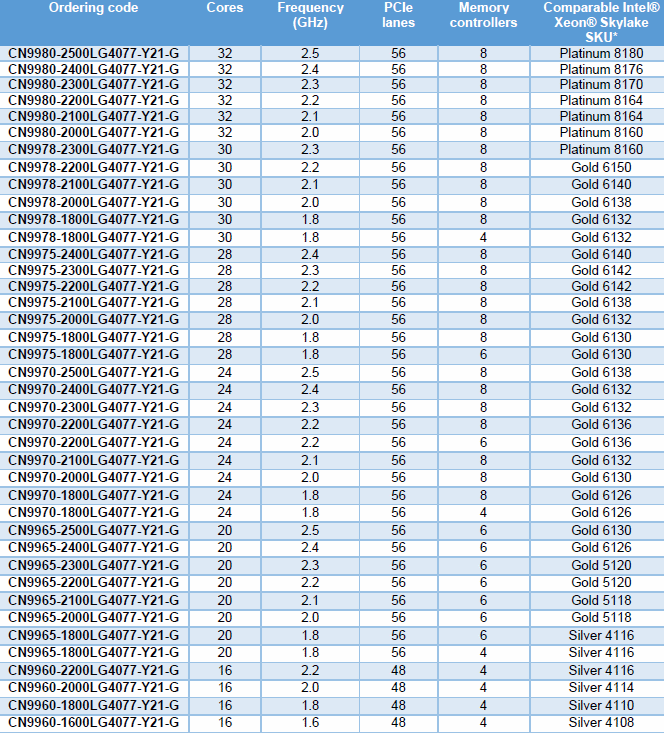
As you can see, Cavium considers our CN9880 2.2 to be comparable to the much more expensive 8164. For our testing we will compare it to the 8176, as that was the Intel SKU available to us. Not that it should matter much: the 8176 only has a 3% higher clockspeed and 2 additional cores (+7%) over the 8164. Note however that if Cavium's ThunderX2 can really compete with these Intel SKUs, they are offering the same performance at one third of the cost of the Intel SKUs.








97 Comments
View All Comments
Wilco1 - Wednesday, May 23, 2018 - link
You might want to study RISC and CISC first before making any claims. RISC doesn't use more instructions than CISC. Vector instructions are actually quite similar on most ISAs. In fact I would say the Neon ones are more powerful and more general due to being well designed rather than added ad-hoc.HStewart - Wednesday, May 23, 2018 - link
The following site explain the difference using a simple multiply action, where a CISC architecture can do in single instruction, RISC would need to use multiple instructionshttp://www.firmcodes.com/difference-risc-sics-arch...
of course as time move on RISC chips added more complex operations and CISC also found ways to breaking more complex CISC instruction in smaller RISC like microcode increasing the chip ability to multitask the pipeline.
Wilco1 - Thursday, May 24, 2018 - link
The example was about load/store architecture, not multiply. In reality almost all instructions use registers (even on CISCs) since memory is too slow, so it's not a good example of what happens in actual code. The number of executed instructions on large applications is actually very close. The key reason is that compilers avoid all the complex instructions on x86 and mostly use register operations, not memory.Kevin G - Tuesday, May 29, 2018 - link
Raw instruction counts isn't a good metric to determine the difference between RISC and CISC, especially as both have evolved to include various SIMD and transactional extensions.The big thing for RISC is that it only supports a handful of instruction formats, generally all of the same length (traditionally 4 bytes)* and have alignment rules in place. x86 on the other hand leverages a series of prefixes to enhance instructions which permits length up to 15 bytes. On the flip side, there are also x86 instructions that consume a single byte. This also means x86 doesn't have the alignment rules that RISC chips generally adhere to.
*ARM does offer some compressed instruction formats in Thumb/Thumb2 but they those are also of a fixed length. 16 bit Thumb instructions are half size as 32 bit ARM instructions and have alignment rules as well.
Modern x86 is radically different internally than its philosophical lineage. x86 instructions are broken down into micro-ops which are RISC-like in nature. These decoded instructions are now being cached to bypass the complex and power hungry decode stages. Compare this to some ARM cores where some instructions do not have to be decoded. While having a simpler decode doesn't directly help with performance, it does impact power consumption.
However, I would differ and say that ARM's FPU and vector history has been rather troubled. Initially ARM didn't specify a FPU but rather a method to add coprocessors. This lead to 3rd parties producing ARM cores with incompatible FPUs. It wasn't until recently that ARM themselves put their foot down and mandated NEON as the one to rule them all, especially in 64 bit mode.
peevee - Wednesday, May 23, 2018 - link
The whole RISC vs CISC distinction is outdated for at least 20 years. Both now include a shi(p)load of instruction far outnumbering original CISC processors like 68000 and 8088 (from the epoch of the whole CISC vs RISC discussion), and both have a lot of architectural registers (which on speculative OoO CPUs are not even the same as real register files). ARMv8 for example includes NEON instructions, which is like... "AVX-128" (or SSE3 or smth).A lot of instructions means that both have to have huge decoders, which limits how small the CPU can be (because any reduction in other hardware which decrease performance faster than cost). For 64-bit ARMv8.2 it is very unlikely than an implementation can be made smaller than A55, and it is a huge core (in transistors) compared to even Pentium, let alone 8088.
HStewart - Wednesday, May 23, 2018 - link
I think the big difference between SIMD technologies - even though ARM has included they are not as wide as instructions as Intel or AMD. The following link appears to have a good comparison of chip SIMD comparison in size, To me in looks like AMD is on AVX level 8/16 instead of 16/32 in current chips while ARM including Neon is 4 Wide which is actually less than Core 2 SSE instructions from 10 years ago.https://stackoverflow.com/questions/15655835/flops...
It also interesting to note Ryzen stats - which I heard that AMD implement AVX 256 by combine two 128 together
One thing is that both Intel and AMD CPUs have grown a long ways since 20 years ago. In fact even todays Atom's can out rune most core-2 CPU's from 10 years - not my Xeon 5160 however.
ZolaIII - Thursday, May 24, 2018 - link
It's 2x128 NEON SIMD per ARM A75 core which goes into your smartphone.Even with smaller SIMD utilising TBL QC Centriq is able to beat up an Xerox Gold.
https://blog.cloudflare.com/neon-is-the-new-black/
Wilco1 - Thursday, May 24, 2018 - link
Modern Arm cores have 2-3 128-bit SIMD units, so 16-24 SP FLOPS/cycle. About half of Skylake theoretical flops, and yet they can match or beat Skylake on many HPC codes. Size is not everything...peevee - Thursday, May 24, 2018 - link
"ARM including Neon is 4 Wide which is actually less than Core 2 SSE instructions from 10 years ago"How is it less? It is the same 128 bits, 2x64 or 4x32 or 2x16...
And AMD combines 2 AVX-256 operations (not 2 128-bit SSEs) to get AVX-512.
patrickjp93 - Friday, May 25, 2018 - link
AMD does NOT have AVX-512. They combine 2 128s into a 256 on Ryzen, ThreadRipper, and Epyc.