Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
ThunderX: From Small & Simple to Wide & Complex
As a brief recap, the original ThunderX was an improved version of the Octeon III: a dual-issue in-order CPU core with two short pipelines.
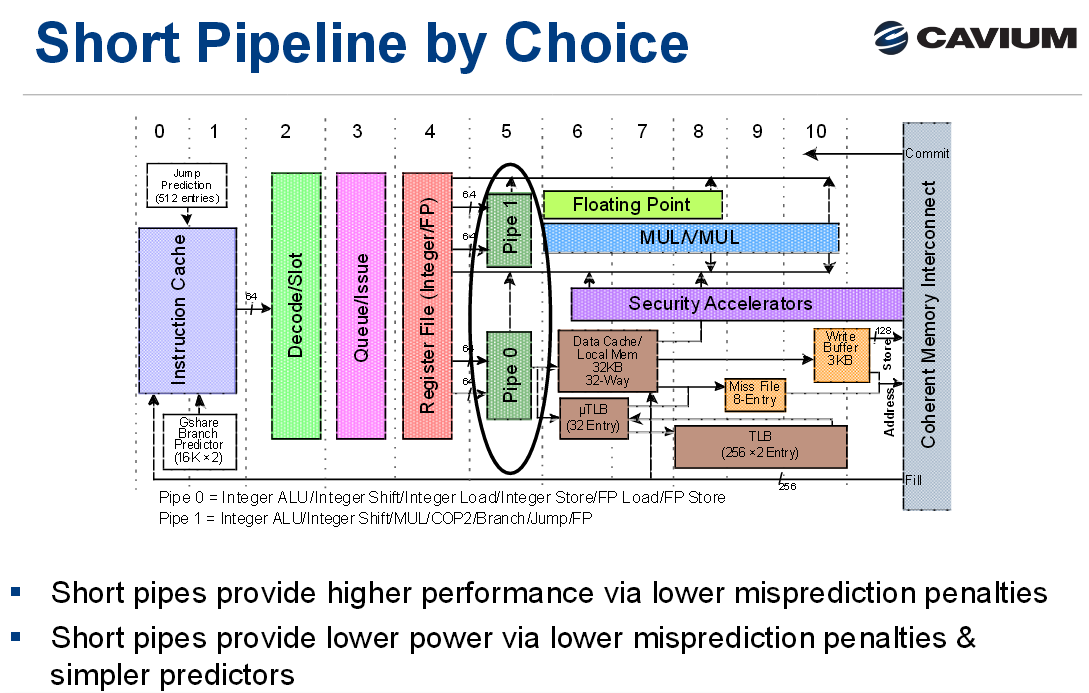
The advantage of the original ThunderX design is that such a simple core can be very energy efficient, especially for "low ILP" (instruction level parallelism) workloads such as web servers and most database servers. Of course, such a short pipeline limits the clockspeed, and such a simple in-order design offers low single threaded performance in medium and high ILP workloads, whereas more advanced out-of-order processors can extract significant parallelism.
Cavium's "New" Core: Vulcan
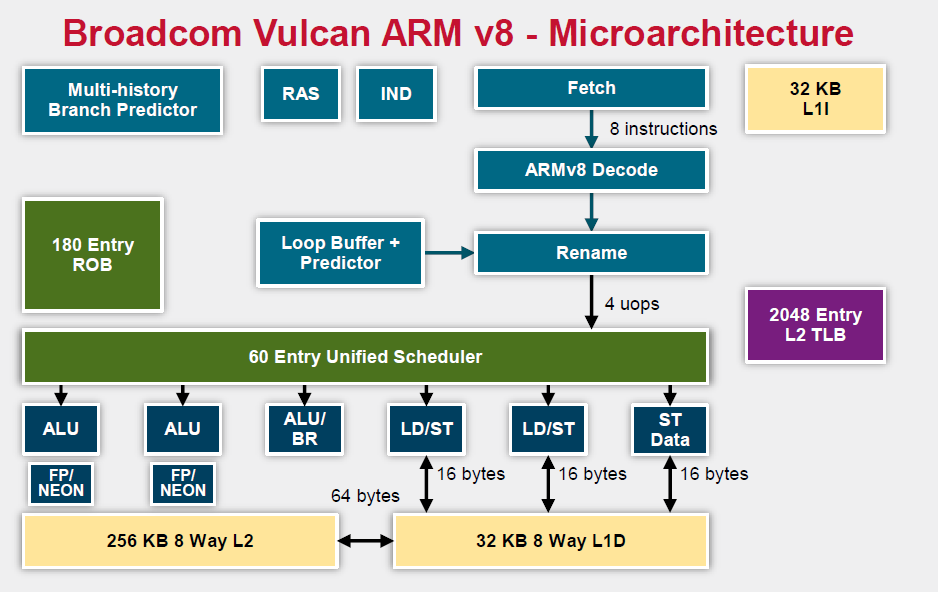
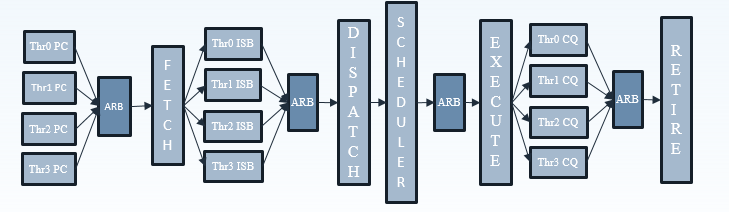
Relative to the original ThunderX, the Vulcan core of the ThunderX2 is an entirely different beast. Announced in 2014 by Broadcom, it is a relatively wide core that runs 4 simultaneous threads (SMT4). As a result, the wide back end should be quite busy even when running low-ILP server workloads.
To make sure that all 4 SMT threads can be sustained, the ThunderX2 front-end can fetch up to 64 bytes from the 8-way set associative 32 KB instruction cache, which is outfitted with a simple next line prefetcher. However, fetching 8 instructions is only possible if there is no taken branch inside those 64 bytes. In that case, the fetch breaks off at the taken branch.
That means that in branch intensive code (databases, AI...) the fetcher will get +/- 5 instructions per clock cycle on average, as one out of 5 instructions is a branch. The fetched instructions are then sent to a smoothing buffer – a buffer where the fetched instructions are held for decoding.
The decoder will then work on a bundle of 4 instructions. Between the decoder and the rename phase each thread has "skid buffer" which consists of 8 bundles. So between the 4 threads up to 32 bundles (128 instructions) can be skid buffered at any one time..
Those 4 instructions – a bundle – travel together through the pipeline until they reach the unified issue queue of the scheduler. Just like Intel has implemented in Nehalem, there is also a loop buffer and predictor, which Intel used to call a "Loop Stream Detector". This loop buffer avoids branch mispredictions and contains decoded µops, which "shortens" the pipeline and reduces the amount of power spent on decoding.
Overall, up to 6 instructions can be executed at the same time. This is divided into 2 ALU/FP/NEON slots, 1 ALU/branch slot, 2 load/store slots (16 bytes), and 1 pure store slot that sends 16 bytes to the D-cache. There is a small (Cavium would not disclose how small) L1 TLB for zero latency translation from Virtual to physical addresses. There is no hardware prefetcher for the L1 D-cache, but the L2 cache has a rather complex hardware prefetcher which is able to recognize patterns (besides being able to stride or fetching the next line).
This is enough to feed the back-end, which can sustain 4 instructions per cycle from 4 different threads.
Micro Architecture Differences
Ultimately Cavium has only published a limited amount of information on the ThunderX2 cores, so there are some limits to our knowledge. But we've gone ahead and summarized some of the key specifications of the different CPU architectures below.
| Feature | Cavium ThunderX2 |
Qualcomm Centriq "Falkor" |
Intel "Skylake"-SP |
AMD EPYC "Zen" |
| L1-I cache Associativity |
32 KB 8-way |
64KB 8-way (+ 24 KB L0) |
32 KB 8-way |
64KB 4-way |
| L1-D cache Associativity |
32 KB 8-way |
32 KB 8-way* |
32 KB 8-way |
32 KB 8-way |
| Load Bandwith | 2x 16B | 2x 16B | 2x 32B | 2x 16B |
| L2-cache | 256 KB 8-way |
256 KB 8-way |
1 MB 16-way |
512 KB 8-way |
| Fetch Width | 8 instructions | 4 instructions | 16 bytes (+/- 4-5 x86) | 32 bytes (+/- 6-8 x86) |
| Issue Queue | 60 | 76 | 97 unified | 6x14 |
| Sustainable Instructions/cycle | 4 | 4 | 5-6 | 4-5 |
| Instructions in Flight | 180 (ROB) | 128 | 224 (ROB) | 192 |
| Int. Pipeline Length |
? |
15 stages | 19 stages 14 stage from µop cache |
19 stages? |
| TLB Instructions TLB Data |
"Small L1" + 2048 unified L2 | ? 64+512 |
128 64 +1536 Unified |
8+64+512 64+1532 |
A detailed analysis is out of the scope of this article. But you can read Ian's analyses of the Falkor, Skylake and Zen architectures here at AnandTech. We limit ourselves to the most obvious differences.
It is pretty clear that Intel's single-threaded performance remains unchallenged: the Skylake core is the widest core, keeps the most instructions in flight, and most importantly runs at the highest clockspeed. The ThunderX2 core is the one that fetches the most instructions per cycle, as it has to be able to keep 4 threads running. The fetch unit will grab 8 instructions from one thread, than grab 8 from the second thread and it will keep cycling between threads. A bad prediction could thus lower the performance of single thread significantly.








97 Comments
View All Comments
Gunbuster - Wednesday, May 23, 2018 - link
Because it's hard to explain the critical line of business software or database is having some unknown edge case issue because you thought look at me I'm so smart and saved 1% of the project cost using unproven low penetration hardware.daanno2 - Wednesday, May 23, 2018 - link
I'm guessing you've never dealt with expensive enterprise software before. They are mostly licensed per-core, so getting the absolute best performance per core, even if the CPU is 2-3x more expensive, is worth it. At the end of the day, the CPUs might be <5% of the total cost.SirPerro - Wednesday, May 23, 2018 - link
You can swallow a big risk if the benefit is 75% of the cost. Hey, it's definitely worth the try.If your hardware makes up for 5% of the cost, saving a 3% of the total budget is not worth the risk of migration.
FunBunny2 - Thursday, May 24, 2018 - link
"You can swallow a big risk if the benefit is 75% of the cost. Hey, it's definitely worth the try."the EOL of today's machines, the amortization schedules must be draconian. only if a 'different' server pays off in dozens of months, not years, will it have chance. to the extent that enterprise software is a C/C++ and *nix codebase, porting won't be onerous. but, I'm willing to guess, even Oracle code isn't all that parallel, so throwing a truckload of teeny cpu at it won't necessarily work.
name99 - Thursday, May 24, 2018 - link
The bigger problem here is the massive uncertainty around the meaning of the word "server" and thus the target for these new ARM CPUs.Some people seem to think "server" means primarily boxes that run SAP or ORACLE, but I think it's clear that the ARM ecosystem has little interest in that, at least right now.
What's of much more interest is racks on racks of CPUs running commodity (LAMP) or homegrown software, ie data warehouses and HPC. I'm not even sure the Java benchmarks being run are of much interest to this market. The things that matter are the sorts of things Cloudflare was measuring when they tested Centriq -- memcached, nginx, transforming one type of data into another (compression/decompression, encrypt/decrypt, transcode,...) at massive throughput.
That's where I'd expect to see the big sales of the ARM "server" cores -- to Cloudflare, Baidu, Google, and so on.
Also now that Marvell is in the game, will be interesting to see the extent to which they pull this downward, into their traditional sorts of markets like infrastructure network and storage control (eg to go into network appliances and NAS boxes).
Ed469546 - Wednesday, June 13, 2018 - link
Some of the commercial software you pay per core. Intel had the best single threaded performance mening power license costs.Interesting question is how the Thunderx2 cores are counted in this case: one core can run 4 threads.
andrewaggb - Wednesday, May 23, 2018 - link
I wonder what workloads they are targeting? High throughput with poor single threaded results is somewhat limiting.peevee - Wednesday, May 23, 2018 - link
Web app servers. VM servers. Hadoop/Spark nodes. All benefit more from having more threads running in parallel instead of each request waiting or switching contexts.If you are concerned about single-thread performance on 256-thread server (as 2-CPU server with this CPU will provide) AT ALL, you choose outrageously wrong hardware for the task to begin with. Go buy a 2-core i3. Practically the only test in this article which matters is Critical jOPS (assuming the used quality of service metric was configured realistically).
GeekyMcGeekface - Friday, May 25, 2018 - link
I’m building a cluster now with a few hundred Raspberry Pi’s because scale up is expensive and stupid. By distributing across a pool of clusters, I can handle far more memory bandwidth and compute. Consider 100 Raspberry PIs have 400 64-bit cores and 100GB of RAM. Total cost $3500 + power, mounting and switches.Running three clusters of those with Kubernetes, Couchbase and Azure Functions provides 1200 64-bit cores, about 100GB of extremely high performance storage, incredible failover and a map-reduce environment to die for.
Add some 64GB MicroSD cards and an object storage system to the cluster and there’s 12TB of cold storage (4TB when made redundant).
Pay a service fee to some sweatshop in the Eastern Block to do the labor intensive bits and you can build a massively parallel, almost impossible to crash, CI/CD friendly, multi-tenant, infinitely scalable PaaS... for less than the cost of the RAM for a single one of the servers here.
The only expensive bits in the design are the Netscalers.
Oh... and the power foot print is about the same as one of these servers.
I honestly have no idea what I what I would use a server like these in a new design for.
jospoortvliet - Wednesday, May 30, 2018 - link
single-core performance with your pi's is considerably lower, as is inter-core bandwidth. If your tasks require little inter-process communication you're good but with highly interdependent compute it won't perform well. But for specific tasks, yes, it might be very cost effective.