The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeep Learning, GPUs, and NVIDIA: A Brief Overview
To get terminology straight, ‘machine learning,’ or the even more generic term ‘AI’ is sometimes used interchangeably for ‘deep learning.’ Technically, they each refer to different things, with ML being a subset of AI, and DL being a subset of ML.
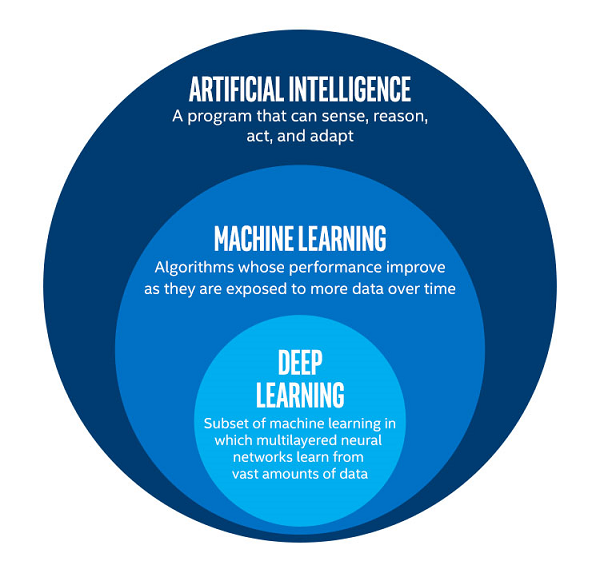
Picture from Intel
DL acquires its name from ‘deep neural networks,’ which are ultimately designed to recognize patterns in data, produce a related prediction, receive feedback on the prediction’s accuracy, and then adjust itself based on the feedback. When the feedback is based on an expected known output, this is ‘supervised learning.’ The computations occur on ‘nodes’, which are organized into ‘layers’: the original input data is first handled by the ‘input layer’ and the ‘output layer’ pushes out data that represents the model’s prediction. Any layers between those two are referred to as ‘hidden layers,’ of which deep neural networks have many hidden layers; originally, ‘deep’ meant having more than one hidden layer.
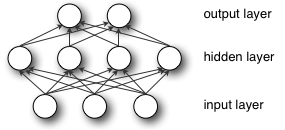
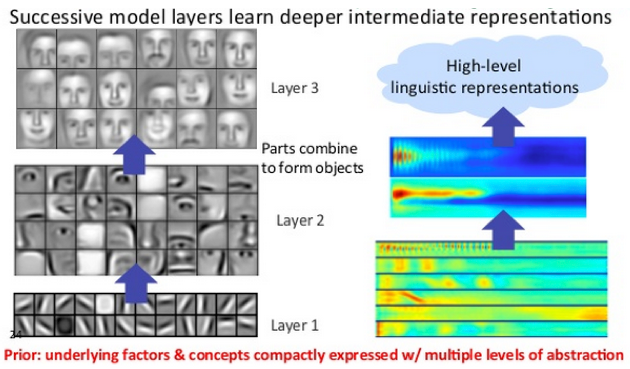
Images from DeepLearning4J
These hidden layers can operate in a hierarchy of increasing abstraction so that they can extract and distinguish non-linear features even from complicated input data. A standard example is in image recognition, where initial layers look for certain edges or shapes, which inform later layers that look for noses and eyes, and layers after that might look for faces. The final layers combine all this data to make a classification.
As input data progresses forward through the model, calculations include special internal parameters (weights). At the end, a loss function is produced, representing the error between the model’s prediction and the correct value. This error information is then used in running the model in reverse to calculate weight adjustments that will improve the model’s prediction. The weights are then updated. This sequence of a forward and backward pass (or backpropagation) comprises a single training iteration.
For inferencing, the process naturally excludes a backward pass and ultimately requires less computational intensity than training the model in the first place. In that sense, inferencing also has less need for higher precisions like FP32, and models can be appropriately pruned and optimized for deployment on particular devices. However, inferencing devices become much more sensitive to latency, cost, and power consumption, especially if on the edge.
Convolutional neural networks (CNNs or convnets) and recurrent neural networks are two important subtypes of (deep) neural networks, and the previous example with image recognition would be seen as a CNN. The convolutions themselves are an operation where input data and convolutional kernel are combined to form a feature map of some kind, transforming or filtering the original data to extract features. CNNs typically are ‘feedforward’, in the sense that data flows through the layers without looping. For RNNs (and variants like LSTM and GRU), there exists a separate weight that loops back to itself after every calculation, giving the net a sense of ‘memory.’ This allows the net to make time-aware predictions, useful in scenarios like text analysis, where a network would need to remember all the previous words with respect to the current one.
As much of deep learning math could be boiled down to linear algebra, certain operations can be re-written into GPU-friendlier matrix-matrix multiplications. When NVIDIA first developed and released cuDNN, one of the marquee implementations was accelerating convolutions based on lowering them into matrix multiplications. Among the cuDNN developments over the years is the 'precomputed implicit GEMM' convolution algorithm, which so happens to be the only algorithm that triggers convolution acceleration by tensor cores.
A Deep Learning Renaissance: (NVIDIA) GPUs Ascendant
Particularly for training, GPUs have become the DL accelerator-of-choice as most of these computations are essentially floating-point calculations in parallel, namely lots of matrix multiplications, with optimal performance requiring large amounts of memory bandwidth and size. These requirements neatly line up with the needs of HPC (and to a lesser extent, professional visualization), where GPUs need high precision floating point computation, large amounts of VRAM, and parallel compute capability.
Perhaps most importantly, is the underlying API and frameworks needed to utilize graphics hardware in this manner. For this, NVIDIA’s CUDA had come at the right time, just as deep learning started to regain interest, and was an easy launching point for further development:
- Release of CUDA & cuBLAS (2006/2007), and Tesla product line (2007)
- High-profile publications and achievements
- 2009, “Large-scale Deep Unsupervised Learning using Graphics Processors”
- 2012, AlexNet tops ILSVRC2012, running on cuda-convnet with two GTX 580s
- Release of cuDNN, integrated with Caffe dev branch (2014), later integrated by other DL frameworks
The development of CUDA and NVIDIA’s compute business coincided with research advances in machine learning, which had only just re-emerged as ‘deep learning’ around 2006. GPU accelerated neural network models provided orders-of-magnitude speed-ups over CPUs, and in turn re-popularized deep learning into the buzzword it is today. Meanwhile, NVIDIA’s graphics competitor at the time, ATI, was being acquired by AMD in 2006; OpenCL 1.0 itself only arrived in 2009, the same year AMD spun off their fabs as GlobalFoundries.
With DL researchers and academics successfully using CUDA to train neural network models faster, it was only a matter of time before NVIDIA released their cuDNN library of optimized deep learning primitives, of which there was ample precedent with the HPC-focused BLAS (Basic Linear Algebra Subroutines) and corresponding cuBLAS. So cuDNN abstracted away the need for researchers to create and optimize CUDA code for DL performance. As for AMD’s equivalent to cuDNN, MIOpen was only released last year under the ROCm umbrella, though currently is only publicly enabled in Caffe.
So in that sense, NVIDIA GPUs have become the reference implementation with respect to deep learning on GPUs, though the underlying hardware of both vendors are both suitable for DL acceleration.








65 Comments
View All Comments
mode_13h - Wednesday, July 4, 2018 - link
It's not that hard, really. They're just saying Nvidia made a library (cuDNN), so that different deep learning frameworks don't each have to hand-optimize code for things like its exotic tensor cores.For their part, AMD has a similar library they call MIOpen.
philehidiot - Wednesday, July 4, 2018 - link
Why thank you. That now does help it make a little more sense. The maths does make sense but the computer science is generally beyond me.aelizo - Wednesday, July 4, 2018 - link
At that price point, I would have liked to see some comparison to 2xTinan Xp, or even some comparison to 3x1080Ti's.Last year I saw some comparison between this sets on pytorch:
https://medium.com/@u39kun/titan-v-vs-1080-ti-head...
mode_13h - Wednesday, July 4, 2018 - link
I'm suspicious that he's not actually using the tensor cores. The V100/GV100 also has double-rate fp16, like the P100/GP100 before it. So, a < 2x improvement from going to 16-bit suggests it might only be using the packed half-precision instructions, rather than the tensor cores.Either that or he's not using batching and is completely limited by memory bottlenecks.
aelizo - Wednesday, July 4, 2018 - link
I suspect something similar, that is Why Nate could have done a great job with a similar comparison.Nate Oh - Monday, July 9, 2018 - link
Unfortunately, we only have 1 Titan Xp, which is actually on loan from TH. These class of devices are (usually) not sampled by NVIDIA so we could not have pursued what you suggest. We split custody of Titan V, and that alone was not an insignificant investment.Additionally, mGPU DL analysis introduces a whole new can of worms. As some may have noticed, I have not mentioned NCCL/MPI, NVLink, Volta mGPU enhancements, All Reduce, etc. It's definitely a topic for further investigation if the demand and resources match.
mode_13h - Tuesday, July 10, 2018 - link
Multi-GPU scaling is getting somewhat esoteric, but perhaps a good topic for future articles.Would be cool to see the effect of NVLink, if you can get access to such a system in the cloud. Maybe Nvidia will give you some sort of "press" access to their cloud?
ballsystemlord - Saturday, July 7, 2018 - link
Here are some spelling/grammar corrections. You write far fewer than most of the other authors at anandtech ( If Ian had written this I would have need 2 pages for all the corrections :) ). Good job!"And Volta does has those separate INT32 units."
You mean "have".
And Volta does have those separate INT32 units.
"For our purposes, the tiny image dataset of CIFAR10 works fine as running a single-node on a dataset like ImageNet with non-professional hardware that could be old as Kepler"...
Missing "as".
For our purposes, the tiny image dataset of CIFAR10 works fine as running a single-node on a dataset like ImageNet with non-professional hardware that could be as old as Kepler...
"Moving forward, we're hoping that MLPerf and similar efforts make good headway, so that we can tease out a bit more secrets from GPUs."
Grammar error.
Moving forward, we're hoping that MLPerf and similar efforts make good headway, so that we can tease out a bit more of the secrets from GPUs.
mode_13h - Saturday, July 7, 2018 - link
Yeah, if that's the worst you found, no one would even *suspect* him for being a lolcat.Vanguarde - Monday, July 9, 2018 - link
I purchased this card to get better frames in Witcher 3 at 4K everything maxed out, heavily modded. Never dips below 60fps and usually near 80-100fps