The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeepBench Inference: RNN and Sparse GEMM
Rounding out the last of our DeepBench inference tests are RNN and Sparse GEMM, both available in single precision only. That being said, the FP16 parameter could be selected anyway. Given the low results all around, this is more of an artifact than anything else.
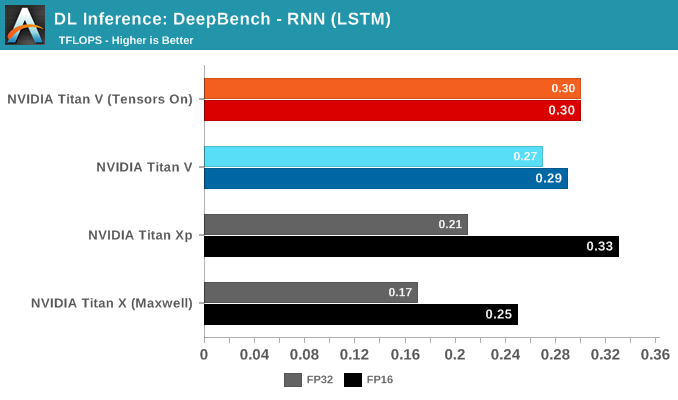
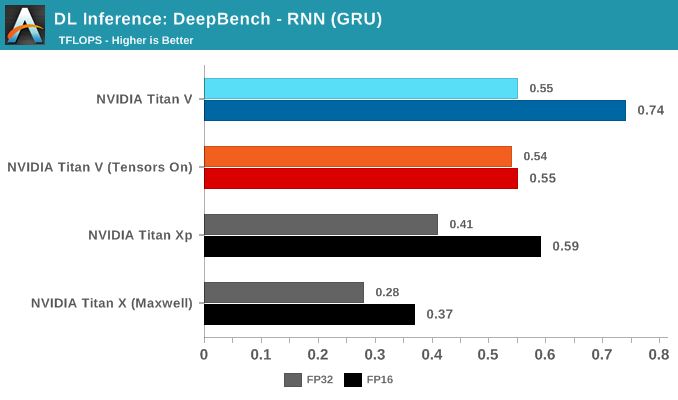
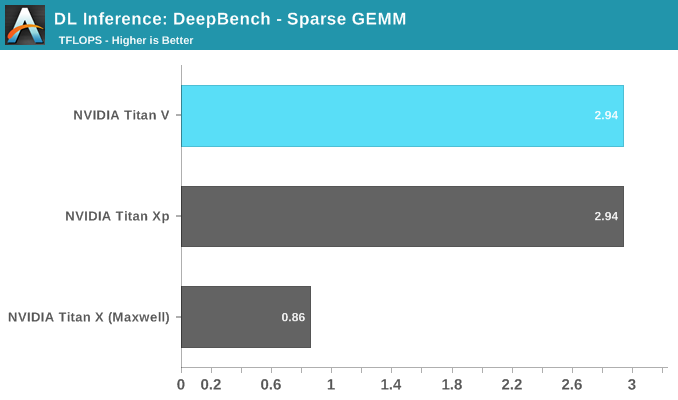
While RNNs might also be accelerated, DeepBench and NVIDIA only support single precision RNN inference at this time.








65 Comments
View All Comments
mode_13h - Wednesday, July 4, 2018 - link
It's not that hard, really. They're just saying Nvidia made a library (cuDNN), so that different deep learning frameworks don't each have to hand-optimize code for things like its exotic tensor cores.For their part, AMD has a similar library they call MIOpen.
philehidiot - Wednesday, July 4, 2018 - link
Why thank you. That now does help it make a little more sense. The maths does make sense but the computer science is generally beyond me.aelizo - Wednesday, July 4, 2018 - link
At that price point, I would have liked to see some comparison to 2xTinan Xp, or even some comparison to 3x1080Ti's.Last year I saw some comparison between this sets on pytorch:
https://medium.com/@u39kun/titan-v-vs-1080-ti-head...
mode_13h - Wednesday, July 4, 2018 - link
I'm suspicious that he's not actually using the tensor cores. The V100/GV100 also has double-rate fp16, like the P100/GP100 before it. So, a < 2x improvement from going to 16-bit suggests it might only be using the packed half-precision instructions, rather than the tensor cores.Either that or he's not using batching and is completely limited by memory bottlenecks.
aelizo - Wednesday, July 4, 2018 - link
I suspect something similar, that is Why Nate could have done a great job with a similar comparison.Nate Oh - Monday, July 9, 2018 - link
Unfortunately, we only have 1 Titan Xp, which is actually on loan from TH. These class of devices are (usually) not sampled by NVIDIA so we could not have pursued what you suggest. We split custody of Titan V, and that alone was not an insignificant investment.Additionally, mGPU DL analysis introduces a whole new can of worms. As some may have noticed, I have not mentioned NCCL/MPI, NVLink, Volta mGPU enhancements, All Reduce, etc. It's definitely a topic for further investigation if the demand and resources match.
mode_13h - Tuesday, July 10, 2018 - link
Multi-GPU scaling is getting somewhat esoteric, but perhaps a good topic for future articles.Would be cool to see the effect of NVLink, if you can get access to such a system in the cloud. Maybe Nvidia will give you some sort of "press" access to their cloud?
ballsystemlord - Saturday, July 7, 2018 - link
Here are some spelling/grammar corrections. You write far fewer than most of the other authors at anandtech ( If Ian had written this I would have need 2 pages for all the corrections :) ). Good job!"And Volta does has those separate INT32 units."
You mean "have".
And Volta does have those separate INT32 units.
"For our purposes, the tiny image dataset of CIFAR10 works fine as running a single-node on a dataset like ImageNet with non-professional hardware that could be old as Kepler"...
Missing "as".
For our purposes, the tiny image dataset of CIFAR10 works fine as running a single-node on a dataset like ImageNet with non-professional hardware that could be as old as Kepler...
"Moving forward, we're hoping that MLPerf and similar efforts make good headway, so that we can tease out a bit more secrets from GPUs."
Grammar error.
Moving forward, we're hoping that MLPerf and similar efforts make good headway, so that we can tease out a bit more of the secrets from GPUs.
mode_13h - Saturday, July 7, 2018 - link
Yeah, if that's the worst you found, no one would even *suspect* him for being a lolcat.Vanguarde - Monday, July 9, 2018 - link
I purchased this card to get better frames in Witcher 3 at 4K everything maxed out, heavily modded. Never dips below 60fps and usually near 80-100fps