The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeepBench Inference: RNN and Sparse GEMM
Rounding out the last of our DeepBench inference tests are RNN and Sparse GEMM, both available in single precision only. That being said, the FP16 parameter could be selected anyway. Given the low results all around, this is more of an artifact than anything else.
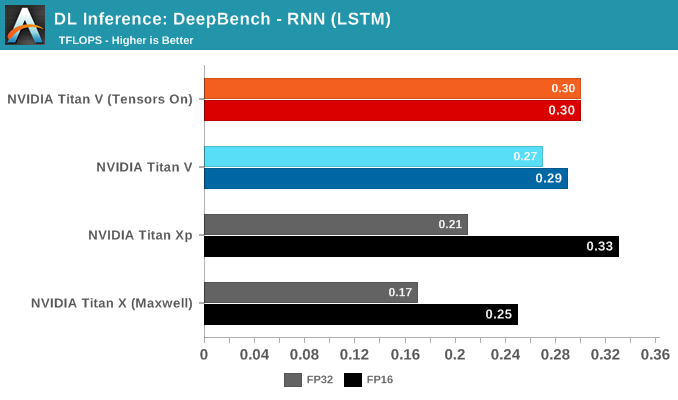
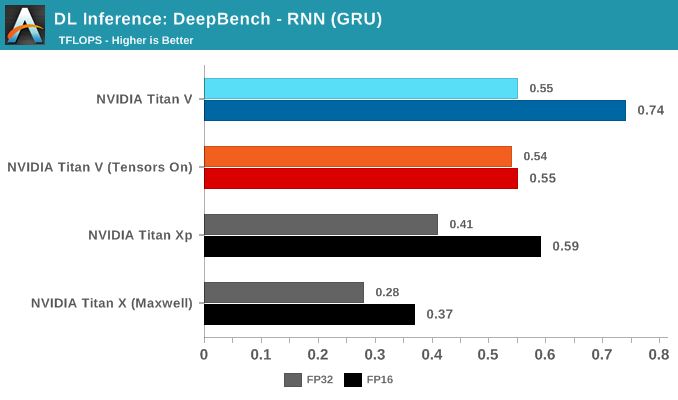
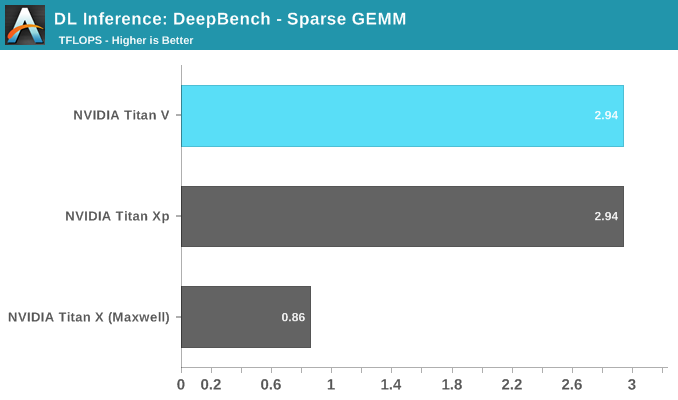
While RNNs might also be accelerated, DeepBench and NVIDIA only support single precision RNN inference at this time.








65 Comments
View All Comments
Nate Oh - Wednesday, July 11, 2018 - link
Thanks for your inquisitive responses throughout :)And yes, I was trying to be impartial with AMD's claims about deep learning. Until I have results myself, I offer them a degree of the benefit of the doubt, considering their traditional GPGPU capabilities. Meaning that "image classification for machine learning..." essentially falls under all the deep learning investigations I did for the review. My personal opinion is that 8-bit SAD will be as useful as it was with Kepler/Maxwell in terms of DL acceleration, except with lesser software support; you can make of that as you will. It really gets into the weeds to put AMD's 'machine intelligence' terminology under the scope, and I'd feel more comfortable doing so in an AMD-focused DL/ML investigation. I want to emphasize again that new instructions matter much less in the context of software/library/API support, so the fact that they are absent from the whitepaper directly adds to that observation. If this were a Vega FE DL review, I would certainly pester AMD about that, as much as I put an effort towards TensorRT and FP16 storage/tensor cores here. So encourage AMD to sample me :D
>TFLOPS
It is TFLOPS just for DeepBench because that is how Baidu and NV/AMD/Intel present their DeepBench results; you can see for yourselves at the DeepBench Github. We have not independently configured results (for DeepBench) that way, and I apologize if that's how it came across. This also makes it easier to keep us accountable by comparing our results to Baidu's Github. DeepBench is, as stated in the article, completely framework and model agnostic. We use TFLOPS when it is floating point, and we actually use TOPS when it is integer :) I've generalized a bit only because that comment had become so lengthy. This TFLOPS/TOPS usage is limited to solely DeepBench because of how they use pure math kernels, and precisely the reason I included end-to-end results with DAWNBench implementations.
>Open source
Indeed, like I've said, I've actually gone and attempted (poorly) to do some dev work myself. The article could *easily* ballooned to double the length, as well. The point I wanted to convey is exactly what you've picked up with AMD. Given the limited scope of the article (and the lack of direct AMD DL investigations), I want to refrain from saying something outright like, 'one of the main reasons we don't currently use AMD,' but I am just aware as you are on this point :) This deduction is unsaid but present throughout, .
Nate Oh - Wednesday, July 11, 2018 - link
Clarification: "so the fact that citations are absent from the whitepaper"mode_13h - Thursday, July 12, 2018 - link
> I was trying to be impartial with AMD's claims about deep learning. Until I have results myself, I offer them a degree of the benefit of the doubt, considering their traditional GPGPU capabilities.As a member of the tech press, please don't forget your privileged position of being able to request guidance on how to exercise claimed product features. I think this is a fair question and wouldn't impart any bias. Rather, it would help inform readers of how to exploit these features, and also quantify product performance when used as the designers intended.
I think it's also fair to ask if they can provide any references (either implementations or papers) to support their claims regarding how SAD can be utilized in machine learning, in cases of doubt.
Again, I'm saying this mostly in anticipation of your future Vega coverage, whether you choose to follow up with Vega 10, or perhaps you only revisit the matter with Vega 20.
As for searching & sifting through the sources of MIOpen, I think that's "over and above" what's expected. I'm just pointing out that, sometimes, it's actually surprisingly easy to answer questions by doing simple text searches on the source code. Sometimes, like when checking whether a certain instruction is emitted, it's also possible to save the generated assembly language and search *that*.
Demiurge - Friday, July 20, 2018 - link
Nate gets paid to educate and discuss with you, I don't, but more importantly to me, I made my point that Vega is not "underwhelming" for DL.Why should I *convince* you? I don't *need* to convince you. You didn't state Vega was "underwhelming" for DL.
Nate Oh - Monday, July 9, 2018 - link
To put it lightly, use of FP16 in DL training is not on the same level of use of INT8 in training; the latter is basically pure research and highly niche to those specific implementations. FP16 training (with NVIDIA GPUs) has reached a level of maturity and practicality where there is out-of-the-box support for most major frameworks. FP16 training and INT8 inferencing is the current understanding of lower-precision applicability in DL.More specifically, the whole field of lower-precision DL training/inference is all about making lower-precision datatypes more important, so of course that's the case for INT8/FP8. FP16 is already relevant for real-world training in certain scenarios; some researchers are *trying* to make INT8 relevant for real-world training in certain scenarios. As mode_13h said, that paper is a custom 8-bit datatype used to approximate 32-bit gradients for parameter updates during the backprop, specifically to speed-up inter-GPU communication for greater parallelism. AKA it is not usage of 8-bit datatypes all around, it's very specific to one aspect. It's essentially a proof-of-concept and pure research. Using INT16 for everything is hard enough; some people (see below) were able to use a custom INT16 format and use INT16/INT32 FMA. And yes, sometimes, companies don't distinguish inference and training as clearly as they should, with the resulting perception of superior general DL performance.
In any case, DP4A is not really used in training at all and it wasn't designed to do so anyway. You can ‘make’ the exception with research papers like what you cited but you can always find niche exceptions in research because that is its purpose. It was designed for inferencing acceleration and as product segmentation for non-GP100 GPUs. Even now, it's pushed for working with a model that TensorRT converted from higher-precision to INT8.
(I am splitting this comment up to respond separately on the topic of Vega/instruction set support, but both comments should be considered in tandem)
References/Links
https://software.intel.com/en-us/articles/lower-nu...
https://ai.intel.com/lowering-numerical-precision-...
http://dawn.cs.stanford.edu/2018/03/09/low-precisi...
https://www.tensorflow.org/performance/quantizatio...
https://arxiv.org/pdf/1802.00930.pdf (Custom datatype for INT16/INT32 mixed precision training)
http://on-demand.gputechconf.com/gtc/2017/presenta...
https://devblogs.nvidia.com/int8-inference-autonom...
https://devblogs.nvidia.com/mixed-precision-progra... (Introduction of DP4A/DP2A)
mode_13h - Tuesday, July 10, 2018 - link
> ... DP4A is not really used in training at all ... It was designed for inferencing acceleration and as product segmentation for non-GP100 GPUs.You mean segmentation of GP100 vs. GP102+ ? Or are you saying it's lacking in some of the smaller Pascal GPUs, like GP107? And *why* isn't it listed in the CUDA compute capabilities table (https://docs.nvidia.com/cuda/cuda-c-programming-gu... Grrr!
Regardless, given that GV100 has it, I get the sense that it was simply an evolution that came too late for the GP100.
Finally, thank you for another thoughtful and detailed reply.
Ryan Smith - Tuesday, July 3, 2018 - link
The Titan V is such a niche card that I'm not surprised to hear NV hasn't prepared macOS drivers. There are good reasons for them to have drivers ready for their consumer hardware - they need to do the work anyhow to support existing products and make sure they're ready to take a new Apple contract if they win it - but the Titan V/GV100 will never end up in a Mac. So adding that to the mac drivers would be a less beneficial decision.Flunk - Tuesday, July 3, 2018 - link
I'm surprised any cards not shipped in Mac Models have Mac drivers anymore. It's not like you can add a PCI-E video card to any recent Mac.Strunf - Wednesday, July 4, 2018 - link
Thunderbolt allows for an external PCI-E card but there's probably just a few guys ready to do this kind of thing...ImSpartacus - Tuesday, July 3, 2018 - link
Is the new 32GB V100 still on SXM2?Several sites mentioned SXM3 in reference to the 32GB refresh of V100, but it's hard to find details on what improved (if anything).