The AMD 2nd Gen Ryzen Deep Dive: The 2700X, 2700, 2600X, and 2600 Tested
by Ian Cutress on April 19, 2018 9:00 AM ESTTranslating to IPC: All This for 3%?
Contrary to popular belief, increasing IPC is difficult. Attempt to ensure that each execution port is fed every cycle requires having wide decoders, large out-of-order queues, fast caches, and the right execution port configuration. It might sound easy to pile it all on, however both physics and economics get in the way: the chip still has to be thermally efficient and it has to make money for the company. Every generational design update will go for what is called the ‘low-hanging fruit’: the identified changes that give the most gain for the smallest effort. Usually reducing cache latency is not always the easiest task, and for non-semiconductor engineers (myself included), it sounds like a lot of work for a small gain.
For our IPC testing, we use the following rules. Each CPU is allocated four cores, without extra threading, and power modes are disabled such that the cores run at a specific frequency only. The DRAM is set to what the processor supports, so in the case of the new CPUs, that is DDR4-2933, and the previous generation at DDR4-2666. I have recently seen threads which dispute if this is fair: this is an IPC test, not an instruction efficiency test. The DRAM official support is part of the hardware specifications, just as much as the size of the caches or the number of execution ports. Running the two CPUs at the same DRAM frequency gives an unfair advantage to one of them: either a bigger overclock/underclock, and deviates from the intended design.
So in our test, we take the new Ryzen 7 2700X, the first generation Ryzen 7 1800X, and the pre-Zen Bristol Ridge based A12-9800, which is based on the AM4 platform and uses DDR4. We set each processors at four cores, no multi-threading, and 3.0 GHz, then ran through some of our tests.
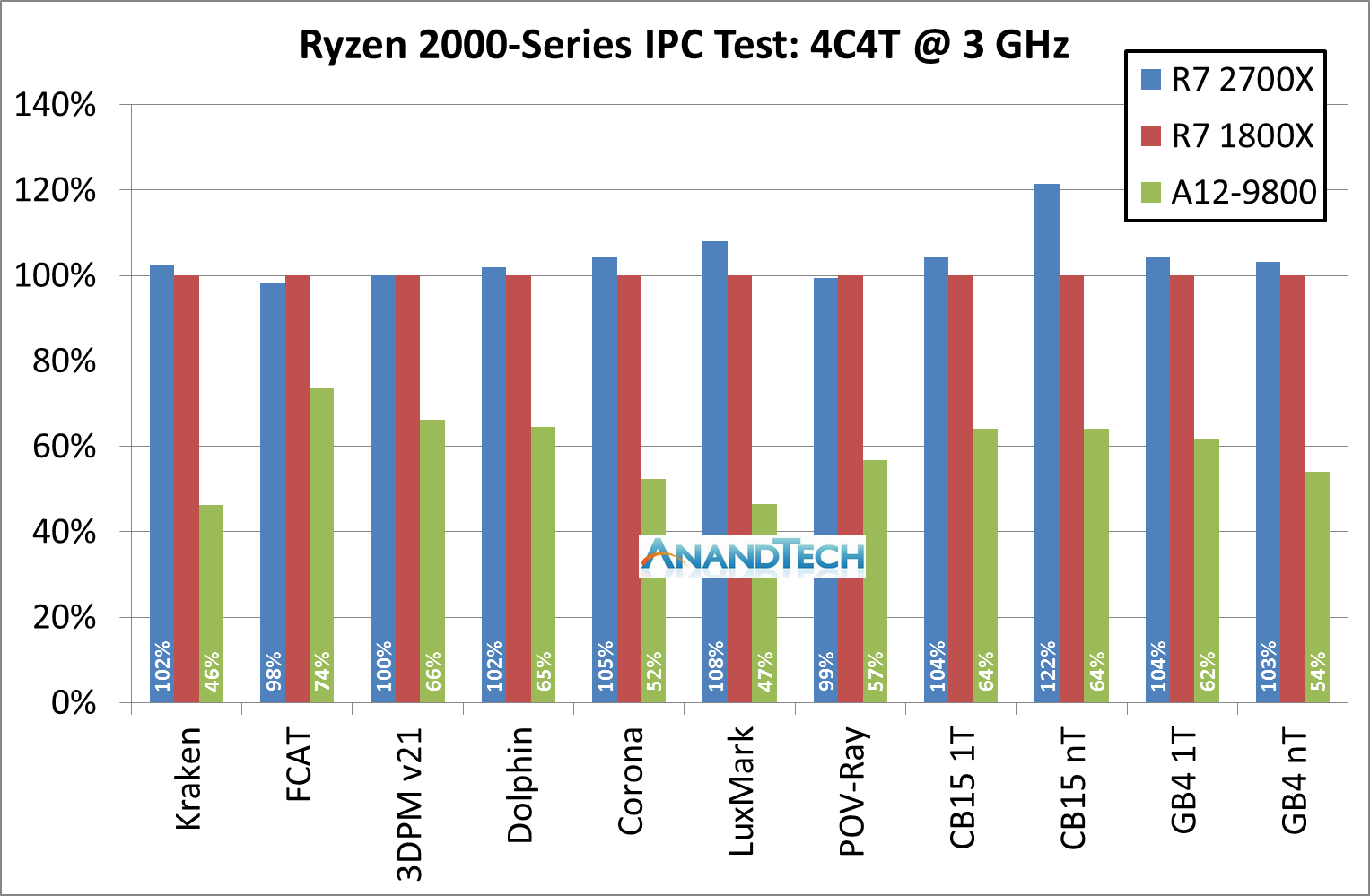
For this graph we have rooted the first generation Ryzen 7 1800X as our 100% marker, with the blue columns as the Ryzen 7 2700X. The problem with trying to identify a 3% IPC increase is that 3% could easily fall within the noise of a benchmark run: if the cache is not fully set before the run, it could encounter different performance. Shown above, a good number of tests fall in that +/- 2% range.
However, for compute heavy tasks, there are 3-4% benefits: Corona, LuxMark, CineBench and GeekBench are the ones here. We haven’t included the GeekBench sub-test results in the graph above, but most of those fall into the 2-5% category for gains.
If we take out Cinebench R15 nT result and the Geekbench memory tests, the average of all of the tests comes out to a +3.1% gain for the new Ryzen 2700X. That sounds bang on the money for what AMD stated it would do.
Cycling back to that Cinebench R15 nT result that showed a 22% gain. We also had some other IPC testing done at 3.0 GHz but with 8C/16T (which we couldn’t compare to Bristol Ridge), and a few other tests also showed 20%+ gains. This is probably a sign that AMD might have also adjusted how it manages its simultaneous multi-threading. This requires further testing.
AMD’s Overall 10% Increase
With some of the benefits of the 12LP manufacturing process, a few editors internally have questioned exactly why AMD hasn’t redesigned certain elements of the microarchitecture to take advantage. Ultimately it would appear that the ‘free’ frequency boost is worth just putting the same design in – as mentioned previously, the 12LP design is based on 14LPP with performance bump improvements. In the past it might not have been mentioned as a separate product line. So pushing through the same design is an easy win, allowing the teams to focus on the next major core redesign.
That all being said, AMD has previously already stated its intentions for the Zen+ core design – rolling back to CES at the beginning of the year, AMD stated that they wanted Zen+ and future products to go above and beyond the ‘industry standard’ of a 7-8% performance gain each year.
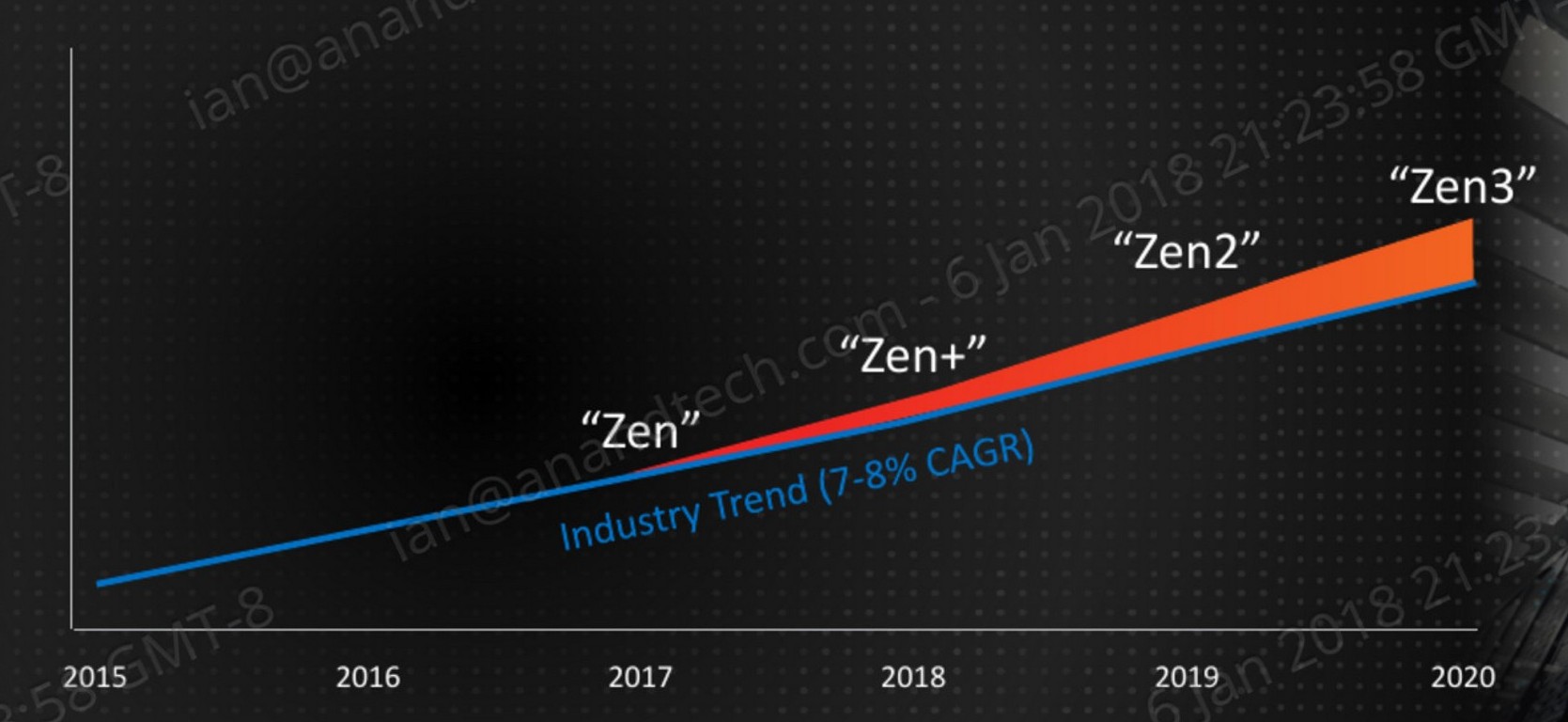
Clearly 3% IPC is not enough, so AMD is combining the performance gain with the +250 MHz increase, which is about another 6% peak frequency, with better turbo performance with Precision Boost 2 / XFR 2. This is about 10%, on paper at least. Benchmarks to follow.








545 Comments
View All Comments
jor5 - Thursday, April 26, 2018 - link
Pull this shambles and repost when you've corrected it fully.mapesdhs - Monday, May 14, 2018 - link
Not an argument. It is just as interesting to learn about how and why this issue occured, to understand the nature of benchmarking. Life isn't just about being spoonfed end nuggets of things, the process itself is relevant. Or would you rather we don't learn from history?peevee - Thursday, April 26, 2018 - link
When 65W i7 8700 is 15% faster in Octane 2.0 than 105W Rizen 7 2700x, it is just sad.Of course, the horrible x64 practically demands than compilers must optimize for a very specific CPU implementation (choosing and sorting instructions in the code accordingly), AMD could have at least realized the fact and optimize their own implementation for the same Intel-optimized code generators...
GreenReaper - Thursday, April 26, 2018 - link
Intel compilers and libraries tend not to use the ideal instructions unless they detect a GenuineIntel signature via CPUID - it'll likely use the default lowest-common-denominator pathway instead.TDP is more of a guideline - it doesn't determine actual power usage (we've seen Coffee Lake use way more than the TDP), let alone the power used in a particular operation. Having said that, I wouldn't be surprised if Intel were more efficient in this particular test. But it'd be interesting to know how much impact Meltdown patches have in that area; they might well increase the amount of time the CPU spends idle (but not idle enough to go into a sleep mode) as it waited to fetch instructions.
SaturnusDK - Thursday, April 26, 2018 - link
Compare power consumption to blender score. Ryzen is about 9% more power efficient.TDP is literally Thermal Design Power. It has nothing to do with power consumption.
peevee - Thursday, April 26, 2018 - link
"TDP is literally Thermal Design Power. It has nothing to do with power consumption."Unless you have invented a way to overcome energy conservation law, power consumed = power dissipated.
SaturnusDK - Friday, April 27, 2018 - link
It's a guideline for cooling solutions. Look at the power consumption numbers in this test for example.Ryzen 2700X power consumption under full load 110W.
Intel i7 8700K power consumption under full load 120W.
Both are at stock speeds with the Ryzen having 8 cores versus 6 cores, and scoring 2700X 24% higher Cinebench scores. Ryzen is rated at 105W TDP so actual power consumption at stock speed is pretty close. The 8700K uses 120W so it's pretty far from the 95W TDP it is rated at.
ijdat - Saturday, April 28, 2018 - link
The 8700 also uses 120W so it's even further from the 65W TDP it's rated at. In comparison Ryzen 2700 uses 45W when it has the same rated 65W TDP. I know which one I'd prefer to put into a quiet low-power system...mapesdhs - Monday, May 14, 2018 - link
Perhaps this is AMD's biggest win this time round, potent HTPC setups.peevee - Thursday, April 26, 2018 - link
"Intel compilers "What Intel compilers have to do with it?