Meltdown & Spectre: Analyzing Performance Impacts on Intel's NUC7i7BNH
by Ganesh T S on March 23, 2018 4:15 PM EST- Posted in
- Systems
- Spectre
- Benchmarks
- Meltdown
Miscellaneous Benchmarks
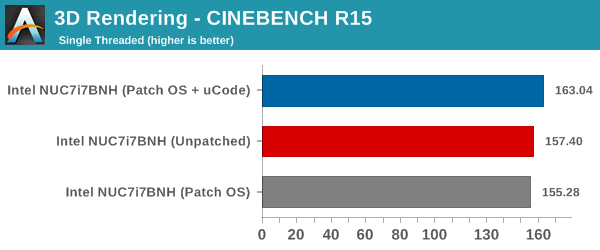
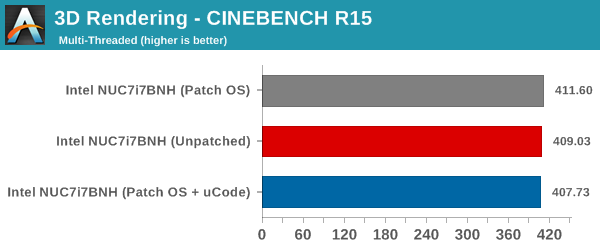
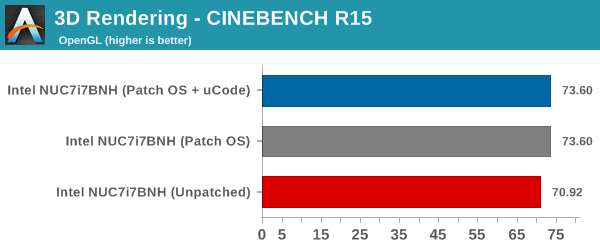
CINEBENCH R15 is our benchmark of choice for 3D rendering. It provides three benchmark modes - OpenGL, single threaded and multi-threaded. This benchmark is largely unaffected by the patching. All the recorded numbers are within the margin of expected errors from one run to another.
x264 v5.0 is another benchmark that is unaffected by the Meltdown and Spectre patches.


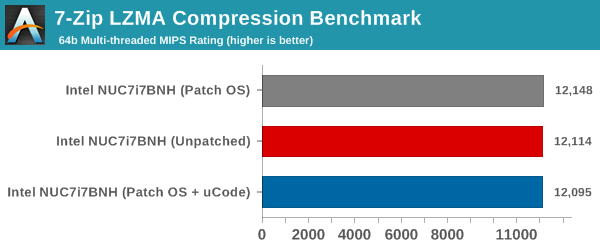
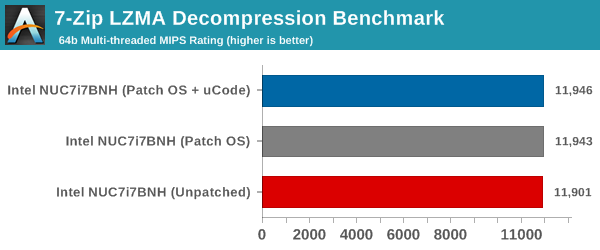
7-Zip is a very effective and efficient compression program, often beating out OpenCL accelerated commercial programs in benchmarks even while using just the CPU power. 7-Zip has a benchmarking program that provides tons of details regarding the underlying CPU's efficiency. In our benchmark suite, we are interested in the compression and decompression MIPS ratings when utilizing all the available threads. This benchmark also remains unaffected, with the results happening to be within the margin of error from run to run.
Agisoft PhotoScan is a commercial program that converts 2D images into 3D point maps, meshes and textures. The program designers sent us a command line version in order to evaluate the efficiency of various systems that go under our review scanner. The command line version has two benchmark modes, one using the CPU and the other using both the CPU and GPU (via OpenCL). We have been using an old version of the program with 50 photographs in our reviews till now. The updated benchmark (v1.3) now takes around 84 photographs and does four stages of computation:
- Stage 1: Align Photographs (capable of OpenCL acceleration)
- Stage 2: Build Point Cloud (capable of OpenCL acceleration)
- Stage 3: Build Mesh
- Stage 4: Build Textures
We record the time taken for each stage. Since various elements of the software are single threaded, others multithreaded, and some use GPUs, it is a very relevant benchmark from a media editing and content creation perspective.


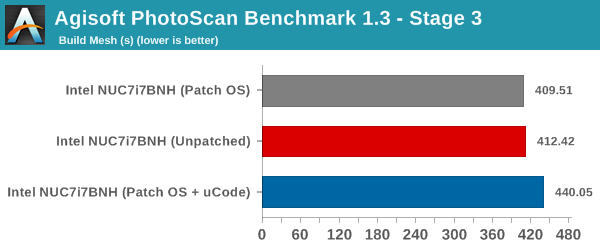
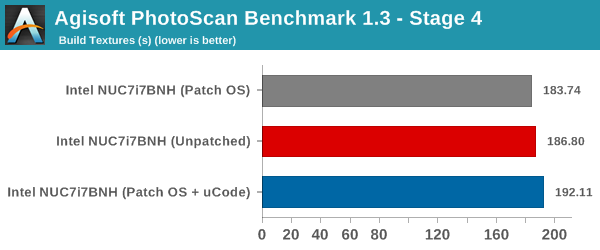
Since this is a real-world benchmark, we can see performance impacts in some of the stages. While the first and last ones do not have any significant deviation, stages 2 and 3 are worse off by around 12.8% and 6.8% respectively in the non-GPU case.
The benchmarks section wraps up with the new Dolphin Emulator (v5) benchmark mode results. This is again a test of the CPU capabilities, but, we don't see much impact on the performance from the patching. The bennchmark consistently took around 325 seconds in all three patching configurations.








83 Comments
View All Comments
boeush - Friday, March 23, 2018 - link
Speculative execution uses up compute cycles and can cause excessive memory loads and cache thrashing - which amount to wasted power and in some cache-sensitive cases, possibly even a drop in performance - when the speculation is frequently-enough incorrect (i.e. when the actual branch taken doesn't match the CPU's guess.)I'd expect that disabling speculative execution under high load (e.g. benchmarking scenarios) should normally result in improved power efficiency (avoiding wasted computation and I/O) - but at the cost of raw compute performance. In less intense, more 'bursty' scenarios, where the CPU spends a lot of time in an idle state, the "hurry up and rest" dynamic might strongly reduce the overall power waste of speculative execution, as the CPU would spend less time in an active-but-stalled state while spending more time in a sleep state...
Cravenmor - Friday, March 23, 2018 - link
The thing that caught my eye was the reduction in power from the patches. I wonder what to deduct from speculative function and whether it's inefficient.Lord of the Bored - Saturday, March 24, 2018 - link
Speculative execution does add somewhat to the power load. That's why Atom parts were in-order for a long time, and many ARM parts still are.Cravenmor - Friday, March 23, 2018 - link
willis936 beat to it by a noseeva02langley - Friday, March 23, 2018 - link
It is interesting nonetheless. The storage data is absolutely devastating. Can we make conclusions to the server world from Intel? I don't know since servers are still using hard drives. However, it might force companies to switch to Epyc or to upgrade to Canon Lake. It would be interesting.boeush - Friday, March 23, 2018 - link
The CPU used in these tests was a low-power 2-core - pretty weak to begin with. Knock some performance off the top, and you have detectable impact on I/O.Probably the impact would be much less severe with a more powerful CPU: where the test scenario would again 'flip' from CPU-bound to bus/storage device performance- limited.
Reflex - Friday, March 23, 2018 - link
Also, servers are usually only using NVMe drives as cache, SAS is less likely to have significant impact.Drazick - Friday, March 23, 2018 - link
This is a great analysis.We'd be happy to have more like this (On various performance impacting situations).
I'd be happy to have a guide how to prevent the patching for each OS (Windows, macOS, Linux) as the private user mostly has no reason to be afraid of those.
Thank You!
ZolaIII - Friday, March 23, 2018 - link
I found this comparation much more interesting.https://www.phoronix.com/scan.php?page=article&...
It's done on much more capable system which whose more hit in the first place & at least some benchmarks are representative in real usage workloads. Seams M$ again did a bad job & chubby Linus is still not satisfied with up to date results so future work still carries on.
Klimax - Sunday, March 25, 2018 - link
Not really correct...