The Snapdragon 845 Performance Preview: Setting the Stage for Flagship Android 2018
by Ryan Smith & Andrei Frumusanu on February 12, 2018 12:30 AM EST- Posted in
- Mobile
- Snapdragon
- Qualcomm
- Smartphones
- SoCs
- Snapdragon 845
CPU & Memory Subsystem
As we mentioned earlier, the Snapdragon 845 is the first SoC employing ARM’s new cluster technology DynamiQ. The different CPU cores are no longer hosted in dedicated cluster subsystems but are now integrated in a larger DynamiQ cluster. This change means that the cluster cache which to date was referred to as the L2 cache becomes the L3 cache and the individual CPU cores now receive a new private per-core L2. In the case of the Snapdragon 845, the Kryo 385 performance cores – derivative of ARM’s new A75 – are configured with 256KB L2 caches. The Kryo 845 efficiency cores, which are derivative of the A55, use 128KB L2 cache configurations.
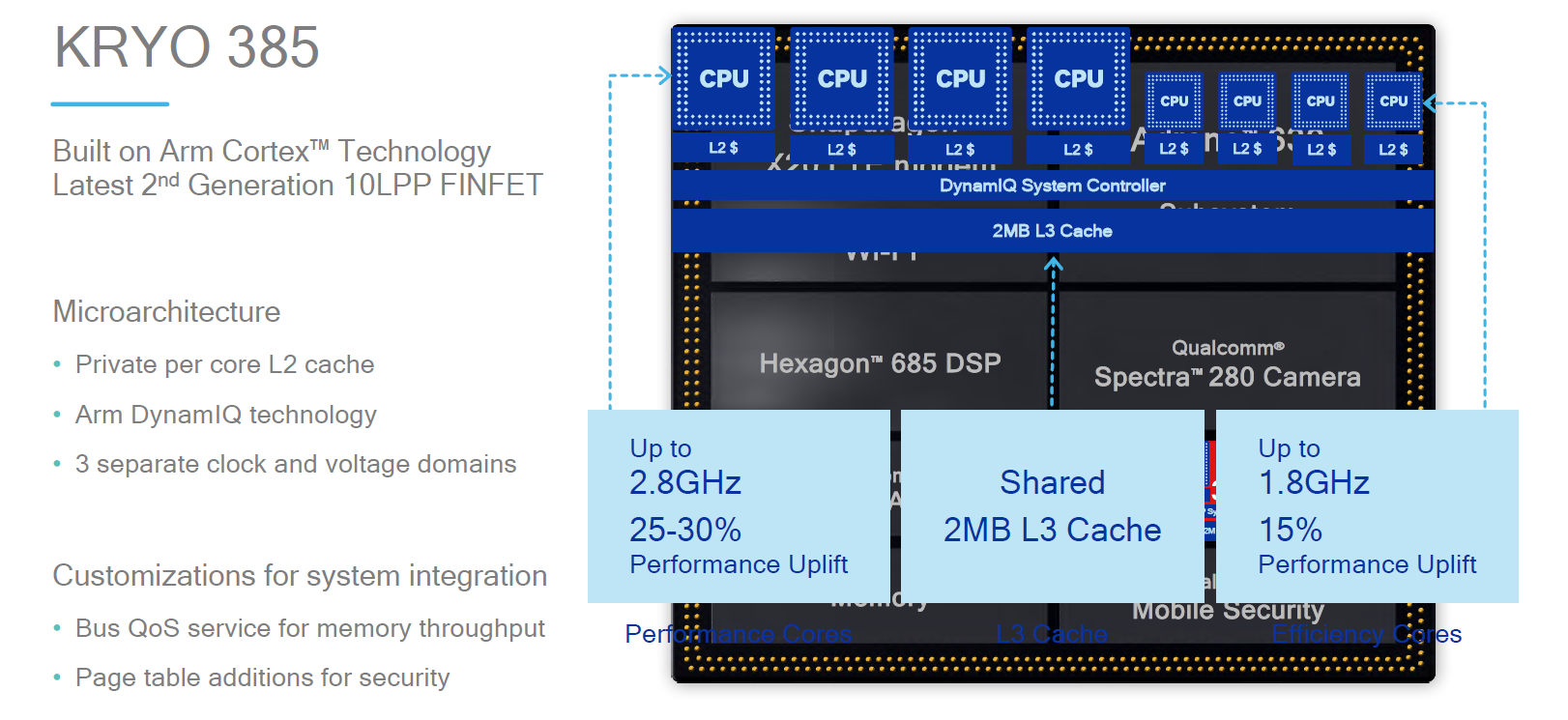
The L3 cache of the DynamiQ Shared Unit (DSU) is configured at 2MB. At the launch of the Snapdragon 845 Qualcomm advertised three voltage and clock domains – unfortunately we haven’t had time to look deeper into the system of the QRD to find out how this is partitioned, however it is still my unconfirmed belief that the third clock/voltage domain is dedicated to the DSU and not part of the CPU cores. An important characteristic that is totally new to the Android SoC ecosystem is the introduction of a system cache – this 3MB cache seems to sit at the memory controller / interconnect level above the CPU subsystem, something we’ll get back to in just a bit.
Qualcomm’s performance projections seemed relatively conservative as they claimed a performance uplift of only 25-30% which seemed lower than ARM’s projections. We have to keep in mind that beyond the microarchitectural improvements expected from the transition from A73 to A75 based CPU cores we also have a flat 14% frequency increase from 2.47GHz to 2.8GHz on the side of the performance cores. Unfortunately in the limited testing time we had with the QRD we couldn’t make use of long-running CPU benchmarks such as our SPEC suite, so for the scope of this article we had to base our synthetic analysis on GeekBench4 results.
| Geekbench 4 - Integer Performance Single Threaded |
|||
| Snapdragon 845 | Snapdragon 835 | % Increase |
|
| AES | 1160 MB/s | 942.5 MB/s | 23.1% |
| LZMA | 4.15 MB/s | 2.98 MB/s | 39.3% |
| JPEG | 20.8 Mpixels/s | 16.6 Mpixels/s | 25.2% |
| Canny | 32.1 Mpixels/s | 24.9 Mpixels/s | 28.8% |
| Lua | 2.18 MB/s | 1.75 MB/s | 24.0% |
| Dijkstra | 1.90 MTE/s | 1.62 MTE/s | 16.9% |
| SQLite | 70.3 Krows/s | 53.4 Krows/s | 31.8% |
| HTML5 Parse | 12.9 MB/s | 8.97 MB/s | 44.1% |
| HTML5 DOM | 3.00 Melems/s | 2.27 Melems/s | 31.9% |
| Histogram Equalization | 67.3 Mpixels/s | 52.5 Mpixels/s | 28.2% |
| PDF Rendering | 66.4 Mpixels/s | 48.5 Mpixels/s | 37.0% |
| LLVM | 321.2 functions/s | 257.3 functions/s | 24.8% |
| Camera | 7.96 images/s | 5.64 images/s | 40.9% |
For the integer workload results we see a healthy performance across the various tests. Qualcomm’s 25-30% increase here seems to be justified as this is the most common increase in most tests. Workloads such as LZMA, HTML5 parsing, PDF rendering and the Camera substests see larger increases into the 40% range. The overall improvement in absolute performance for the integer tests is 31%.
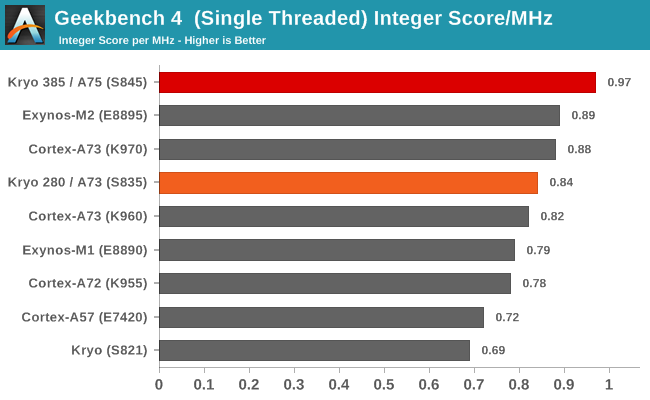
If we revisit performance per clock across recent microarchitectures we see the Snapdragon’s A75 based cores increase by only a meagre 15% which is below our expectations. We move on to the floating point benchmarks to see if we see a similar story.
| Geekbench 4 - Floating Point Performance Single Threaded |
|||
| Snapdragon 845 | Snapdragon 835 | % Increase | |
| SGEMM | 16.6 GFLOPS | 11.4 GFLOPS | 45.1% |
| SFFT | 4.23 GFLOPS | 2.86 GFLOPS | 47.9% |
| N-Body Physics | 1400 Kpairs/s | 872.2 Kpairs/s | 60.5% |
| Rigid Body Physics | 8524.2 FPS | 6130.5 FPS | 39.0% |
| Ray Tracing | 354.0 Kpixels/s | 232.7 Kpixels/s | 52.1% |
| HDR | 11.9 Mpixels/s | 8.31 Mpixels/s | 43.2% |
| Gaussian Blur | 34.5 Mpixels/s | 23.9 Mpixels/s | 44.3% |
| Speech Recognition | 17.9 Words/s | 13.6 Words/s | 31.6% |
| Face Detection | 752.4 Ksubs/s | 532.8 Ksubs/s | 41.2% |
The FP subtests of GB4 show a noticeably larger increase than the integer tests. Besides the switch from a 2-wide decode front-end to a 3-wide one, the largest changes of the A75 microarchitecture was found in the floating point execution pipelines and is likely the cause for the larger FP performance improvement. The boost here comes at an overall 45% in GB4.
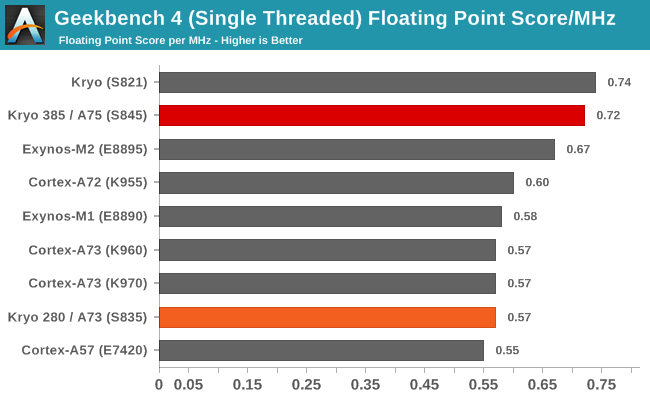
In terms of performance per clock, the 45% overall boost translates into a much larger 26% increase in IPC which is nearer to what we had expected.
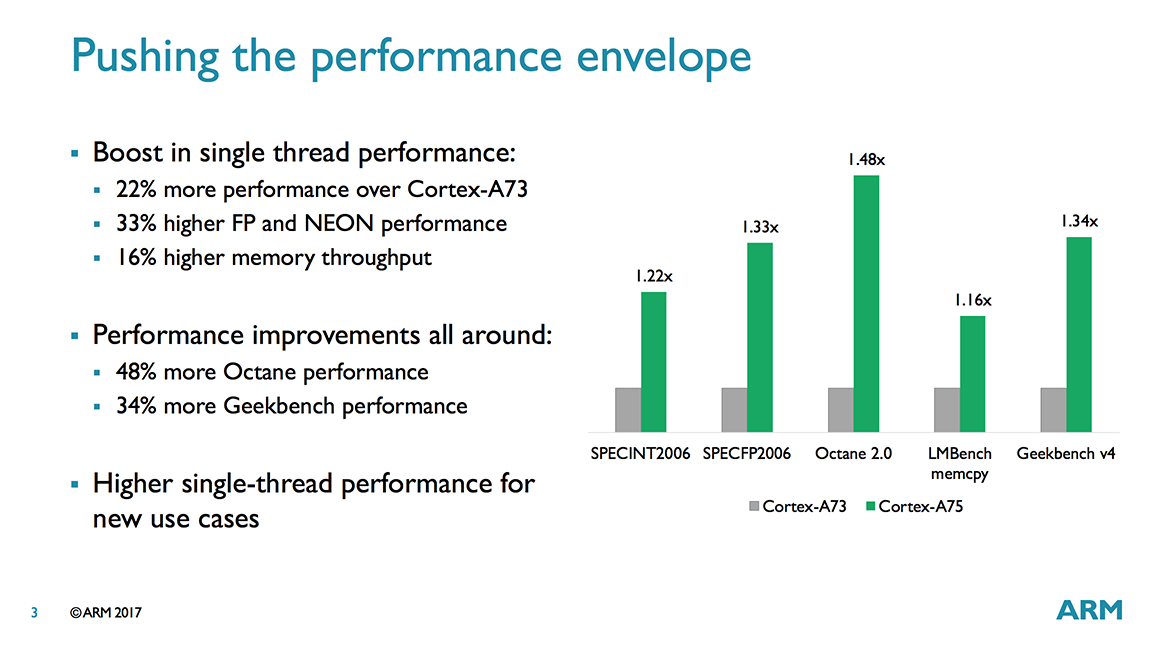
Revisiting the performance claims from ARM’s TechDay release of the A75 we notice that we had been promised larger improvements such as up to a 34% increase in GB4 performance per clock, which I interpreted with the frequency increase of the Snapdragon 845 to result in a 52% overall increase, which did not materialise. I reached out to ARM on the topic and got back several points of consideration: The projections ARM published were made on a A75 simulation with 512KB L2 caches and 2MB L3. The L3 matches the configuration of the Snapdragon 845 however Qualcomm’s choice of going with smaller L2 caches will have a certain performance hit. ARM didn’t have a number at hand for GB4 but quotes a 2% performance degradation for SPEC2000, and claims for GB4 it should be lower. Another consideration point is the memory subsystem of the SoC which ARM can’t control but heavily impacts the performance of the CPU, so let’s have a look at that.
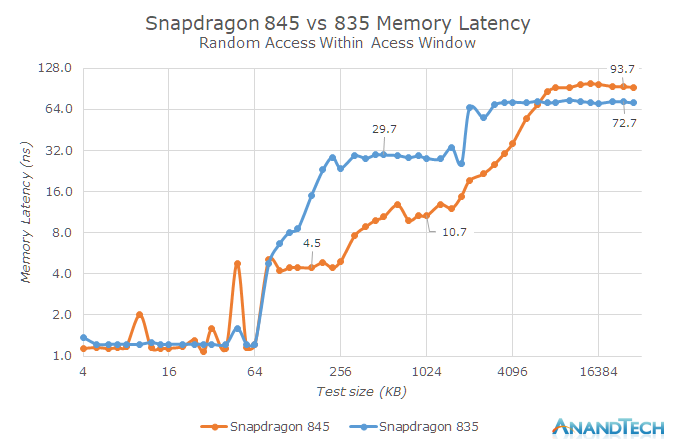
Running our internal memory benchmark on the QRD we see several expected characteristics of the Snapdragon 845: Compared to the Snapdragon 835’s A73 based cores we see the shift from shared cluster L2’s to private ones as well as the integration of sort of an L3 and L4 cache. The new L2 caches are very visible in our benchmark as memory latency up to the 256KB barrier (or rather, the 320KB barrier as the L1D and L2 are exclusive) sees a vast reduction compared to the L2 region of the A73 cores. The A75 cores promise 8-cycle hits for the L2 versus 19 cycles on the A73. In our test the difference is far larger as see a reduction from ~30ns down to ~4.5ns (not forgetting a clock frequency increase of the new cache). After the 256/320KB test size boundary we enter the DSU’s L3 cache. ARM describes the L3 as pseudo-exclusive so the outer boundary should end around or shortly after the 2048KB mark, the transition here is much harder to make out in the limited data we had time to collect so hopefully we’ll get to revisit it on a commercial device.
On the Snapdragon 835 the transition between L2 cache and DRAM is very sharp and visible in the graph. On the Snapdragon 845 however we see a far more gradient latency transition stretching out to up to the 5MB test depth. This is confirmation that Qualcomm’s system cache is indeed applied to the CPU subsystem and acts as an exclusive L4 cache to the processors. I think this new system cache is a true SoC-wide cache lying high up at the interconnect or memory controller level.
One of the worries of such a configuration for the CPU subsystem was increased latency to DRAM and it seems my fears were realised as the Snapdragon 845 shows a 30% increase in main memory latency from the CPU subsystem. Previously the Snapdragon 835 seemed to have by far one of the best memory controller implementations which directly resulted in higher performance of memory latency sensitive workloads. The latency increase in the 845 thus must be counteracting some of the microarchitectural improvements on part of the CPU cores. For GB4 in particular I made a remark that I didn’t notice any performance impact at all on the part of the Kirin 970’s memory latency, however we’re talking about different platforms and CPUs so I can’t be certain.
We reserve final conclusion on synthetic benchmarks until we get more time with a Snapdragon 845 device and able to investigate more and run SPEC. For now it looks like the Snapdragon 845 does not reach ARM’s projected performance levels, and falls well short of the claims. Among one of the other performance claims was Octane. We retired Octane some years ago and Google shortly followed up with official retirement, but as an added data-point the Snapdragon 845 reached a score of 15969 versus the Snapdragon 835’s 11879, also well short of a 20000 target that a projected 1.48x per clock performance increase would have resulted in.








140 Comments
View All Comments
Eximorph - Sunday, February 18, 2018 - link
You should read a little before post comments. The speed of the gpu depends on the api Thats why apple change from open gl es to metal beacus metal is a low overhead so the performance is higher. And thats why when some one test a gpu have to do it under fair conditions and thats where 3Dmark is good. And like you can see even the adreno 530 on the same api have a better performance than the A11 gpu. Even on t-rex onscreen the performance of the new A11 gpu is the same has the adreno 530. 59 for A11, 60 for the adreno 530 on the oneplus 3t. one more time, apple today day Is almost 3 years behind. Vulkan is have been you in some game today day but you want to know whats the funny thing here, vulkan is on version 1 and offer the same persomance has metal and metal is on version 2 hahahah.Ratman6161 - Thursday, February 15, 2018 - link
"Good on Qualcomm for catching up but still 6 months to a year behind"I guess it depends how you define behind. With my trusty old (and completely paid for) Note 5, I have had a phone since 2015 that is plenty fast for everything I do. Do its all just academic for me. The days when I needed a faster CPU are long since over.
SoC lover - Friday, March 2, 2018 - link
A-11 bionic is just only 6 cores but still a flagship and powerful while snapdragon 835/845 has 8 cores so im thinking what if apple make a new chipset with 8 cores thats would be soo powerfulmfaisalkemal - Monday, February 12, 2018 - link
i think why anandtech got that score because of the device run on cold condition. score from futuremark got from normal condition.BenSkywalker - Monday, February 12, 2018 - link
We really should tip our hats to Qualcomm's legal team for this one. It is amazing their engineers have managed to push out a GPU that can edge out the Tegra X1 a mere three years after it came out.Slingshot Ex- 5360 graphics on a three year old SoC. Really shows how what truly matters in this market is top tier lawyers, and some fourth tier engineers.
Andrei Frumusanu - Monday, February 12, 2018 - link
One uses ~12 watts and the other uses ~4W, great comparison there.BenSkywalker - Monday, February 12, 2018 - link
Two things, one is that your power numbers are going to have to be sourced, the highest number I could ever find was 10 watts(and that was using a UE4 torture test). The only power draw numbers I could find for Manhattan had is sucking down a whopping 1.51 watts for the GPU(just the GPU and clocked to match some crappy Apple SoC's performance).https://www.anandtech.com/show/8811/nvidia-tegra-x...
Second thing- 20nm vs 10nm. On an engineering basis, this is a sad part. Qualcomm's legal posturing is the only reason they are remotely viable.
We are being held back to a staggering degree because of Qualcomm's strong arm tactics. The performance numbers speak for themselves, they are years behind.
Andrei Frumusanu - Monday, February 12, 2018 - link
That's the power on a Shield TV at maximum performance; source me. You're claiming that QC only reached now performance level so it's only fair to compare power at that level.Qualcomm is the one far ahead, your conspiracy theories make no sense.
BenSkywalker - Monday, February 12, 2018 - link
You are comparing the power draw of an entire device to the SoC alone, and you are comparing a 20nm part to a 10nm part on your just plain wrong power numbers.I linked it- running Manhattan the x1's GPU was using less then half the power that the 845 was reporting- the comparison wasn't exactly fair as they weren't measuring the same thing, but it is closer to accurate then what you are trying to imply. Also, 20nm vs 10nm LPP- are you being intentionally obtuse here, or do you not have a clue what you are talking about whatsoever?
This part, at least on the GPU end, isn't just bad, it is pathetic. It can barely edge out a three year old SoC. It is a joke.
darkd - Monday, February 12, 2018 - link
The x1 by itself is a 10-12W TDP part. You can Google this easily. Qualcomm SoCs are 4-5W typically. Also note you are comparing power draw at 33 fps of a different benchmark that runs ~40% faster (Manhattan 3.0 vs. 3.1), which makes no sense.The x1 at peak can hit ~60 fps on Manhattan 3.0. The 835 from last year can also do that, but at 2-3x less power.
If you want to talk the ~33 fps on Manhattan 3.0 where the 1.5W you mentioned was measured, then the Adreno 430 can do that about 3 years ago. Because that's peak clocks for the 430 it would likely be using 2+ W GPU power, which is more. The x1 was more power efficient than the 430, congrats. It hasn't been since then, however, as Qualcomm improved their Manhattan score 60-70% in 530. All of these number are easily obtained on gfxbench.com.
And I dunno what legal study you've done, but to imply Qualcomm lawyers can keep OEMs from using competitor SoCs is completely unfounded. Many of them have and do use other SoCs. They tend not to use Nvidia for mobile anymore, however, as the recent Nvidia parts all have too high a TDP.